はじめに
本記事では、データウェアハウスでよく直面する課題、すなわち「データの鮮度を保ちつつ、大規模なミューテーションを避ける」ためのアプローチをご紹介します。
DoiTでは、多くのお客様とともに、クラウドサービスを最大限に活用したWell-Architectedなシステムづくりを支援しています。本記事も、実際のお客様事例から得られた知見に基づくものです。
背景
あるSaaS企業は、BigQuery上に構築した分析プラットフォームを自社の顧客に提供しています。一部の顧客では、前回更新からの差分ではなく、全履歴を含む完全なスナップショットとしてデータが届く運用になっています。
そのうちの1社のスナップショットは15TBにも達しますが、実際に変化しているのはわずか0.1%にすぎません。差分のみを取得する手段がないため、新しいスナップショットで既存テーブルを更新する際に、信頼性が高くパフォーマンスとコストの両面で最も効率的な方法を見つけることが、チームの課題でした。
データパイプラインの要件
同社と顧客は、ビジネス要件と技術要件の双方を満たすため、データパイプラインのデータコントラクトを次のように定義しました。
- 受信データは2年間のスライディングウィンドウを丸ごと含む完全なスナップショットで、1日6回到着します。
- データは日付でパーティション分割され(パーティションサイズは約20GiB)、スナップショットID(増分値)が付与されます。
- データには新規レコード(新しいキー)と変更レコード(既存データの更新)の両方が含まれます。
- パーティションの有効期限は2年に設定されています。
- 現在のスナップショットには存在するが新しいスナップショットには存在しないレコードは、パーティションの有効期限まで保持されます。
SaaS企業のプロダクトチームは、さらに以下の要件を定義しました。
- モデリング:既存データと新規データを保持する2つのテーブルを使用する。
新規データは「staging」テーブルに、顧客に公開される既存データは「target」テーブルに格納します。
- 一意性:「target」テーブルのデータは一意である(キーの重複なし)。
- 鮮度:「target」テーブルはスナップショット到着から1時間以内に更新される。
- 可用性:エンドユーザーのクエリには常にレスポンスを返す。
ミューテーションの課題
以下のGoogle Blogでも述べられているとおり、BigQueryは大規模ミューテーションを得意とするOLTP型のトランザクション処理DBとは設計思想が根本的に異なります。
「BigQueryに限らず、OLAPデータベース全般において、ミューテーション頻度は明示的に(クォータによって)あるいは暗黙的に(顕著なパフォーマンス劣化として)制約されます。これらのデータベースはトランザクション処理ではなく、大規模なデータ取り込みと分析クエリに最適化されているためです。
さらにBigQueryでは、過去7日間の任意の時点におけるテーブル状態を読み取ることができます。このルックバックウィンドウを実現するため、ユーザーが既に削除したデータも保持する必要があります。大規模かつ低コストで効率的なクエリを実現するため、BigQueryはクォータによってミューテーション頻度を制限しています。」(Performing large-scale mutations in BigQuery | Google Cloud Blog)
古いスナップショットを丸ごと新しいスナップショットに置き換える方法では不十分です。現在のスナップショットには存在するが最新のスナップショットには存在しないレコードを、引き続き保持しなければならないからです。
つまり、既存スナップショットと新規スナップショットのレコードを比較する仕組みが必要であり、単純な置き換えではこの比較は実現できません。
ミューテーションの選択肢とその違いを整理するため、まずは具体的なデータモデリングとミューテーションロジックを使って問題を厳密に定義します。
