Premessa
In questo articolo presentiamo un approccio per affrontare una sfida ben nota nei data warehouse: mantenere i dati aggiornati evitando mutazioni su larga scala.
In DoiT affianchiamo molti clienti nella progettazione di sistemi well-architected e nell'uso efficiente dei servizi cloud: quanto segue nasce proprio dall'esperienza con uno di loro.
Contesto
Una società SaaS offre ai propri clienti una piattaforma analitica basata su BigQuery. Per alcuni di essi i dati arrivano sotto forma di snapshot completo, comprensivo dell'intera cronologia e non delle sole variazioni incrementali rispetto all'ultimo aggiornamento.
Uno di questi clienti fornisce uno snapshot da 15 TB, ma i dati effettivamente aggiornati rappresentano appena lo 0,1%. Non potendo ricevere solo le modifiche incrementali, il team doveva individuare il modo più affidabile ed efficiente — sia in termini di performance sia di costi — per aggiornare la tabella esistente con i dati del nuovo snapshot.
Requisiti della pipeline dati
L'azienda e il cliente hanno definito un data contract per la pipeline che soddisfacesse i requisiti di business e tecnici:
- I dati in ingresso sono uno snapshot completo su una finestra mobile di due anni, con cadenza di sei volte al giorno.
- I dati sono partizionati per giorno (ogni partizione ha una dimensione di circa 20 GiB) e contrassegnati da uno snapshot ID (valore incrementale).
- I dati conterranno sia nuove informazioni (nuove chiavi) sia dati modificati (aggiornamenti a record esistenti).
- Scadenza delle partizioni configurata a 2 anni.
- I record presenti nello snapshot corrente ma assenti in quello nuovo restano in tabella fino alla scadenza della partizione.
Il team di prodotto della società SaaS ha definito i seguenti requisiti:
- Modellazione: due tabelle conterranno rispettivamente i dati esistenti e quelli nuovi.
I nuovi dati risiedono in una tabella chiamata "staging", mentre i dati esistenti (quelli esposti al cliente) si trovano in una tabella denominata "target".
- Univocità: i dati della tabella "target" sono univoci (nessuna chiave duplicata).
- Freschezza: la tabella "target" viene aggiornata entro un'ora dall'arrivo dello snapshot.
- Disponibilità: l'utente finale ottiene sempre una risposta a una query.
La sfida della mutazione
Come spiega il blog di Google citato di seguito, BigQuery non è progettato come i database OLTP transazionali, nativamente efficienti nell'eseguire mutazioni di grandi dimensioni.
"BigQuery non è l'unico database OLAP a essere vincolato sulla frequenza di mutazione, in modo esplicito (tramite quote) o implicito (con un significativo degrado delle performance), perché questo tipo di database è ottimizzato per ingestion su larga scala e query analitiche, non per il transaction processing.
Inoltre, BigQuery consente di leggere lo stato di una tabella in qualsiasi istante dei sette giorni precedenti. Questa finestra di look-back richiede di conservare dati che l'utente ha già eliminato. Per garantire query efficienti ed economicamente sostenibili su larga scala, BigQuery limita la frequenza delle mutazioni tramite quote." ( Performing large-scale mutations in BigQuery | Google Cloud Blog )
Una sostituzione totale, che rimuova lo snapshot vecchio e lo rimpiazzi con quello nuovo, non basta: occorre conservare i record presenti nello snapshot corrente ma assenti in quello più recente.
Bisogna quindi confrontare i record tra lo snapshot esistente e quello nuovo, cosa che il classico approccio di sostituzione non prevede.
Per illustrare le opzioni di mutazione e le loro differenze, definiamo il problema in modo preciso, con la modellazione dei dati e la logica di mutazione.
Modellazione dei dati
Schema della tabella:
Un record in una tabella ('staging' o 'target') contiene un attribute_id e un valore per uno specifico prodotto (product_id) in un punto vendita (store_id) per una determinata data, oltre al riferimento allo snapshot in cui era presente (update_id).

