DoiT Internationalでは、コスト効率と運用の卓越性を常に追求しています。そんな私たちにとって、K8s-Cluster Autoscalerに「Priority」エキスパンダーが追加されたのは大きな朗報でした。これにより、ノードプールのオートスケーリング判断に優先順位ルールを設定できるようになり、ステートレスなworkloadsについてSpotインスタンスのノードグループからオンデマンドノードグループへフォールバックさせる仕組みを構築できます。本記事では、この機能をAWS EKS上のK8sクラスターで活用する方法を、簡単なガイドとしてご紹介します。
Autoscalerやエキスパンダーについてすでにご存知の方は、デモのセクションまで読み飛ばしていただいて構いません。
Cluster Autoscaler
Cluster Autoscalerとは?
「Cluster Autoscalerは、現在のニーズに合わせてKubernetesクラスターのサイズを調整するスタンドアロンのプログラムです。」
このスタンドアロンプログラムは、K8sクラスター内のworkloadsと並行して動作します。metrics-server(クラスター全体のリソース使用状況を集約するコンポーネント)と通信して必要なキャパシティを算出し、クラウドプロバイダーのAPIを呼び出してクラスターへキャパシティを追加(または削除)します。Cluster Autoscalerは、クラスターに追加するキャパシティの種類を選ぶためのロジックを複数備えており、これらはエキスパンダーと呼ばれます。
エキスパンダーとは?
現在、Cluster Autoscalerには5種類のエキスパンダーが実装されています。
random- デフォルトのエキスパンダーです。ノードグループごとに異なるスケール挙動を求める特別な事情がない場合に使用します。most-pods- スケールアップ時に最も多くのPodをスケジュールできるノードグループを選びます。nodeSelectorで特定のPodを特定のノードに配置している場合に有効です。なお、これによってAutoscalerが大きなノードを優先するわけではなく、小さなノードを一度に複数追加することもあります。least-waste- スケールアップ後にアイドルCPU(同点の場合は未使用メモリ)が最も少なくなるノードグループを選びます。高CPUや高メモリ向けなど複数のノードクラスがあり、該当リソースを多く必要とするPodがPendingしているときだけ拡張したい場合に有効です。price- コストが最も低く、かつクラスターサイズに合致するマシンを持つノードグループを選びます。詳細はこちらをご覧ください。現時点ではGKEでのみ動作します。priority- ユーザーが割り当てた優先度が最も高いノードグループを選びます。設定方法の詳細はこちらをご覧ください。
本デモでは、「Priority」エキスパンダーを利用して、AutoscalerがまずSpotインスタンスのノードグループのスケールアウトを試み、それが叶わない場合にオンデマンドのノードグループへフォールバックさせる方法をご紹介します。
「price」エキスパンダーが既定となっているGKEクラスターではこれがデフォルト挙動ですが、EKSクラスターでは標準では実現できません。幸い、Cluster Autoscalerバージョン1.14で「Priority」エキスパンダーが追加されたため、ノードグループごとの拡張優先度を自分で設定できるようになりました。
デモ
本デモでは、便利なツールeksctlを使ってEKSクラスターを作成します。Spotインスタンスプールにcapacity-optimizedの割り当て戦略を使用するため、eksctlは必ず0.16.0以上をご利用ください。この戦略はeksctl 0.16.0でサポートが追加されました。
クラスターは2つのノードグループで構成します。1つ目はSpotインスタンスのノードグループで、希望キャパシティ1、最小0、最大10です。2つ目はフォールバック用のオンデマンドノードグループで、希望キャパシティ0、最小0、最大10です。
インスタンスタイプの分散とCapacity-Optimized Spot割り当て戦略 — 可用性を最大化
対象のworkloadsは(理論値で)約1.5 vCPUと7 GBのRAMで快適に動作するため、2つのノードプールにはそれぞれ2 vCPUと8 GBのRAMを提供する複数のEC2インスタンスタイプを混在させました。Cluster Autoscalerが正しく機能するには、1つのプール内のすべてのインスタンスタイプが同じvCPUおよびRAMスペックで構成されていることが必須です。
プールを複数のインスタンスタイプで分散させることで、ノードの可用性が最大化されます。あるインスタンスタイプのキャパシティが不足しても、別のインスタンスタイプで補えるためです。特定タイプのSpotとオンデマンドの両方が枯渇している状況でも、価格は異なるものの他のインスタンスタイプが利用可能になるため、非常に頼りになります。
SpotフリートにCapacity-Optimizedの割り当て戦略を適用すると、利用可能なキャパシティが最も大きいインスタンスタイプファミリーからノードがプロビジョニングされ、中断される確率を最小限に抑えられます。
デモリポジトリをクローンし、ディレクトリへ移動します。
git clone https://github.com/doitintl/eks-spot-to-ondemand-fallback.git && cd eks-spot-to-ondemand-fallback
クラスターを作成します。
eksctl create cluster -f cluster/cluster.yaml
このコマンドにより3つのCloudFormationスタックの作成がトリガーされ、最終的にクラスターのインフラ(EKSコントロールプレーン、2つのAuto Scalingグループ、VPCなど)がセットアップされます。完了するとeksctlがクラスターの準備完了を通知します。
[✔] EKS cluster "my-eks-cluster" in "us-east-1" region is ready
eksctlは新しいクラスター情報でKubeconfigファイルを自動更新するので、すぐにkubectlコマンドを実行できる状態になります。
Metrics-serverをデプロイします。
kubectl apply -f metrics-server/
Autoscaler Priority Expander ConfigMap
ここで、追加キャパシティが必要になった際にAutoscalerがどのノードグループをスケールするかを決める優先度を設定します。ConfigMap名はcluster-autoscaler-priority-expanderでなければならず、Autoscalerと同じNamespaceに作成する必要があります(本デモではCluster Autoscalerのネームスペースとしてkube-systemを使用しています)。
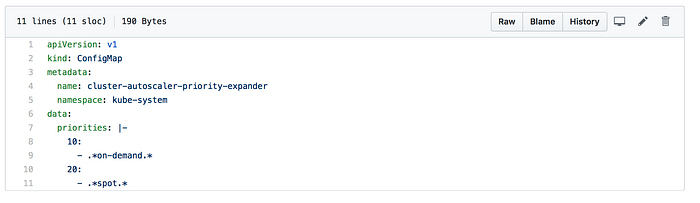
prioritiesデータは、キー(優先度)と値(ノードグループ名にマッチさせる正規表現)の配列です。Cluster Autoscalerが正しく優先順位付けできるよう、ノードグループ名にon-demandとspotという文字列を含めて作成しています。
Autoscaler Priority Expander ConfigMapをデプロイします。
kubectl apply -f 0-autoscaler/
Autoscalerをデプロイします。
まず、Autoscalerの設定ファイルがeksctlで作成されたASGと一致していることを確認します。1-autoscaler/cluster-autoscaler.yamlの157行目と158行目を、ご自身のAWSアカウントで作成された新しいASG名に置き換えてください。EC2のUIから取得するか、以下のAWS CLIコマンドで取得できます。
aws --region=us-east-1 autoscaling describe-auto-scaling-groups | jq '.AutoScalingGroups[]? | "\(.Tags[]|select((.Key=="alpha.eksctl.io/cluster-name") and (.Value=="my-eks-cluster"))|.ResourceId )"'
SPOT(157行目)はSpotインスタンスのASG名に、on-demand(158行目)はオンデマンドインスタンスのASG名に置き換えてください。
その後、Autoscalerをデプロイします。
kubectl apply -f 1-autoscaler/
アプリをデプロイします。
kubectl apply -f app/
現時点のスタックは、アプリのレプリカ1つを稼働させるSpotインスタンスノード1台で構成されています。