データモデリング
テーブルスキーマ:
テーブル(「staging」または「target」)の1レコードには、ある店舗(store_id)における特定の商品(product_id)の特定日時点での属性ID(attribute_id)とその値、加えてそのレコードが含まれていたスナップショットの参照(update_id)が格納されます。

レコード例:
スナップショットID 1(update_id)で受信したデータによると、店舗(store_id = 2072)における商品(product_id = 301865)の合計数量(attribute_id = 1)は、2017年4月21日時点で20でした。
ミューテーションロジックの例:
以下は、同一パーティション(特定日付)について、2つの異なるスナップショットから取得したサンプルです。
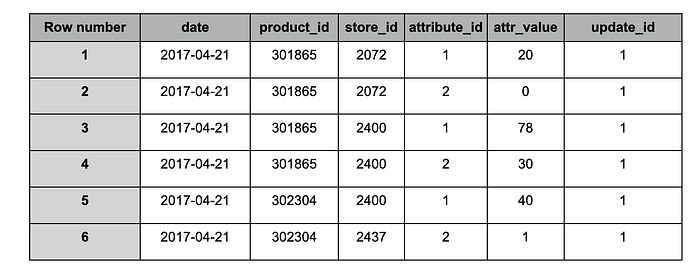
スナップショット#1取り込み後の「target」テーブル
スナップショット#2には、次の変更が含まれていました。
1. 青:更新されたレコード(両方のスナップショットに存在し、値が変更されたもの)。
2. 赤:履歴レコード(スナップショット#1のみに存在)。
3. 緑:新規レコード(スナップショット#2のみに存在)。
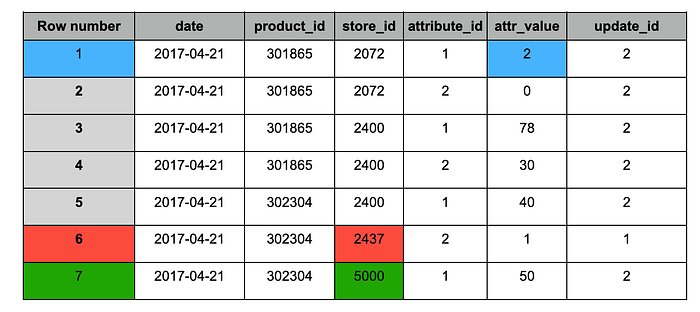
スナップショット#2取り込み後の「target」テーブル
BigQueryはMERGEをサポートしているため、stagingテーブルとtargetテーブルを以下のロジックでマージするのが、まず思いつくアプローチです。
マージロジック
このMERGEロジックでは、product_id、store_id、attribute_idで構成される結合キーをもとに、ケースごとに適用するミューテーションを定義します。
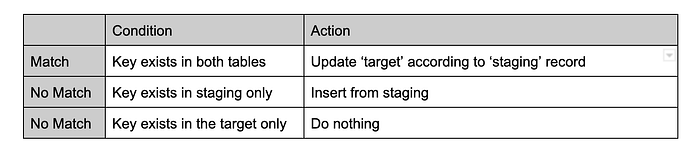
MERGEロジックの実装コードは次のとおりです。
MERGE
nw-playground.demo.merge_target T
USING
nw-playground.demo.merge_staging S
ON
T.product_Id = S.product_Id
AND T.store_Id = S.store_Id
AND T.attribute_Id = S.attribute_Id
AND T.date = S.date
WHEN MATCHED and T.date >= '2017-04-14' and T.date <= '2017-04-26'
THEN UPDATE SET T.attr_value = S.attr_value, T.update_id = S.update_id
WHEN NOT MATCHED BY TARGET and S.date >= '2017-04-14' and S.date <= '2017-04-26'
THEN
INSERT
(date,
product_Id,
store_Id,
attribute_Id,
attr_value,
update_id)
VALUES
(S.date, S.Product_id, S.store_Id, S.attribute_Id, S.attr_value, S.update_id);
問題点:
前述のとおり、BigQueryでのMERGEはコストが非常に高く、既存データのシャッフルとミューテーションを伴うため制約も多くなります。
そこで、MERGEとデータミューテーションを回避する方法を考える必要があります。
重複排除とCLONEによるアプローチ
何をするのか 「staging」テーブルと「target」テーブルのレコードをマージするのではなく、次の手順で処理します。
- 新しいスナップショットを「staging」テーブルに追加(append)する。
- 類似レコードを重複排除し、最新のレコードのみを残す。
