Viele Unternehmen setzen bei Produktanalysen klassisch auf Mixpanel, um die Journey jedes Nutzers nachzuvollziehen. Wird das Produkt jedoch zum Erfolg und das Event-Volumen wächst, kann Mixpanel schnell teuer werden. In diesem Beitrag zeigen wir eines unserer Projekte mit Jelly Button: Wir haben eine eigene, hocheffiziente Event-Analytics-Lösung auf Basis der Google Cloud Platform entworfen – und sparen Jelly Button damit jährlich rund eine Viertelmillion Dollar.
Jelly Button Games entwickelt und veröffentlicht interaktive Mobile- und Web-Games. Das 2011 gegründete Unternehmen ist vor allem für seinen Flaggschiff-Titel Pirate Kings bekannt: Spieler messen sich darin mit Freunden, erobern exotische Inseln, häufen Gold an und werden zum Herrscher der Weltmeere – Jelly Button Games selbst nennt das eine "mingle-player"-Erfahrung. Seit dem Launch 2014 wurde das Spiel rund 70 Millionen Mal auf iOS, Android und Facebook heruntergeladen.
Wir bei DoiT International unterstützen Startups dabei, robuste Datenlösungen auf Google Cloud Platform und Amazon Web Services zu konzipieren, aufzubauen und zu betreiben. Gemeinsam mit dem Team von Jelly Button rund um Meir Shitrit und Nir Shney-Dor haben wir eine globale, robuste und sichere Data-Pipeline aufgebaut, die stündlich Millionen Events verarbeitet und speichert.
Als Grundlage diente uns die Reference Architecture for Mobile Gaming Analytics von Google.
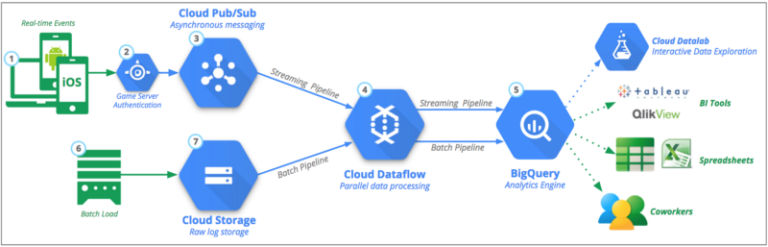
Google Reference Architecture for Mobile Gaming Analytics
Die Anforderungen
Jelly Button entwickelt Games, die von über 70 Millionen Menschen auf ihren Smartphones gespielt werden. Jeder Spieler sendet spielbezogene Events an das Analytics-Backend. Diese Events müssen für die spätere Verarbeitung und Auswertung gespeichert werden. Jelly Button nutzt diese Daten für Game-Analytics, Research und Marketing.
Das Backend muss eine sehr niedrige Latenz halten, damit die Mobile-App beim Senden dieser Events kaum warten muss – und es muss gleichzeitig so viele Events pro Sekunde wie möglich verarbeiten. Dabei sind die Event-Daten geschäftskritisch: Datenverlust ist nicht akzeptabel.
Schließlich müssen die Event-Daten so schnell wie möglich für die Analyse verfügbar sein, und die Millionen Events, die stündlich eingehen, dürfen komplexe Auswertungen nicht ausbremsen.
Die Lösung
Von Anfang an war klar: Das beste Werkzeug, um diese Art von Daten zu speichern und zu analysieren, ist Google BigQuery. Es bietet praktisch unbegrenzten Speicher, blitzschnelle Queries und einen integrierten Ingestion-Mechanismus, mit dem sich pro Tabelle bis zu 100.000 Datensätze pro Sekunde einfügen lassen.