このノードがspot-ngノードグループに属していることに注目してください。

ここでDeploymentを1レプリカから2レプリカへスケールすると、現在のノードでは新しいPodをスケジュールできず(PodのCPUリクエストを1200m、ノードは2 vCPUに設定しているため)、Autoscalerが別のノードを起動します。狙い通りであればSpotインスタンスのノードグループからです。
アプリをスケールアップします。
kubectl scale --replicas=2 deployment/php-apache
案の定、新しいPodは既存ノードにスケジュールできずPending状態になっています。

数秒後、新しいノードが追加されます。

このノードもSpotインスタンスのノードグループからプロビジョニングされたか確認しましょう。

このノードがspot-ngノードグループに属していることに注目してください。
Pending状態だったPodは、新しいノードへ無事スケジュールされました。

続いて、Spotインスタンスのノードグループの最大サイズを2に制限したうえでアプリをさらにスケールアップし、新しいオンデマンドインスタンスが追加されて負荷を捌くことを期待してみましょう。

Spotインスタンスのノードグループを最大2インスタンスに制限
アプリを3レプリカへスケールしてみましょう。
kubectl scale --replicas=3 deployment/php-apache
Autoscalerは新しいPodのために追加のノードを必要としますが、Spotインスタンスのグループはすでに上限(先ほど最大2ノードに制限しました)に達しているため、オンデマンドのグループから新しいノードを起動するはずです。
新しいPodが、追加されるノードを待っている状態です。

新しいノードが追加されました。

このノードがどのノードグループに属しているか確認してみましょう。

このノードがon-demand-ngノードグループに属していることに注目してください。
ノードのための、頼れるフォールバックを
ここまで、Spotインスタンスとオンデマンドインスタンスのノードグループを併用するEKSクラスターを構築し、Spotインスタンスのノードグループの拡張を優先する方法を見てきました。
クリーンアップ
eksctl delete cluster -f cluster/cluster.yaml
本記事では、簡潔さを優先してSpotインスタンスの中断ハンドリングやHPAなどいくつかの要素を割愛しましたが、いずれも本番環境を設計する際には欠かせない重要なポイントです。
ご質問があれば、お気軽にコメント欄までお寄せください!