重複排除(Deduplication)とは、重複したレコードを取り除き、1件だけを残す処理です。類似レコードを識別するためのレコードキーと、重複したレコードのうちどれを残すかを決めるロジック(例:最新のレコードを残す)を定義することで実現します。
3. 重複排除の結果で「staging」テーブルを置き換える。
4. 「staging」テーブルのCLONEで「target」テーブルを置き換える。
「CLONEテーブルクローンは、別のテーブル(ベーステーブル)に対する軽量で書き込み可能なコピーです。課金対象となるのはベーステーブルと差分のあるデータのストレージのみで、作成直後の段階ではテーブルクローンのストレージコストは発生しません。ストレージの課金モデルとベーステーブル側の追加メタデータを除けば、テーブルクローンは標準的なテーブルとほぼ同じように扱え、クエリ・コピー・削除などが行えます。作成後はベーステーブルから独立し、ベーステーブルとテーブルクローンの一方に加えた変更は、他方には反映されません。」table-clones-intro
どう実現するのか
- データ追加:
LOADコマンドを「append」モードで実行し、stagingテーブルに現在のスナップショットと新しいスナップショットの両方を保持させます。 - 重複排除:同一キーを持つレコードのうち、最新のものだけを残します。完全に新規のレコードや、現在のスナップショットにのみ存在するレコードには影響しません。実装には、行のグループに対して値を計算する「ウィンドウ関数」と
QUALIFY句を使います。QUALIFY句では、ウィンドウ関数の結果(行のグループ)を直接フィルタリングできます。 - 「staging」の置き換え:重複排除クエリの結果をもとに
CREATE OR REPLACEを実行します。 - 「staging」を「target」にクローン:
CREATE OR REPLACE TABLE ... CLONEを実行します。
なぜそうするのか
このアプローチは、MERGE方式と比べて次のメリットがあります。
1. データシャッフルの削減:新しいスナップショットを既存スナップショットに追加するため、2つのテーブル間でのシャッフルが不要になります。
2. MERGE/JOINの回避:重複排除はPARTITION BY句を用いたウィンドウ関数で実装します。これにより入力行はパーティションに分割され、各パーティション内で独立してウィンドウ関数が評価されます。
3. ミューテーションの回避:新しいテーブルを作成またはクローンするため、BigQueryのミューテーションクォータの制約を受けません。
追加(append)と重複排除のロジック例:
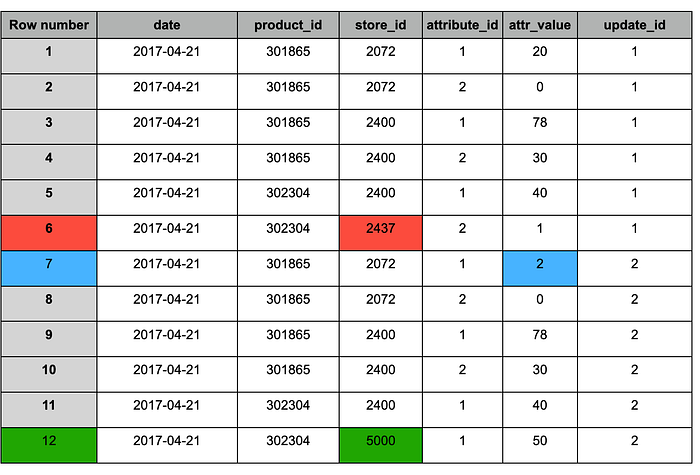
新しいスナップショット(#2)を追加した後のstagingテーブル
MERGEと同様、重複排除後のテーブルには次の変更が反映されます。
1. 青 — 更新されたレコード(両方のスナップショットに存在し、値が変更されたもの)。
2. 赤 — 保持すべき古いレコード(スナップショット#1のみに存在)。
3. 緑 — 新規レコード(スナップショット#2のみに存在)。
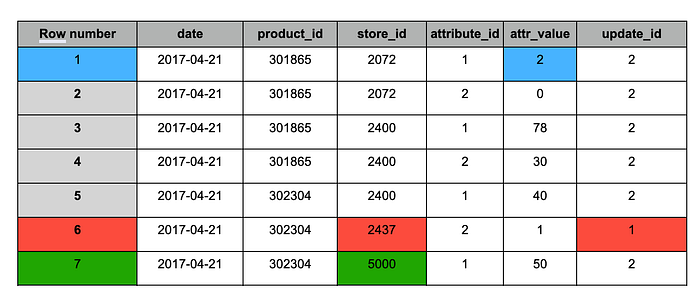
重複排除後のstagingテーブル
次のスナップショットが到着した際も、同じ流れで処理されます。
コード例
以下のコードは、QUALIFY句で同一キーのレコードに行番号を付与し(1行目=rownum=1が最新)、その重複排除結果から新しいstagingテーブルを作成して既存のテーブルを置き換えるものです。
CREATE OR REPLACE TABLE
`nw-playground.demo.dedup_staging`
(date DATE, product_id INT64,
store_id INT64, attribute_id INT64,