Esempio di record:
In base ai dati ricevuti nello snapshot ID 1 (update_id), il valore Total quantity (attribute_id = 1) di un prodotto (product_id = 301865) in un punto vendita (store_id = 2072) era pari a 20 in data 2017–04–21.
Esempio di logica di mutazione:
Di seguito un campione preso da una partizione (data specifica) di due snapshot diversi.
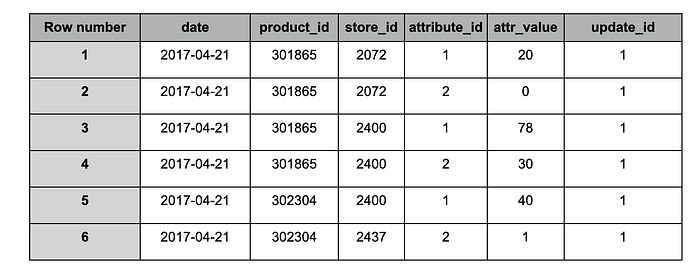
Tabella 'target' dopo l'ingestion dello snapshot #1
Lo snapshot #2 conteneva le seguenti modifiche:
1. Blu: record aggiornati (presenti in entrambi gli snapshot), con valore modificato.
2. Rosso: record storici (presenti solo nello snapshot #1).
3. Verde: nuovi record (presenti solo nello snapshot #2).
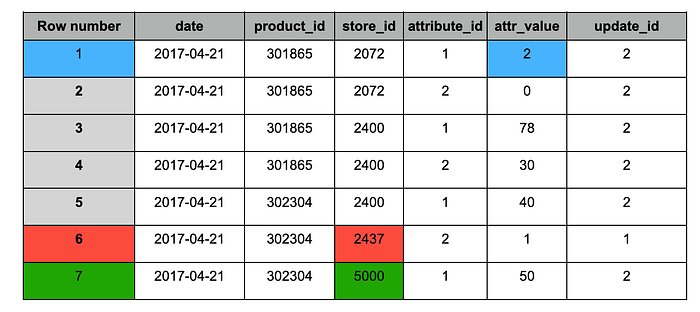
Tabella 'target' dopo l'ingestion dello snapshot #2
Poiché BigQuery supporta MERGE, l'approccio più intuitivo è unire la tabella di staging a quella target, applicando la logica seguente.
Logica di Merge
Questa logica di MERGE definisce le mutazioni da applicare nei diversi casi, sulla base di una chiave di join composta dai seguenti campi: product_id, store_id, attribute_id.
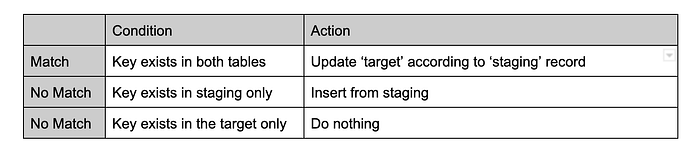
Ecco l'implementazione in codice della logica MERGE:
MERGE
nw-playground.demo.merge_target T
USING
nw-playground.demo.merge_staging S
ON
T.product_Id = S.product_Id
AND T.store_Id = S.store_Id
AND T.attribute_Id = S.attribute_Id
AND T.date = S.date
WHEN MATCHED and T.date >= '2017-04-14' and T.date <= '2017-04-26'
THEN UPDATE SET T.attr_value = S.attr_value, T.update_id = S.update_id
WHEN NOT MATCHED BY TARGET and S.date >= '2017-04-14' and S.date <= '2017-04-26'
THEN
INSERT
(date,
product_Id,
store_Id,
attribute_Id,
attr_value,
update_id)
VALUES
(S.date, S.Product_id, S.store_Id, S.attribute_Id, S.attr_value, S.update_id);
Il problema:
Come anticipato, l'operazione MERGE in BigQuery è molto onerosa e presenta dei limiti, perché richiede shuffling e mutazione dei dati esistenti.
Dobbiamo quindi trovare un modo per evitare il MERGE e la mutazione dei dati.
