Chez DoiT International, nous visons l'efficacité des coûts et l'excellence opérationnelle. C'est pourquoi nous avons accueilli avec enthousiasme l'ajout de l'expander *Priority* au Cluster Autoscaler de Kubernetes. Celui-ci permet de définir des règles de priorité pour les décisions d'autoscaling des node pools et autorise donc la création d'un mécanisme de fallback depuis les groupes de nœuds Spot vers les groupes de nœuds on-demand pour les workloads stateless. Voici un guide rapide pour utiliser cette fonctionnalité avec des clusters Kubernetes tournant sur AWS EKS.
N'hésitez pas à passer directement à la démo si vous connaissez déjà l'Autoscaler et les différents types d'expanders.
Cluster Autoscaler
Qu'est-ce que le Cluster Autoscaler ?
Ce programme autonome s'exécute aux côtés de vos workloads dans le cluster Kubernetes, communique avec le metrics-server (un agrégateur des données d'utilisation des ressources à l'échelle du cluster), calcule la capacité nécessaire et appelle l'API du fournisseur cloud pour ajouter ou retirer de la capacité au cluster Kubernetes. Le cluster-autoscaler dispose de plusieurs logiques pour déterminer le type de capacité à ajouter au cluster : on les appelle des Expanders.
Que sont les Expanders ?
Cinq Expanders sont actuellement implémentés pour le Cluster Autoscaler :
random– l'Expander par défaut, à utiliser lorsque vous n'avez pas de besoin particulier de scaler les node groups différemment.most-pods– sélectionne le node group capable de planifier le plus de pods lors du scale-up. Utile lorsque vous utilisez nodeSelector pour vous assurer que certains pods soient placés sur certains nœuds. Notez que cela n'amènera pas l'Autoscaler à privilégier des nœuds plus gros plutôt que plus petits, puisqu'il peut ajouter plusieurs petits nœuds à la fois.least-waste– sélectionne le node group qui aura le moins de CPU inutilisé (et, en cas d'égalité, le moins de mémoire inutilisée) après le scale-up. Utile lorsque vous disposez de différentes classes de nœuds, par exemple à forte CPU ou à forte mémoire, et que vous ne souhaitez les étendre que lorsque des pods en attente nécessitent beaucoup de ces ressources.price– sélectionne le node group le moins coûteux dont les machines correspondent à la taille du cluster. Cet expander est décrit plus en détail ici. Il ne fonctionne actuellement que pour GKE.priority– sélectionne le node group ayant la priorité la plus élevée définie par l'utilisateur. Sa configuration est décrite plus en détail ici.
Dans cette démonstration, nous allons vous montrer comment exploiter l'expander *Priority* pour que l'Autoscaler tente d'abord d'étendre un node group Spot puis, à défaut, bascule vers le scale-out d'un node group on-demand.
S'il s'agit du comportement par défaut pour les clusters GKE, configurés via l'expander *price*, ce n'est pas le cas pour les clusters EKS. Heureusement, la sortie du Cluster Autoscaler 1.14 a introduit l'expander *Priority*, qui nous permet justement de définir l'ordre de priorité pour l'agrandissement des différents node groups.
Démo
Pour cette démonstration, nous allons créer un cluster EKS avec l'excellent outil eksctl. Veillez à utiliser eksctl 0.16.0 ou supérieure, puisque nous emploierons la stratégie d'allocation capacity-optimized pour nos pools d'instances Spot, dont la prise en charge a été introduite avec eksctl 0.16.0.
Le cluster sera composé de deux node groups : le premier est le node group Spot avec une capacité désirée d'une instance, un minimum de zéro et un maximum de 10 instances. Le second est le node group de fallback en on-demand avec une capacité désirée de zéro instance, un minimum de zéro et un maximum de 10 instances.
Diversification des types d'instances et stratégie capacity-optimized — pour maximiser la disponibilité
Notre workload nécessite environ 1,5 vCPU et 7 Go de RAM pour fonctionner correctement (en théorie) ; nous avons donc choisi de diversifier les 2 node pools avec différents types d'instances EC2 offrant 2 vCPU et 8 Go de RAM. Il est impératif que tous les types d'instances d'un même pool partagent les mêmes caractéristiques vCPU et RAM pour que le cluster-autoscaler fonctionne.
Diversifier le pool avec différents types d'instances maximise la disponibilité des nœuds : le manque de capacité d'un type d'instance peut être compensé par la disponibilité d'un autre type. Cela peut s'avérer très utile lorsque la capacité Spot et on-demand d'un type donné fait défaut : d'autres types (à la tarification différente) resteront disponibles.
L'utilisation de la stratégie d'allocation capacity-optimized pour notre flotte Spot garantit que les nœuds sont provisionnés depuis la famille d'instances disposant de la plus grande capacité disponible, et donc dotée de la plus faible probabilité d'interruption.
Clonez le dépôt de la démo et placez-vous dans le répertoire cloné :
git clone https://github.com/doitintl/eks-spot-to-ondemand-fallback.git && cd eks-spot-to-ondemand-fallback
Créez le cluster :
eksctl create cluster -f cluster/cluster.yaml
Cela déclenchera la création de trois stacks CloudFormation qui mettront en place l'infrastructure du cluster (control plane EKS, deux Autoscaling Groups, VPC, etc.). Une fois terminé, eksctl vous indiquera que le cluster est prêt.
[✔] EKS cluster "my-eks-cluster" in "us-east-1" region is ready
eksctl mettra automatiquement à jour votre fichier Kubeconfig avec les informations du nouveau cluster ; vous êtes donc prêt à exécuter des commandes kubectl sur le cluster.
Déployez le Metrics-server :
kubectl apply -f metrics-server/
Le ConfigMap du Priority Expander de l'Autoscaler
C'est ici que nous définissons les priorités que l'Autoscaler suivra pour choisir le node group à scaler en cas de besoin de capacité supplémentaire. Le ConfigMap doit obligatoirement s'appeler cluster-autoscaler-priority-expander et être créé dans le même namespace que celui de l'Autoscaler (dans notre cas, kube-system).
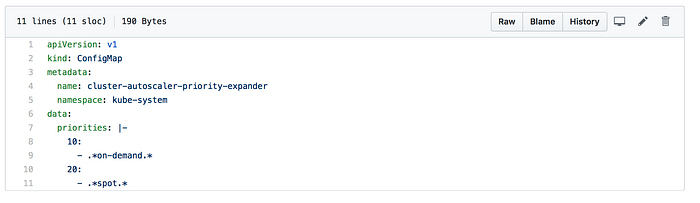
Les données priorities forment un tableau de clés (priorité) et de valeurs (regexp pour sélectionner le nom du node group). Nous avons créé les node groups en intégrant les chaînes on-demand et spot à leurs noms afin que le Cluster Autoscaler puisse les hiérarchiser correctement.
Déployez le ConfigMap du Priority Expander :
kubectl apply -f 0-autoscaler/
Déployez l'Autoscaler :
Vérifiez d'abord que le fichier de configuration de l'Autoscaler correspond aux ASG créés par eksctl. Pour cela, remplacez les lignes 157 et 158 du fichier 1-autoscaler/cluster-autoscaler.yaml par les nouveaux noms d'ASG créés dans votre compte AWS. Vous pouvez les récupérer depuis l'interface EC2 ou via cette commande AWS CLI :
aws --region=us-east-1 autoscaling describe-auto-scaling-groups | jq '.AutoScalingGroups[]? | "\(.Tags[]|select((.Key=="alpha.eksctl.io/cluster-name") and (.Value=="my-eks-cluster"))|.ResourceId )"'
Remplacez la chaîne SPOT (ligne 157) par le nom de l'ASG des instances Spot, et la chaîne on-demand (ligne 158) par le nom de l'ASG des instances on-demand.
Déployez ensuite l'Autoscaler :
kubectl apply -f 1-autoscaler/
Déployez l'application :
kubectl apply -f app/
Notre stack se compose désormais d'un nœud Spot exécutant une réplique de notre application.


