Bei DoiT International haben Kosteneffizienz und operative Exzellenz oberste Priorität. Umso mehr haben wir uns über die Erweiterung um den "Priority"-Expander im Kubernetes Cluster Autoscaler gefreut. Damit lassen sich Prioritätsregeln für Autoscaling-Entscheidungen von Node Pools festlegen – und so ein Fallback-Mechanismus von Spot-Instance-Node-Groups auf On-Demand-Node-Groups für zustandslose Workloads aufbauen. In diesem Beitrag zeigen wir Ihnen kompakt, wie Sie dieses Feature in Kubernetes-Clustern auf AWS EKS einsetzen.
Wenn Sie mit dem Autoscaler und den verschiedenen Expander-Typen bereits vertraut sind, können Sie direkt zur Demo springen.
Cluster Autoscaler
Was ist der Cluster Autoscaler?
Dieses Programm läuft gemeinsam mit Ihren Workloads im Kubernetes-Cluster, kommuniziert mit dem metrics-server (einem clusterweiten Aggregator für Daten zur Ressourcennutzung), berechnet die benötigte Kapazität und ruft die API des Cloud-Anbieters auf, um Kapazität für den Cluster bereitzustellen oder wieder abzubauen. Für die Auswahl der hinzuzufügenden Kapazität stehen im Cluster Autoscaler verschiedene Logiken zur Verfügung – die sogenannten Expander.
Was sind Expander?
Aktuell sind fünf verschiedene Expander für den Cluster Autoscaler implementiert:
random– der Standard-Expander. Geeignet, wenn keine besonderen Anforderungen daran bestehen, wie unterschiedlich Node Groups skaliert werden.most-pods– wählt die Node Group, auf der sich beim Hochskalieren die meisten Pods einplanen lassen. Nützlich, wenn Sie nodeSelector verwenden, damit bestimmte Pods auf bestimmten Nodes landen. Beachten Sie: Der Autoscaler bevorzugt dadurch nicht zwingend größere Nodes, da er auch mehrere kleinere Nodes auf einmal hinzufügen kann.least-waste– wählt die Node Group, bei der nach dem Hochskalieren am wenigsten CPU (bei Gleichstand: am wenigsten Speicher) ungenutzt bleibt. Nützlich bei unterschiedlichen Node-Klassen, etwa Nodes mit hoher CPU- oder Speicherausstattung, die Sie nur dann erweitern wollen, wenn ausstehende Pods entsprechend viele Ressourcen benötigen.price– wählt die Node Group, die am günstigsten ist und deren Maschinen zugleich zur Cluster-Größe passen. Eine ausführliche Beschreibung finden Sie hier. Aktuell funktioniert dies nur für GKE.priority– wählt die Node Group, der vom Nutzer die höchste Priorität zugewiesen wurde. Die Konfiguration ist hier näher beschrieben.
In dieser Demo zeigen wir Ihnen, wie Sie den "Priority"-Expander einsetzen, damit der Autoscaler zunächst versucht, eine Spot-Instance-Node-Group zu erweitern, und – wenn das nicht möglich ist – auf eine On-Demand-Node-Group zurückgreift.
Bei GKE-Clustern, die mit dem "price"-Expander konfiguriert sind, ist das das Standardverhalten – bei EKS-Clustern hingegen nicht. Mit Cluster Autoscaler 1.14 wurde jedoch der "Priority"-Expander eingeführt, mit dem sich die Priorität für die Erweiterung verschiedener Node Groups festlegen lässt.
Demo
Für diese Demo legen wir einen EKS-Cluster mit dem hervorragenden Tool eksctl an. Bitte verwenden Sie eksctl in Version 0.16.0 oder höher, da wir die Capacity-Optimized Allocation Strategy für unsere Spot-Instance-Pools nutzen, deren Unterstützung mit eksctl 0.16.0 eingeführt wurde.
Der Cluster besteht aus zwei Node Groups: Die erste ist die Spot-Instances-Node-Group mit einer gewünschten Kapazität von einer Instance, einem Minimum von null und einem Maximum von 10 Instances. Die zweite ist die Fallback-On-Demand-Node-Group mit einer gewünschten Kapazität von null Instances, einem Minimum von null und einem Maximum von 10 Instances.
Diversifizierung der Instance-Typen & Capacity-Optimized Spot Allocation Strategy – maximale Verfügbarkeit
