Históricamente, muchas empresas usan Mixpanel para la analítica de producto y entender el recorrido de cada usuario. Sin embargo, cuando el producto despega y el volumen de eventos crece, Mixpanel puede salir bastante caro. En este artículo repasamos uno de nuestros proyectos con Jelly Button, en el que diseñamos su propia solución de analítica de eventos sobre Google Cloud Platform de forma muy eficiente y que les permitirá ahorrar cerca de un cuarto de millón de dólares al año.
Jelly Button Games desarrolla y publica juegos interactivos para móvil y web. Fue fundada en 2011 y su título insignia es Pirate Kings, donde los jugadores compiten contra sus amigos por conquistar islas exóticas, acumular oro y convertirse en el señor de los siete mares en lo que Jelly Button Games define como una experiencia "mingle-player". Lanzado en 2014, el juego acumula cerca de 70 millones de descargas entre iOS, Android y Facebook.
En DoiT International ayudamos a las startups a diseñar, construir y operar soluciones de datos sumamente robustas sobre Google Cloud Platform y Amazon Web Services. Junto al equipo de Jelly Button liderado por Meir Shitrit y Nir Shney-Dor, construimos un pipeline de datos global, robusto y seguro que procesa y almacena millones de eventos por hora.
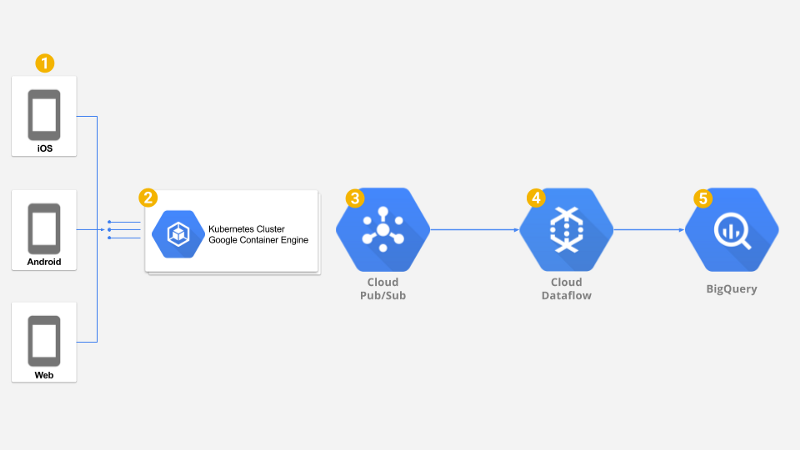
Como base de la solución utilizamos la Arquitectura de Referencia de Google para Analítica de Juegos Móviles.
Arquitectura de Referencia de Google para Analítica de Juegos Móviles
Los requisitos
Jelly Button desarrolla juegos a los que juegan más de 70 millones de personas desde sus smartphones. Cada jugador envía eventos relacionados con la partida al backend de analítica. Esos eventos deben almacenarse para procesarlos y analizarlos más adelante. Jelly Button usa estos datos para analítica de juegos, investigación y marketing.
El backend tiene que mantener una latencia muy baja para que la app móvil espere lo mínimo posible al enviar los eventos, y a la vez procesar la mayor cantidad de eventos por segundo. Dicho esto, los datos de eventos son críticos y no se puede tolerar ninguna pérdida.
Por último, los datos deben quedar disponibles para análisis lo antes posible, y los millones de eventos que llegan cada hora no pueden complicar los análisis más complejos.
La solución
Desde el inicio quedó claro que la mejor herramienta para almacenar y analizar este tipo de datos era Google BigQuery: ofrece almacenamiento prácticamente ilimitado, consultas ultrarrápidas y un mecanismo de ingesta integrado que permite insertar hasta 100K registros por segundo por tabla.
Por otro lado, necesitábamos una infraestructura de backend rápida, global y robusta que se escalara automáticamente para sostener una baja latencia con millones de usuarios, o que se redujera para minimizar el costo. Optamos por Google Container Engine (GKE), un cluster de Kubernetes gestionado.
Con Kubernetes montamos un backend muy eficiente, desplegado como cluster federado: uno en Estados Unidos y otro en Europa, ambos atendiendo el tráfico de un único Google HTTP/S Load Balancer global con geolocalización integrada, lo que se traduce en una latencia mínima para los clientes móviles.
Otro reto era retransmitir los eventos recibidos por el backend y almacenarlos de forma confiable en Google BigQuery. Para no comprometer la baja latencia del backend, optamos por Google Cloud Pub/Sub. Pub/Sub nos da un canal de mensajería muy rápido, sin límite de tasa, con entrega garantizada a nivel mundial y hasta 7 días de persistencia de mensajes.