Notez que le node group de ce nœud est bien spot-ng.

Si nous passons maintenant notre déploiement d'une réplique à deux, le nœud actuel ne pourra pas planifier ce nouveau pod (nous avons fixé la requête CPU du pod à 1200m alors que le nœud dispose de 2 vCPU), et l'Autoscaler créera un nouveau nœud, idéalement depuis le node group Spot.
Scalez l'application :
kubectl scale --replicas=2 deployment/php-apache
Le nouveau pod est bien en statut pending puisqu'il ne peut être planifié sur le nœud disponible.

Quelques secondes plus tard, un nouveau nœud est ajouté.

Vérifions qu'il provient lui aussi du node group Spot.

Notez que le node group de ce nœud est bien spot-ng.
Notre pod en attente est désormais planifié sur le nouveau nœud.

Limitons maintenant la taille maximale du node group Spot à deux instances et scalons notre application, en espérant qu'une nouvelle instance on-demand soit ajoutée pour absorber la charge.

Restriction du node group Spot à deux instances maximum.
Passons notre application à trois répliques :
kubectl scale --replicas=3 deployment/php-apache
L'Autoscaler aura besoin d'un nouveau nœud pour ce nouveau pod et, puisque le groupe Spot est désormais à sa capacité maximale (rappelez-vous, nous l'avons limité à deux nœuds), il devrait provisionner un nouveau nœud depuis le groupe on-demand.
Un nouveau pod attend un nouveau nœud.

Un nouveau nœud est ajouté.

Voyons à quel node group appartient ce nœud.

Notez que le node group de ce nœud est bien on-demand-ng.
Le fallback fiable pour vos nœuds
Nous avons vu comment créer un cluster EKS combinant un node group Spot et un node group on-demand, puis comment prioriser l'extension du node group Spot.
Nettoyage
eksctl delete cluster -f cluster/cluster.yaml
Nous avons volontairement laissé de côté plusieurs aspects pour la simplicité de cet exemple, comme la gestion des interruptions Spot et l'HPA, mais ils restent essentiels et doivent être pris en compte lors de la conception de votre environnement de production.
N'hésitez pas à laisser un commentaire si vous avez des questions !