De nombreuses entreprises s'appuient traditionnellement sur Mixpanel pour leurs analyses produit afin de comprendre le parcours de chaque utilisateur. Mais lorsqu'un produit rencontre le succès et que le volume d'événements explose, Mixpanel peut vite devenir onéreux. Dans cet article, retour sur l'un de nos projets avec Jelly Button : la conception d'une solution d'analyse d'événements sur Google Cloud Platform, à la fois efficace et capable de générer près d'un quart de million de dollars d'économies par an.
Jelly Button Games développe et publie des jeux interactifs pour mobile et web. Fondée en 2011, l'entreprise est connue pour son titre phare Pirate Kings, dans lequel les joueurs s'affrontent entre amis pour conquérir des îles exotiques, amasser de l'or et devenir les maîtres des mers, dans une expérience que Jelly Button Games qualifie de mingle-player. Lancé en 2014, le jeu cumule environ 70 millions de téléchargements sur iOS, Android et Facebook.
Chez DoiT International, nous accompagnons les startups dans la conception, la construction et l'exploitation de solutions de données robustes basées sur Google Cloud Platform et Amazon Web Services. Aux côtés de l'équipe de Jelly Button menée par Meir Shitrit et Nir Shney-Dor, nous avons bâti un pipeline de données mondial, robuste et sécurisé, capable de traiter et de stocker des millions d'événements chaque heure.
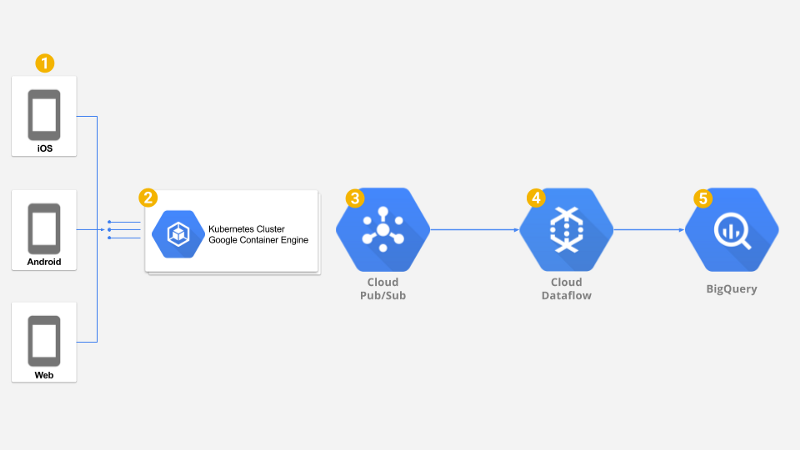
Nous nous sommes appuyés sur l'architecture de référence Google pour l'analyse de jeux mobiles comme socle de notre solution.
Architecture de référence Google pour l'analyse de jeux mobiles
Les besoins
Jelly Button développe des jeux auxquels jouent plus de 70 millions de personnes depuis leur smartphone. Chaque joueur transmet au backend analytique des événements liés au jeu. Ces événements doivent être stockés en vue d'un traitement et d'une analyse ultérieurs. Jelly Button exploite ces données pour l'analyse de jeu, la recherche et le marketing.
Ce backend doit conserver une latence très faible afin que l'application mobile patiente le moins possible lors de l'envoi des événements, tout en traitant un maximum d'événements par seconde. Cela dit, ces données sont critiques et aucune perte ne peut être tolérée.
Enfin, les données d'événements doivent être disponibles pour analyse dans les meilleurs délais, et les millions d'événements reçus chaque heure ne doivent pas freiner les analyses complexes.
La solution
Dès le départ, l'évidence s'est imposée : le meilleur outil pour stocker et analyser ce type de données est Google BigQuery, avec son stockage quasi illimité, ses requêtes ultra-rapides et son mécanisme d'ingestion intégré qui permet d'insérer jusqu'à 100 000 enregistrements par seconde et par table.