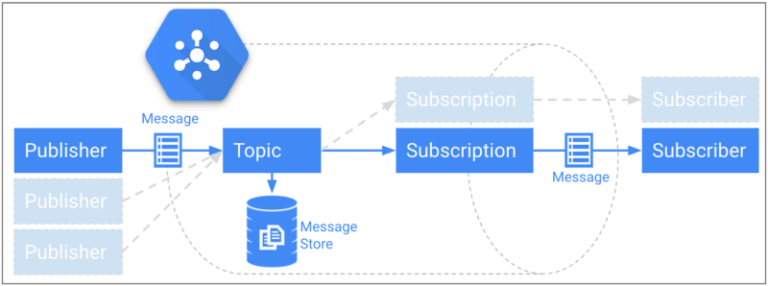
Modelo publish-subscribe de Cloud Pub/Sub con almacenamiento persistente
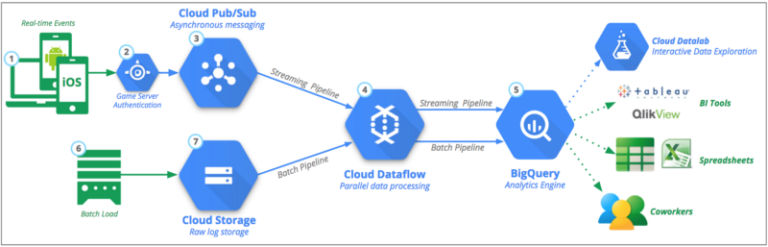
El último componente que necesitábamos era un ETL capaz de manejar el gran volumen de mensajes que llegan desde Google PubSub y aplicar filtrado, mapeo y agregaciones sobre los datos crudos antes de almacenarlos en Google BigQuery para su análisis. Por suerte, Google Dataflow ofrece un cluster de workers totalmente gestionado capaz de ejecutar nuestro ETL en modo streaming, resolviendo estas transformaciones y agregaciones casi en tiempo real y dejando los datos disponibles para análisis prácticamente al instante.
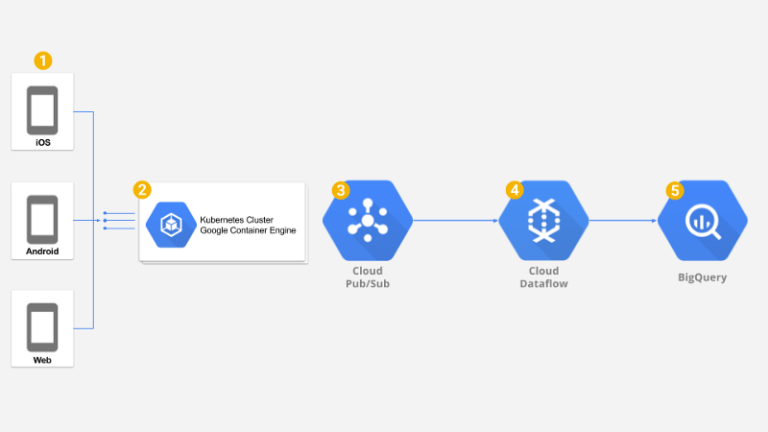
Visión general de la solución
Kubernetes
En nuestro setup, cada pod contiene dos contenedores: uno con nginx y otro con nodejs que ejecuta el código del backend.
El código del backend es, en esencia, un servidor sencillo basado en nodejs.
https://gist.github.com/spark2ignite/d9e927f589f2b3b998988b913ee27dc4
El backend simplemente agrega algo de metadata y reenvía el payload junto con esa información a Google PubSub. No hace ningún trabajo extra para no comprometer la baja latencia.
El servicio desplegado se escala automáticamente con el Horizontal Pod Autoscaler de Kubernetes.
https://gist.github.com/spark2ignite/26a9fbeeea279394730ac39b9c1b1df1
El cluster también se autoescala con Google Container Engine Node Autoscaler, así que los nodos suben y bajan de forma automática.
Google Cloud Dataflow
Casi toda la lógica de transformación y agregación se ejecuta dentro del pipeline de Dataflow. Así corre de forma asíncrona y no bloqueante, aprovechando el cluster de cómputo distribuido de Dataflow.
El pipeline básico parsea los mensajes que llegan desde Google PubSub e incrusta algunos campos en columnas de BigQuery, mientras conserva el resto de los datos como un objeto json guardado en BigQuery en una columna de tipo string.
https://gist.github.com/spark2ignite/a833f04c98d38c11a7398967835c9317
Para sumar funcionalidad, por lo general basta con editar la clase Mapping correspondiente.
https://gist.github.com/spark2ignite/35b78bb689060eb630468e0e8616b70f
Presta atención a esta línea:
options.setStreaming(true);Es la que arranca el pipeline de Dataflow en modo streaming. No se detiene hasta que lo detengas manualmente y sigue procesando los mensajes a medida que llegan a Google Pub/Sub, casi en tiempo real.
Costos
Jelly Button arrancó este camino de construir su propio pipeline de datos para reducir los costos de Mixpanel y contar con una analítica más flexible.
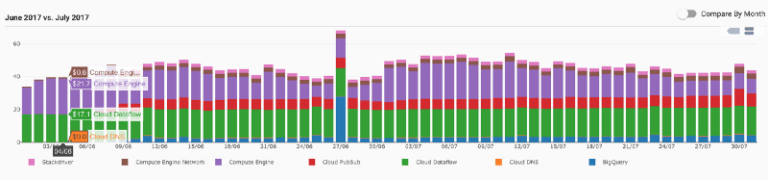
Durante julio de 2017, nuestro nuevo pipeline de analítica procesaba unos 500 eventos por segundo. Este es el resumen de nuestros costos en Google Cloud Platform:
- Cerca de USD 500 en Google Cloud Dataflow
- Cerca de USD 500 en Google Container Engine
- Cerca de USD 200 en Google Pub/Sub
- Cerca de USD 100 en Google BigQuery
Jelly Button monitorea y controla sus costos de Google Cloud Platform con DoiT Cloud Intelligence™. Así luce el gasto promedio diario de Jelly Button:
Resumen
Todo el proyecto nos tomó cerca de 5 semanas. Dedicamos bastante tiempo junto a Jelly Button a diseñar la arquitectura de la solución, armar una prueba de concepto y, finalmente, codificarla y probarla con tráfico real. Lleva ya un par de meses corriendo en producción y estamos seguros de que hoy Jelly Button cuenta con un pipeline de analítica robusto para acompañar a los millones de personas que se sumarán a jugar Pirate Kings y los próximos títulos de la compañía.