Aqui na DoiT International, buscamos eficiência de custos e excelência operacional. Por isso, ficamos animados com a chegada do expander "Priority" ao Cluster Autoscaler do Kubernetes. Com ele, dá para definir regras de prioridade nas decisões de autoscaling dos node pools e, com isso, criar um mecanismo de fallback de node groups com instâncias Spot para node groups on-demand em workloads stateless. Resolvemos preparar um guia rápido sobre como aproveitar esse recurso em clusters Kubernetes rodando no AWS EKS.
Se você já manja do Autoscaler e dos diferentes tipos de expander, fique à vontade para pular direto para a demonstração.
Cluster Autoscaler
O que é o Cluster Autoscaler?
Esse programa roda junto com seus workloads no cluster Kubernetes, conversa com o metrics-server (um agregador de dados de uso de recursos de todo o cluster), calcula a capacidade necessária e chama a API do provedor de nuvem para provisionar (ou remover) capacidade no cluster Kubernetes. O cluster-autoscaler conta com diferentes lógicas para escolher que tipo de capacidade adicionar ao cluster — essas lógicas são chamadas de Expanders.
O que são Expanders?
Hoje existem cinco Expanders implementados no Cluster Autoscaler:
random- é o Expander padrão e deve ser usado quando você não tem nenhuma necessidade específica de que os node groups escalem de forma diferente.most-pods- escolhe o node group capaz de agendar a maior quantidade de pods ao escalar. É útil quando você usa nodeSelector para garantir que certos pods caiam em certos nós. Vale notar que isso não faz o Autoscaler preferir nós maiores aos menores, já que ele pode adicionar vários nós menores de uma vez.least-waste- escolhe o node group que ficará com menos CPU ociosa (em caso de empate, memória não usada) após o scale-up. É útil quando você tem diferentes classes de nós, por exemplo, com alta CPU ou alta memória, e só quer expandi-los quando há pods pendentes que precisam de muitos desses recursos.price- escolhe o node group que custará menos e, ao mesmo tempo, cujas máquinas se encaixem no tamanho do cluster. Esse expander é detalhado aqui. No momento, funciona apenas no GKE.priority- escolhe o node group com a maior prioridade definida pelo usuário. A configuração é detalhada aqui.
Nesta demonstração, vamos mostrar como usar o expander "Priority" para que o Autoscaler tente, em primeiro lugar, escalar um node group de instâncias Spot e, caso não consiga, faça fallback escalando um node group on-demand.
Embora esse seja o comportamento padrão em clusters GKE, configurados com o expander "price", o mesmo não vale para clusters EKS. Felizmente, com o lançamento do Cluster Autoscaler 1.14, o expander "Priority" foi adicionado e podemos usá-lo para definir a prioridade de expansão entre os diferentes node groups.
Demonstração
Para esta demonstração, vamos criar um cluster EKS com a excelente ferramenta eksctl. Use o eksctl 0.16.0 ou superior, já que vamos adotar a capacity-optimized allocation strategy nos nossos pools de instâncias Spot, cujo suporte foi introduzido nessa versão.
O cluster será composto por dois node groups: o primeiro é o de instâncias Spot, com capacidade desejada de uma instância, mínimo de zero e máximo de 10. O segundo é o node group on-demand de fallback, com capacidade desejada de zero, mínimo de zero e máximo de 10 instâncias.
Diversificação de tipos de instância e Capacity-Optimized Spot Allocation Strategy — maximizando a disponibilidade
Nosso workload precisa de cerca de 1,5 vCPU e 7 GB de RAM para rodar tranquilamente (em teoria), por isso optamos por diversificar os 2 node pools com diferentes tipos de instâncias EC2 que entregam 2 vCPUs e 8 GB de RAM. É obrigatório que todos os tipos de instância de um mesmo pool tenham as mesmas especificações de vCPU e RAM para o cluster-autoscaler funcionar.
Diversificar o pool com diferentes tipos de instância maximiza a disponibilidade dos nós, já que a falta de capacidade de um tipo pode ser compensada pela disponibilidade de outro. Isso ajuda muito em situações em que tanto a capacidade Spot quanto a on-demand de um tipo estão em falta — outros tipos (com preços diferentes) continuarão disponíveis.
Usar a capacity-optimized allocation strategy na nossa frota Spot garante que os nós sejam provisionados a partir da família de instâncias com maior capacidade disponível e, portanto, com a menor probabilidade de interrupção.
Clone o repositório da demo e entre no diretório clonado:
git clone https://github.com/doitintl/eks-spot-to-ondemand-fallback.git && cd eks-spot-to-ondemand-fallback
Crie o cluster:
eksctl create cluster -f cluster/cluster.yaml
Isso vai disparar a criação de três stacks do CloudFormation que, no fim, montam a infraestrutura do cluster (control plane do EKS, dois Auto Scaling Groups, VPC etc.). Quando terminar, o eksctl vai avisar que o cluster está pronto.
[✔] EKS cluster "my-eks-cluster" in "us-east-1" region is ready
O eksctl atualiza automaticamente seu Kubeconfig com as informações do novo cluster, então já dá para rodar comandos kubectl no cluster.
Faça o deploy do Metrics-server:
kubectl apply -f metrics-server/
O ConfigMap do Priority Expander do Autoscaler
É aqui que definimos as prioridades que o Autoscaler vai considerar ao escolher qual node group escalar quando houver necessidade de capacidade adicional. O ConfigMap precisa se chamar cluster-autoscaler-priority-expander e ser criado no mesmo namespace em que o Autoscaler está rodando (no nosso caso, escolhemos o namespace kube-system para o Cluster Autoscaler).
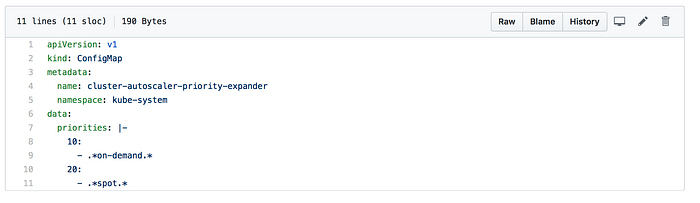
Os dados em priorities formam um array de chaves (prioridade) e valores (regexp para selecionar o nome do node group). Criamos os node groups com as strings on-demand e spot embutidas nos nomes para que o Cluster Autoscaler consiga priorizar corretamente.
Faça o deploy do ConfigMap do Priority Expander:
kubectl apply -f 0-autoscaler/
Faça o deploy do Autoscaler:
Antes de tudo, garanta que o arquivo de configuração do Autoscaler corresponda aos ASGs criados pelo eksctl. Para isso, substitua as linhas 157 e 158 do arquivo 1-autoscaler/cluster-autoscaler.yaml pelos novos nomes dos ASGs criados na sua conta AWS. Você pode pegá-los na UI do EC2 ou usando este comando da AWS CLI.
aws --region=us-east-1 autoscaling describe-auto-scaling-groups | jq '.AutoScalingGroups[]? | "\(.Tags[]|select((.Key=="alpha.eksctl.io/cluster-name") and (.Value=="my-eks-cluster"))|.ResourceId )"'
Substitua a string SPOT (linha 157) pelo nome do ASG das instâncias Spot, e a string on-demand (linha 158) pelo nome do ASG das instâncias on-demand.
Em seguida, faça o deploy do Autoscaler:
kubectl apply -f 1-autoscaler/
Faça o deploy da aplicação:
kubectl apply -f app/
Nossa stack atual agora tem um nó de instância Spot rodando uma réplica da nossa aplicação.