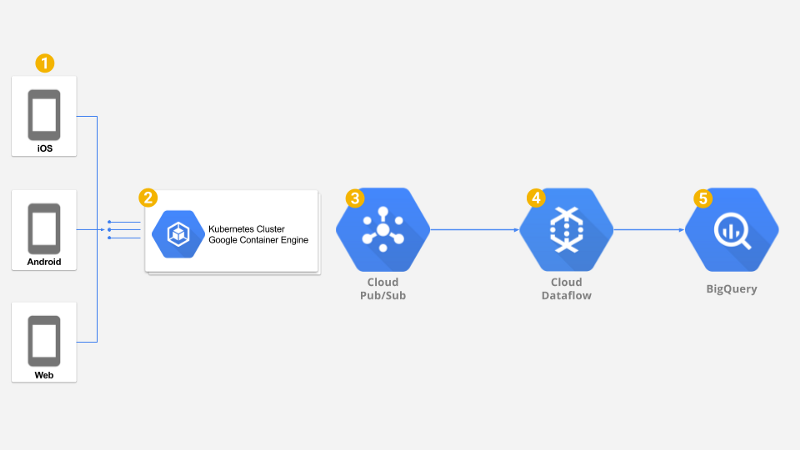
Außerdem brauchten wir eine schnelle, globale und robuste Backend-Infrastruktur, die sich automatisch hochskalieren lässt, um niedrige Latenzen für Millionen Nutzer zu liefern – und ebenso herunterskaliert, um die Kosten minimal zu halten. Wir haben uns für die Google Container Engine (GKE) entschieden, ein Managed-Kubernetes-Cluster.
Mit Kubernetes konnten wir ein sehr effizientes Backend aufsetzen, das als föderiertes Cluster betrieben wird – ein Cluster in den USA und ein weiteres in Europa. Beide bedienen Traffic eines einzigen globalen Google HTTP/S Load Balancers mit eingebauter Geo-Awareness und sorgen so für minimale Latenz auf Client-Seite.
Eine weitere Herausforderung war es, die im Backend eingehenden Events zuverlässig nach Google BigQuery weiterzureichen. Um die niedrige Latenz des Backends zu erhalten, haben wir uns für Google Cloud Pub/Sub entschieden. Pub/Sub bietet einen sehr schnellen Messaging-Layer mit unbegrenzter Rate, garantierter weltweiter Zustellung und einer Nachrichten-Persistenz von bis zu sieben Tagen.
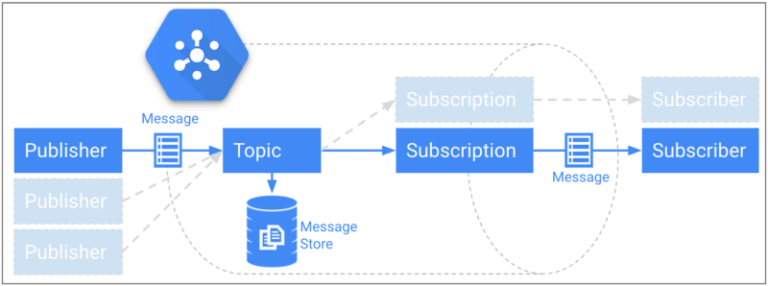
Cloud Pub/Sub Publish-Subscribe-Modell mit persistentem Speicher
Die letzte Komponente war ein ETL, das die großen Mengen an Nachrichten aus Google PubSub verarbeitet und auf den Rohdaten Filterung, Mapping und Aggregation ausführt, bevor sie zur Analyse in Google BigQuery landen. Praktischerweise bietet Google Dataflow ein vollständig verwaltetes Worker-Cluster, das unser ETL im Streaming-Modus ausführt – Transformationen und Aggregationen erfolgen nahezu in Echtzeit, sodass die Daten praktisch sofort für die Analyse bereitstehen.
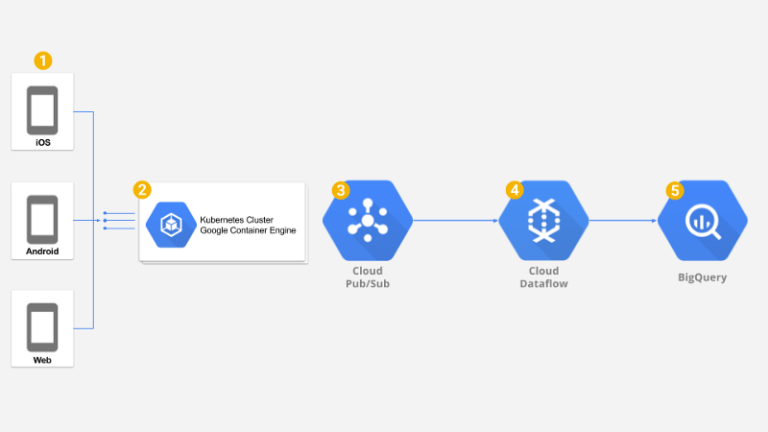
Lösungsüberblick
Kubernetes
In unserem Setup enthält jeder Pod zwei Container: einen nginx-Container und einen Node.js-Container mit dem Backend-Code.