Restait à mettre en place une infrastructure backend rapide, mondiale et robuste, capable de monter en charge automatiquement pour assurer une faible latence à des millions d'utilisateurs, ou de redescendre pour limiter les coûts au minimum. Notre choix s'est porté sur Google Container Engine (GKE), un cluster Kubernetes managé.
Avec Kubernetes, nous avons mis en place un backend très efficace déployé en cluster fédéré — un cluster aux États-Unis et un autre en Europe, tous deux servant le trafic via un unique Google HTTP/S Load Balancer mondial à géolocalisation intégrée, garantissant ainsi une latence minimale aux clients mobiles.
Autre défi : relayer les événements reçus par le backend et les stocker de façon fiable dans Google BigQuery. Pour préserver la faible latence du backend, nous avons opté pour Google Cloud Pub/Sub. Pub/Sub offre un canal de messagerie très rapide, sans limite de débit, avec une livraison mondiale garantie et jusqu'à 7 jours de persistance des messages.
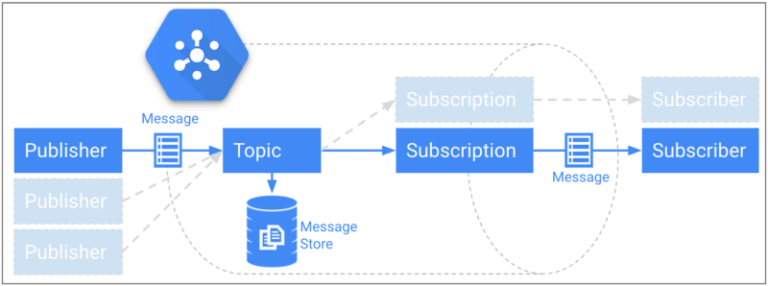
Modèle publish/subscribe de Cloud Pub/Sub avec stockage persistant
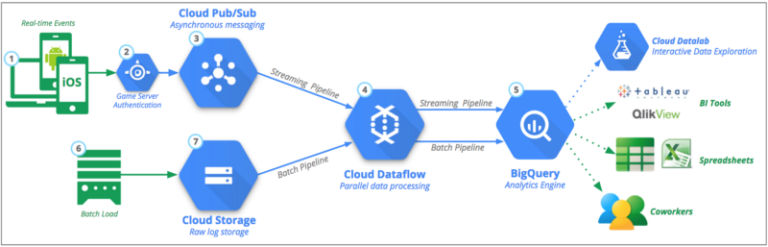
Le dernier composant nécessaire était un ETL capable d'absorber le volume considérable de messages issus de Google PubSub et d'effectuer filtrage, mapping et agrégations sur les données brutes avant leur stockage dans Google BigQuery pour analyse. Heureusement, Google Dataflow fournit un cluster de workers entièrement managé qui peut exécuter notre ETL en mode streaming et gérer ces transformations et agrégations en quasi temps réel, rendant les données disponibles à l'analyse quasi instantanément.
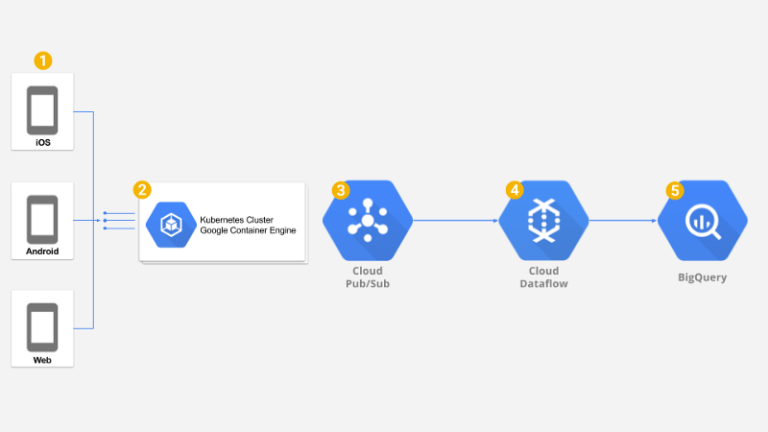
Vue d'ensemble de la solution
Kubernetes
Dans notre configuration, chaque pod contient deux containers : un container nginx et un container nodejs avec le code du backend.
