En DoiT International apuntamos siempre a la eficiencia en costos y a la excelencia operativa. Por eso nos entusiasmó la incorporación del expander "Priority" al Cluster Autoscaler de Kubernetes. Esta función permite definir reglas de prioridad para las decisiones de autoescalado de los node pools y, así, armar un mecanismo de fallback que vaya desde los node groups de instancias Spot hacia los de on-demand para workloads stateless. Quisimos armar una guía rápida para usar esta función en clusters de Kubernetes corriendo sobre AWS EKS.
Si ya conoces el Autoscaler y los distintos tipos de expanders, salta directo a la demo
Cluster Autoscaler
¿Qué es Cluster Autoscaler?
Este programa independiente corre junto con tus workloads en el cluster de Kubernetes, se comunica con el metrics-server (un agregador de datos de uso de recursos a nivel de cluster), calcula la capacidad necesaria y llama a la API del proveedor cloud para aprovisionar (o liberar) capacidad del cluster de Kubernetes. El cluster-autoscaler cuenta con distintas lógicas para decidir qué tipo de capacidad sumar al cluster: estas se llaman Expanders.
¿Qué son los Expanders?
Hoy existen cinco Expanders implementados para Cluster Autoscaler:
random: es el Expander por defecto y conviene usarlo cuando no necesitas que los node groups escalen de forma diferente.most-pods: selecciona el node group capaz de programar la mayor cantidad de pods al escalar. Es útil cuando usas nodeSelector para asegurarte de que ciertos pods caigan en ciertos nodos. Ten en cuenta que esto no hará que el Autoscaler elija nodos más grandes en lugar de más chicos, ya que puede sumar varios nodos pequeños a la vez.least-waste: selecciona el node group que dejará la menor cantidad de CPU ociosa (o, en caso de empate, memoria sin usar) tras el escalado. Es útil cuando tienes distintas clases de nodos —por ejemplo, de alta CPU o alta memoria— y solo quieres expandirlos cuando hay pods pendientes que requieren muchos de esos recursos.price: selecciona el node group que costará menos y, a la vez, cuyas máquinas se ajusten al tamaño del cluster. Este expander se describe en detalle aquí. Por ahora solo funciona en GKE.priority: selecciona el node group con la prioridad más alta asignada por el usuario. Su configuración se describe en detalle aquí.
En esta demo te mostramos cómo aprovechar el expander "Priority" para que el Autoscaler intente primero escalar un node group de instancias Spot y, si no puede, recurra a un node group on-demand.
Si bien este es el comportamiento por defecto en clusters de GKE —que se configuran con el expander "price"—, no ocurre lo mismo en clusters de EKS. Por suerte, con el lanzamiento de Cluster Autoscaler versión 1.14 se incorporó el expander "Priority" y podemos usarlo para definir la prioridad con la que se expanden los distintos node groups.
Demo
Para esta demostración crearemos un cluster de EKS con la excelente herramienta eksctl. Asegúrate de usar eksctl 0.16.0 o superior, ya que vamos a aplicar la estrategia de asignación capacity-optimized en nuestros pools de instancias Spot, soporte que se incorporó en eksctl 0.16.0.
El cluster estará compuesto por dos node groups: el primero es el node group de instancias Spot, con capacidad deseada de una instancia, mínimo cero y máximo diez. El segundo es el node group de fallback on-demand, con capacidad deseada de cero instancias, mínimo cero y máximo diez.
Diversificación de tipos de instancia y estrategia Capacity-Optimized para Spot: maximizan la disponibilidad
Nuestro workload necesita alrededor de 1.5 vCPUs y 7 GB de RAM para funcionar de forma estable (en teoría), por lo que decidimos diversificar los 2 node pools con distintos tipos de instancias EC2 que nos brindan 2 vCPUs y 8 GB de RAM. Es obligatorio que todos los tipos de instancias dentro de un mismo pool tengan las mismas especificaciones de vCPU y RAM para que el cluster-autoscaler funcione correctamente.
Diversificar el pool con distintos tipos de instancias maximiza la disponibilidad de nodos, ya que la falta de capacidad de un tipo de instancia se compensa con la disponibilidad de otro. Esto resulta muy útil cuando escasea la capacidad Spot y on-demand de un tipo: otros tipos (con precios distintos) seguirán disponibles.
Usar la estrategia capacity-optimized en nuestro spot fleet asegura que los nodos se aprovisionen desde la familia de tipo de instancia con mayor capacidad disponible y, por lo tanto, con la menor probabilidad de interrupción.
Clona el repositorio de la demo y entra al directorio clonado:
git clone https://github.com/doitintl/eks-spot-to-ondemand-fallback.git && cd eks-spot-to-ondemand-fallback
Crea el cluster:
eksctl create cluster -f cluster/cluster.yaml
Esto disparará la creación de tres stacks de CloudFormation que terminarán configurando la infraestructura del cluster (control plane de EKS, dos Auto Scaling Groups, VPC, etc.). Cuando termine, eksctl te avisará que el cluster está listo.
[✔] EKS cluster "my-eks-cluster" in "us-east-1" region is ready
eksctl actualizará automáticamente tu archivo Kubeconfig con la información del nuevo cluster, así que ya puedes correr comandos kubectl contra el cluster.
Despliega el Metrics-server:
kubectl apply -f metrics-server/
El Config Map del Priority Expander del Autoscaler
Aquí definimos las prioridades que el Autoscaler usará al elegir qué node group escalar cuando se necesite capacidad adicional. El nombre del config map debe ser cluster-autoscaler-priority-expander y debe crearse en el mismo namespace donde reside el Autoscaler (en nuestro caso elegimos kube-system como namespace para el cluster Autoscaler).
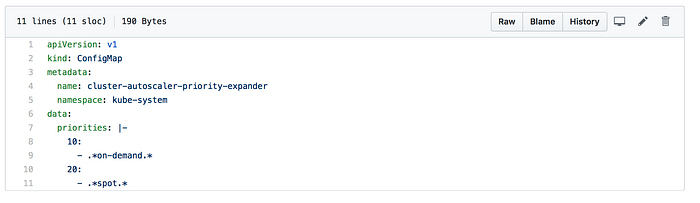
El dato priorities es un array de claves (priority) y valores (regexp para seleccionar el nombre del node group). Creamos los node groups con las cadenas on-demand y spot incluidas en sus nombres para que Cluster Autoscaler pueda priorizarlos correctamente.
Despliega el Config Map del Priority Expander del Autoscaler:
kubectl apply -f 0-autoscaler/
Despliega el Autoscaler:
Primero, asegúrate de que el archivo de configuración del Autoscaler coincida con el ASG creado por eksctl. Para hacerlo, reemplaza las líneas 157 y 158 de 1-autoscaler/cluster-autoscaler.yaml con los nombres de los nuevos ASG creados en tu cuenta de AWS. Puedes obtenerlos desde la UI de EC2 o con este comando de AWS CLI.
aws --region=us-east-1 autoscaling describe-auto-scaling-groups | jq '.AutoScalingGroups[]? | "\(.Tags[]|select((.Key=="alpha.eksctl.io/cluster-name") and (.Value=="my-eks-cluster"))|.ResourceId )"'
Reemplaza la cadena SPOT (línea 157) con el nombre del ASG de instancias Spot, y la cadena on-demand (línea 158) con el ASG de instancias on-demand.
Luego, despliega el Autoscaler:
kubectl apply -f 1-autoscaler/
Despliega la app:
kubectl apply -f app/
Nuestro stack actual se compone de un nodo Spot que corre una réplica de nuestra app.