Der Backend-Code ist im Kern ein einfacher Server auf Node.js-Basis.
https://gist.github.com/spark2ignite/d9e927f589f2b3b998988b913ee27dc4
Das Backend reichert den Payload lediglich um etwas Metadaten an und schickt beides an Google PubSub. Mehr passiert hier nicht – damit die Latenz niedrig bleibt.
Der ausgerollte Service skaliert automatisch über den Horizontal Pod Autoscaler von Kubernetes.
https://gist.github.com/spark2ignite/26a9fbeeea279394730ac39b9c1b1df1
Das Cluster selbst skaliert ebenfalls automatisch – über den Google Container Engine Node Autoscaler. Nodes werden also automatisch hoch- und heruntergefahren.
Google Cloud Dataflow
Der Großteil der benötigten Transformations- und Aggregationslogik läuft innerhalb der Dataflow-Pipeline. So lässt sich die Verarbeitung asynchron und non-blocking auf dem verteilten Compute-Cluster von Dataflow ausführen.
Die Basis-Pipeline parst die aus Google PubSub eingehenden Nachrichten und mappt einzelne Felder direkt auf BigQuery-Spalten, während die übrigen Daten als JSON-Objekt in einer String-Spalte in BigQuery abgelegt werden.
https://gist.github.com/spark2ignite/a833f04c98d38c11a7398967835c9317
Um zusätzliche Funktionalität zu ergänzen, reicht in der Regel eine Anpassung der entsprechenden Mapping-Klasse.
https://gist.github.com/spark2ignite/35b78bb689060eb630468e0e8616b70f
Beachten Sie dabei diese Zeile:
options.setStreaming(true);Damit startet die Dataflow-Pipeline im Streaming-Modus. Sie läuft, bis sie manuell gestoppt wird, und verarbeitet eingehende Nachrichten aus Google Pub/Sub kontinuierlich nahezu in Echtzeit.
Kosten
Jelly Button hat den Aufbau einer eigenen Data-Pipeline angestoßen, um die Mixpanel-Kosten zu senken und zugleich eine flexiblere Analytics-Pipeline zu bekommen.
Im Juli 2017 verarbeitete unsere neue Data-Analytics-Pipeline rund 500 Events pro Sekunde. Hier eine Zusammenfassung unserer Kosten auf der Google Cloud Platform:
- Rund 500 $ für Google Cloud Dataflow
- Rund 500 $ für Google Container Engine
- Rund 200 $ für Google Pub/Sub
- Rund 100 $ für Google BigQuery
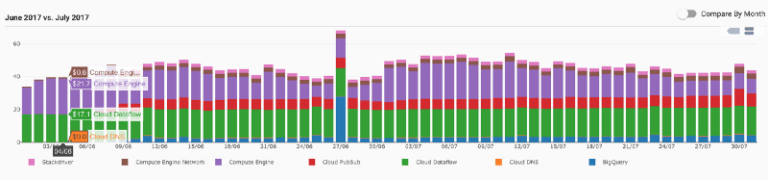
Jelly Button überwacht und steuert seine Kosten auf der Google Cloud Platform mit DoiT Cloud Intelligence™. So sehen die durchschnittlichen Tagesausgaben von Jelly Button aus:
Fazit
Das gesamte Projekt haben wir in rund fünf Wochen umgesetzt. Wir haben viel Zeit gemeinsam mit Jelly Button investiert, um die Lösung zu konzipieren, einen Proof of Concept zu bauen und sie schließlich zu implementieren und mit echtem Traffic zu testen. Sie läuft inzwischen seit einigen Monaten in Produktion – und wir sind überzeugt: Mit dieser robusten Analytics-Pipeline ist Jelly Button bestens aufgestellt für viele weitere Millionen Spieler von Pirate Kings und kommenden Titeln.