Unser Workload braucht für einen reibungslosen Betrieb (theoretisch) rund 1,5 vCPUs und 7 GB RAM. Daher haben wir die beiden Node Pools mit verschiedenen EC2-Instance-Typen diversifiziert, die jeweils 2 vCPUs und 8 GB RAM bereitstellen. Zwingende Voraussetzung: Alle Instance-Typen innerhalb eines Pools müssen dieselben vCPU- und RAM-Spezifikationen aufweisen, damit der Cluster Autoscaler korrekt arbeitet.
Die Diversifizierung des Pools mit verschiedenen Instance-Typen erhöht die Verfügbarkeit der Nodes spürbar: Engpässe bei einem bestimmten Instance-Typ lassen sich durch die Verfügbarkeit anderer Typen abfedern. Das hilft besonders dann, wenn sowohl Spot- als auch On-Demand-Kapazität eines bestimmten Typs knapp wird – andere Instance-Typen (mit abweichendem Preis) bleiben verfügbar.
Mit der Capacity-Optimized Allocation Strategy für unsere Spot Fleet stellen wir sicher, dass Nodes aus der Instance-Typ-Familie mit der größten verfügbaren Kapazität bereitgestellt werden – und damit aus jener mit der geringsten Wahrscheinlichkeit für eine Unterbrechung.
Klonen Sie das Demo-Repository und wechseln Sie in das geklonte Verzeichnis:
git clone https://github.com/doitintl/eks-spot-to-ondemand-fallback.git && cd eks-spot-to-ondemand-fallback
Cluster anlegen:
eksctl create cluster -f cluster/cluster.yaml
Damit werden drei CloudFormation-Stacks erstellt, die schließlich die Cluster-Infrastruktur aufsetzen (EKS Control Plane, zwei Auto Scaling Groups, VPC etc.). Sobald das abgeschlossen ist, meldet eksctl, dass der Cluster bereit ist.
[✔] EKS cluster "my-eks-cluster" in "us-east-1" region is ready
eksctl aktualisiert Ihre Kubeconfig-Datei automatisch mit den neuen Cluster-Informationen, sodass Sie nun kubectl-Befehle gegen den Cluster ausführen können.
Metrics-server bereitstellen:
kubectl apply -f metrics-server/
Die ConfigMap des Autoscaler Priority Expanders
Hier legen wir die Prioritäten fest, anhand derer der Autoscaler bei zusätzlichem Kapazitätsbedarf entscheidet, welche Node Group skaliert wird. Die ConfigMap muss den Namen cluster-autoscaler-priority-expander tragen und im selben Namespace angelegt werden, in dem auch der Autoscaler läuft (in unserem Fall haben wir kube-system als Namespace für den Cluster Autoscaler gewählt).
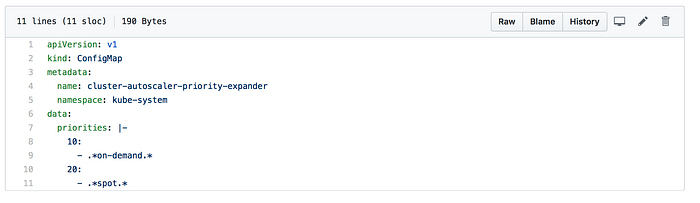
Die priorities-Daten bestehen aus einem Array von Schlüsseln (Priorität) und Werten (Regexp zur Auswahl des Node-Group-Namens). Wir haben die Node Groups so benannt, dass die Strings "on-demand" und "spot" jeweils im Namen enthalten sind, damit der Cluster Autoscaler entsprechend priorisieren kann.
ConfigMap des Autoscaler Priority Expanders bereitstellen:
kubectl apply -f 0-autoscaler/
Autoscaler bereitstellen:
Stellen Sie zunächst sicher, dass die Konfigurationsdatei des Autoscalers zu der von eksctl erstellten ASG passt. Ersetzen Sie dazu in 1-autoscaler/cluster-autoscaler.yaml die Zeilen 157 und 158 durch die neu in Ihrem AWS-Konto erstellten ASG-Namen. Diese finden Sie in der EC2-UI oder über folgenden AWS-CLI-Befehl:
aws --region=us-east-1 autoscaling describe-auto-scaling-groups | jq '.AutoScalingGroups[]? | "\(.Tags[]|select((.Key=="alpha.eksctl.io/cluster-name") and (.Value=="my-eks-cluster"))|.ResourceId )"'
Ersetzen Sie den String SPOT (Zeile 157) durch den ASG-Namen der Spot-Instances und den String on-demand (Zeile 158) durch den ASG-Namen der On-Demand-Instances.
Anschließend rollen Sie den Autoscaler aus:
kubectl apply -f 1-autoscaler/
App bereitstellen:
kubectl apply -f app/
Unser Stack besteht nun aus einem Spot-Instance-Node, auf dem ein Replikat unserer App läuft.