attr_value INT64, update_id INT64)
PARTITION BY
date
CLUSTER BY
product_id,
store_id AS
SELECT
date, product_id, store_id, attribute_id, attr_value, update_id
FROM
`nw-playground.demo.dedup_staging`
WHERE
date >= '2017-04-14' AND date <= '2017-04-26'
QUALIFY ROW_NUMBER()
OVER(PARTITION BY date, product_id, store_id, attribute_id
ORDER BY update_id DESC ) = 1;
CREATE OR REPLACE TABLE
`nw-playground.nw_demo.dedup_target`
CLONE `nw-playground.nw_demo.dedup_staging`;
テストデータと結果
テストは、78億件のレコード(350GiB)を13個のパーティションに分散させ、「staging」と「target」の間に約300万件の差分(あらゆる種類の変更を含む)がある状態で実施しました。課金モデルはオンデマンドを利用しています。
MERGEのケースでは、「staging」テーブルに新しいスナップショットのみ、「target」テーブルに既存スナップショットを格納しました。一方、重複排除のケースでは、stagingテーブルに既存と新規の両方のスナップショットを格納し、「target」はstagingの最初のスナップショットをクローンしたものとしています。
結果の比較
以下の表は、両者の結果を比較したものです。

実行詳細サマリーの比較
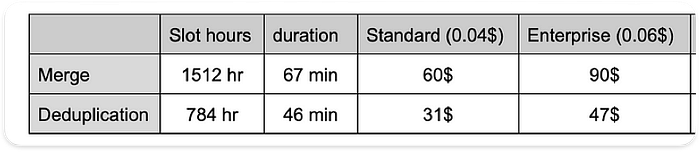
実行プランを比較すると、MERGEテストの所要時間とスロット使用量はいずれも、DEDUPLICATEのおよそ2倍であることがはっきり確認できます。

主要処理の所要時間とスロット使用量
コスト比較
オンデマンド課金モデル
スキャンするデータ量が同じであるため、両テスト間のコストはほぼ同等です。30TBのスナップショット2本分でフルロードした場合、およそ187ドル(1TiBあたり6.25ドル)になります。
BigQuery Editions
Googleが2023年4月に発表した新しい課金モデルは、容量ベースの料金体系(スロット時間あたりの課金)で、3つのエディションが用意されています。本番ロードのコストを試算するには、今回のテスト規模を56倍することで、フルスナップショットロード(2年=730日分のパーティション、730/13=56)を見積もることができます。
実際には構成やcommitmentsの違いも影響するため、この試算は厳密なものではありません。あくまで2つの選択肢の差を把握するための目安としてご覧ください。
BigQuery Edition別の試算コスト比較(米国価格)
付録
重複排除の実装方法は複数あります(ROWNUMやGroup Byなど)。ROWNUMで試したところ、QUALIFY句とほぼ同等のパフォーマンスでしたが、QUALIFYのほうがコードがすっきりします。一方、「Group By」を使った場合はパフォーマンスが悪化し、Mergeと同程度の結果に留まりました。
もう1つの効率的な実装方法としてApache Spark向けのストアドプロシージャがありますが、こちらは次回のブログで取り上げます。
本ユースケースで示したように、既存データとの結合ロジックを伴う大規模なミューテーションが課題となる場面では、データそのものを書き換えないアプローチが最良の選択肢になります。
「重複排除」とCLONEを組み合わせれば、DMLの制約を回避しつつ、所要時間とスロット使用量の双方を大きく改善でき、結果としてパフォーマンスとコストをいずれも約50%削減できます。