Le code du backend se résume à un simple serveur basé sur nodejs.
https://gist.github.com/spark2ignite/d9e927f589f2b3b998988b913ee27dc4
Le backend se contente d'ajouter quelques métadonnées et de transmettre la charge utile à Google PubSub. Aucun traitement supplémentaire n'est effectué à ce stade, afin de préserver une faible latence.
Le service déployé est mis à l'échelle automatiquement via le Horizontal Pod Autoscaler de Kubernetes.
https://gist.github.com/spark2ignite/26a9fbeeea279394730ac39b9c1b1df1
Le cluster lui-même est également autoscalé via le Google Container Engine Node Autoscaler, ce qui permet d'ajouter ou de retirer des nœuds automatiquement.
Google Cloud Dataflow
L'essentiel de la logique de transformation et d'agrégation s'exécute au sein du pipeline Dataflow. Ces opérations tournent ainsi de manière asynchrone et non bloquante, en s'appuyant sur le cluster de calcul distribué de Dataflow.
Le pipeline de base se contente d'analyser les messages issus de Google PubSub et d'extraire certains champs vers des colonnes BigQuery, tout en conservant le reste des données sous forme d'objet json stocké dans une colonne string de BigQuery.
https://gist.github.com/spark2ignite/a833f04c98d38c11a7398967835c9317
Pour ajouter des fonctionnalités, il suffit généralement de modifier la classe Mapping concernée.
https://gist.github.com/spark2ignite/35b78bb689060eb630468e0e8616b70f
Notez bien la ligne :
options.setStreaming(true);C'est elle qui lance le pipeline Dataflow en mode streaming. Il ne s'arrêtera qu'à la demande explicite et continuera de traiter les messages au fil de leur arrivée dans Google Pub/Sub, en quasi temps réel.
Coûts
Jelly Button s'est lancé dans la construction de son propre pipeline de données pour réduire les coûts liés à Mixpanel et bâtir une plateforme analytique plus flexible.
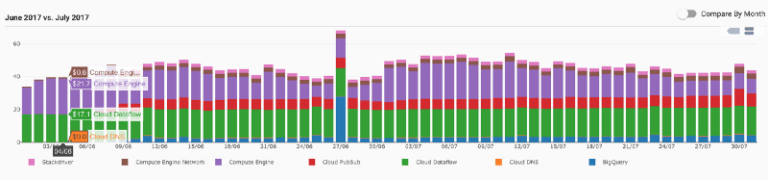
En juillet 2017, notre nouveau pipeline traitait environ 500 événements par seconde. Voici le récapitulatif de nos coûts sur Google Cloud Platform :
- Environ 500 $ pour Google Cloud Dataflow
- Environ 500 $ pour Google Container Engine
- Environ 200 $ pour Google Pub/Sub
- Environ 100 $ pour Google BigQuery
Jelly Button suit et maîtrise ses coûts Google Cloud Platform avec DoiT Cloud Intelligence™. Voici à quoi ressemble sa dépense quotidienne moyenne :
En résumé
Le projet a été bouclé en environ 5 semaines. Nous avons passé un temps conséquent aux côtés de Jelly Button pour concevoir l'architecture, bâtir un proof of concept, puis coder et tester l'ensemble avec du trafic réel. La solution tourne en production depuis quelques mois et nous avons la conviction que Jelly Button dispose désormais d'un pipeline analytique robuste, à la hauteur des nouveaux millions de joueurs de Pirate Kings et des prochains titres à venir.