Wie zu sehen ist, gehört dieser Node zur Node Group spot-ng.

Skalieren wir das Deployment nun von einem auf zwei Replikate, kann der vorhandene Node den neuen Pod nicht mehr einplanen (wir haben den CPU-Request des Pods auf 1200m gesetzt, der Node hat aber nur 2 vCPU). Der Autoscaler fügt daraufhin einen weiteren Node hinzu – idealerweise aus der Spot-Instances-Node-Group.
App hochskalieren:
kubectl scale --replicas=2 deployment/php-apache
Der neue Pod befindet sich tatsächlich im Status "Pending", da er auf dem verfügbaren Node nicht eingeplant werden kann.

Nach wenigen Sekunden wird ein neuer Node hinzugefügt.

Prüfen wir, ob auch dieser aus der Spot-Instances-Node-Group stammt.

Wie zu sehen ist, gehört auch dieser Node zur Node Group spot-ng.
Unser ausstehender Pod ist nun auf dem neuen Node eingeplant.

Nun begrenzen wir die Spot-Instances-Node-Group auf maximal zwei Nodes und skalieren unsere App weiter hoch – in der Erwartung, dass eine neue On-Demand-Instance zur Lastbewältigung hinzugefügt wird.

Begrenzung der Spot-Instances-Node-Group auf maximal zwei Instances
Skalieren wir unsere App nun auf drei Replikate:
kubectl scale --replicas=3 deployment/php-apache
Der Autoscaler benötigt für den neuen Pod einen weiteren Node. Da die Spot-Instances-Group bereits ihre maximale Kapazität erreicht hat (wir haben sie auf zwei Nodes begrenzt), sollte er einen neuen Node aus der On-Demand-Group hochfahren.
Ein neuer Pod wartet auf einen neuen Node.

Ein neuer Node wird hinzugefügt.

Sehen wir uns an, zu welcher Node Group dieser Node gehört.

Wie zu sehen ist, gehört dieser Node zur Node Group on-demand-ng.
Der zuverlässige Fallback für Ihre Nodes
Wir haben gezeigt, wie Sie einen EKS-Cluster mit einer Spot-Instances-Node-Group und einer On-Demand-Instances-Node-Group anlegen und die Erweiterung der Spot-Instances-Node-Group priorisieren.
Aufräumen
eksctl delete cluster -f cluster/cluster.yaml
Der Übersichtlichkeit halber haben wir einige Aspekte bewusst ausgeklammert, etwa das Handling von Spot-Instance-Unterbrechungen sowie HPA. Diese sind dennoch sehr wichtig und sollten beim Design Ihrer Produktivumgebung berücksichtigt werden.
Bei Fragen freuen wir uns über Ihre Kommentare!