Observa que el node group de este nodo es spot-ng

Ahora, si escalamos nuestro deployment de una a dos réplicas, el nodo actual no podrá programar este nuevo pod (definimos el request de CPU del pod en 1200m, mientras que el nodo tiene 2 vCPU), y el Autoscaler levantará otro nodo, idealmente desde el node group de instancias Spot.
Escala la app:
kubectl scale --replicas=2 deployment/php-apache
En efecto, el nuevo pod queda en estado pending porque no puede programarse en el nodo disponible.

Tras unos segundos se suma un nuevo nodo.

Verifiquemos que también provenga del node group de instancias Spot.

Observa que el node group de este nodo es spot-ng
Nuestro pod pendiente ya está programado en el nuevo nodo.

Ahora limitemos el node group de Spot a un máximo de dos nodos y escalemos la app, esperando que se sume una nueva instancia on-demand para manejar la carga.

Restringiendo el node group de instancias Spot a un máximo de dos instancias
Ahora escalemos la app a tres réplicas:
kubectl scale --replicas=3 deployment/php-apache
El Autoscaler necesitará otro nodo para este nuevo pod, y como el grupo de Spot ya está en su capacidad máxima (recuerda que lo limitamos a dos nodos), debería levantar un nuevo nodo desde el grupo on-demand.
Un nuevo pod queda pendiente, esperando un nodo.

Se suma un nuevo nodo.

Veamos a qué node group pertenece este nodo.

Observa que el node group de este nodo es on-demand-ng
El fallback confiable para tus nodos
Vimos cómo crear un cluster de EKS con un node group de instancias Spot y otro de instancias on-demand, y cómo priorizar la expansión del node group de Spot.
Limpieza
eksctl delete cluster -f cluster/cluster.yaml
Hay muchos aspectos que decidimos dejar fuera por simplicidad, como el manejo de interrupciones de instancias Spot y el HPA, pero son muy importantes y conviene tenerlos en cuenta al diseñar tu entorno de producción.
¡Escríbenos en los comentarios si tienes alguna duda!