Repare que o node group desse nó é o spot-ng

Agora, se escalarmos nosso deployment de uma para duas réplicas, o nó atual não vai conseguir agendar esse novo pod (definimos o request de CPU em 1200m, enquanto o nó tem 2 vCPU), e o Autoscaler vai provisionar outro nó, idealmente do node group de instâncias Spot.
Escale a aplicação:
kubectl scale --replicas=2 deployment/php-apache
De fato, o novo pod fica em status pending, já que não pode ser agendado no nó disponível.

Depois de alguns segundos, um novo nó é adicionado.

Vamos confirmar que ele também é do node group de instâncias Spot.

Repare que o nodegroup desse nó é o spot-ng
Nosso pod pendente acabou de ser agendado no novo nó.

Agora, vamos restringir o node group de instâncias Spot a um tamanho máximo de duas e escalar a aplicação, esperando que uma nova instância on-demand seja adicionada para dar conta da carga.

Restringindo o node group de instâncias Spot a no máximo duas instâncias
Agora vamos escalar a aplicação para três réplicas:
kubectl scale --replicas=3 deployment/php-apache
O Autoscaler vai precisar de mais um nó para esse novo pod e, como o grupo de instâncias Spot já está na capacidade máxima (lembre que limitamos a no máximo dois nós), ele deve provisionar um novo nó a partir do grupo on-demand.
Um novo pod fica pendente esperando um novo nó.

Um novo nó é adicionado.

Vamos ver qual é o node group desse nó.

Repare que o node group desse nó é o on-demand-ng
O fallback confiável para os seus nós
Vimos como criar um cluster EKS com um node group de instâncias Spot e outro de instâncias on-demand, priorizando a expansão do grupo Spot.
Limpeza
eksctl delete cluster -f cluster/cluster.yaml
Optamos por deixar de fora vários aspectos para manter o exemplo simples, como o tratamento de interrupções de instâncias Spot e o HPA, mas eles são extremamente importantes e devem ser levados em conta no desenho do seu ambiente de produção.
Se tiver alguma dúvida, fique à vontade para deixar nos comentários!