Approccio Deduplicate and Clone
Cosa faremo? Invece di unire i record delle tabelle 'staging' e 'target', procederemo così:
- Aggiungiamo il nuovo snapshot alla tabella 'staging'.
- Deduplichiamo i record simili mantenendo solo quello più recente.
La deduplicazione è il processo che rimuove i record duplicati lasciandone uno solo. Si ottiene definendo una chiave per identificare i record simili e una logica per scegliere quale conservare tra i duplicati (ad esempio, il record più recente).
3. Sostituiamo la tabella 'staging' con il risultato della deduplicazione.
4. Sostituiamo la tabella 'target' con un CLONE della tabella 'staging'.
"CLONE Un table clone è una copia leggera e scrivibile di un'altra tabella (chiamata tabella base). Si paga solo per i dati di storage del clone che differiscono dalla tabella base, quindi inizialmente non c'è alcun costo di storage per il clone . A parte il modello di fatturazione per lo storage e alcuni metadati aggiuntivi della tabella base, un table clone è simile a una tabella standard: lo si può interrogare, copiare, eliminare e così via. Una volta creato, il clone è indipendente dalla tabella base. Le modifiche apportate alla tabella base o al clone non si riflettono sull'altra. " table-clones-intro
Come lo facciamo?
- Append dei dati: usiamo il comando
LOADin modalità 'append', così che la tabella di staging contenga sia lo snapshot attuale sia quello nuovo. - Deduplicazione: eliminiamo i duplicati dei record simili (stessa chiave) mantenendo il più recente. La deduplicazione non incide sui record completamente nuovi né su quelli presenti solo nello snapshot corrente. È implementata tramite le ' Windows functions', che calcolano valori su un gruppo di righe, e l'operazione
QUALIFY. La clausolaQUALIFYfiltra i risultati di una window function (gruppo di righe). - Sostituzione di 'staging': tramite
CREATE OR REPLACEsulla base dei risultati della query di deduplicazione. - Clonazione di 'staging' su 'target': tramite
CREATE OR REPLACE TABLE ... CLONE.
Perché lo facciamo?
Questo approccio offre diversi vantaggi rispetto al MERGE:
1. Riduzione dello shuffling dei dati: aggiungere il nuovo snapshot a quello esistente evita lo shuffling tra due tabelle.
2. Niente operazioni MERGE/JOIN: la deduplicazione si basa su una window function che usa la clausola PARTITION BY, suddividendo le righe in input in partizioni separate, su ciascuna delle quali la window function viene valutata in modo indipendente.
3. Niente mutazioni: si creano o si clonano nuove tabelle, aggirando i limiti di quota di mutazione di BigQuery.
Esempio della logica di append e deduplicazione:
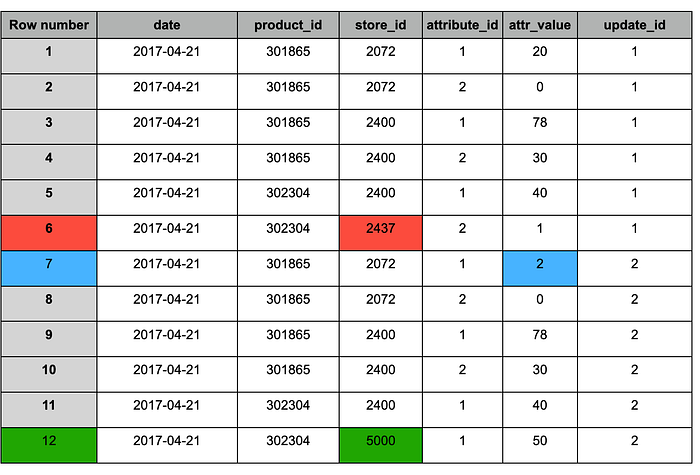
Tabella di staging dopo l'append del nuovo snapshot (#2)
Analogamente al risultato del MERGE, la tabella dopo la deduplicazione contiene le seguenti modifiche:
1. Blu: record aggiornati (presenti in entrambi gli snapshot), con valore modificato.
2. Rosso: record storici da mantenere (presenti solo nello snapshot #1).
3. Verde: nuovi record (presenti solo nello snapshot #2).
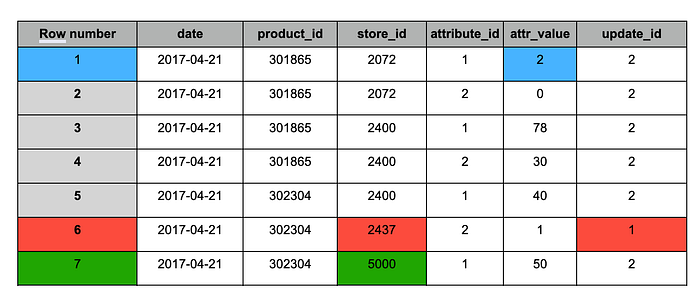
Tabella di staging dopo la deduplicazione
All'arrivo dello snapshot successivo, il processo seguirà gli stessi passaggi.
Esempi di codice
Il codice seguente crea una nuova tabella di staging a partire dai risultati della deduplicazione, sostituendo quella esistente. Sfrutta la clausola QUALIFY e assegna un numero di riga a ciascun record con chiave simile, dove il primo record (rownum=1) è il più recente.
CREATE OR REPLACE TABLE
`nw-playground.demo.dedup_staging`
(date DATE, product_id INT64,
store_id INT64, attribute_id INT64,
attr_value INT64, update_id INT64)
PARTITION BY
date
CLUSTER BY
product_id,
store_id AS
SELECT
date, product_id, store_id, attribute_id, attr_value, update_id
FROM
`nw-playground.demo.dedup_staging`
WHERE
date >= '2017-04-14' AND date <= '2017-04-26'
QUALIFY ROW_NUMBER()
OVER(PARTITION BY date, product_id, store_id, attribute_id
ORDER BY update_id DESC ) = 1;
CREATE OR REPLACE TABLE
`nw-playground.nw_demo.dedup_target`
CLONE `nw-playground.nw_demo.dedup_staging`;
Dati di test e risultati
Il test è stato eseguito su 7,8 miliardi di record (350 GiB) distribuiti su 13 partizioni con circa 3 milioni di differenze (di tutte le tipologie) tra 'staging' e 'target', utilizzando il modello di fatturazione on-demand.
Nel caso del MERGE, la tabella 'staging' conteneva solo il nuovo snapshot e quella 'target' lo snapshot esistente. Nel caso della deduplicazione, invece, la tabella di staging conteneva sia lo snapshot esistente sia quello nuovo, mentre 'target' era un clone del primo snapshot di staging.
Confronto dei risultati
La tabella seguente riporta il confronto dei risultati:

Riepilogo del confronto sui dettagli di esecuzione
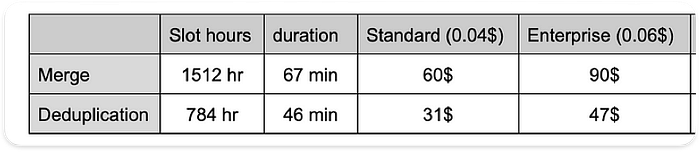
Confrontando i piani di esecuzione, emerge chiaramente come la durata e l'utilizzo degli slot nel test con MERGE siano il doppio rispetto al test con DEDUPLICATE:

Durata e utilizzo degli slot dell'operazione principale
Confronto dei costi
Modello di fatturazione on-demand
Il costo è simile tra i due test, perché la quantità di dati scansionata è la stessa. In un full load arriva a circa 187 $ (6,25 $ per 1 TiB), considerando 30 TB su 2 snapshot.
BigQuery Editions
Il nuovo modello di fatturazione introdotto da Google ad aprile 2023 si basa sul capacity pricing (pagamento per slot/ora) ed è disponibile in tre edizioni. Per stimare il costo del carico di produzione, possiamo ipotizzare un full snapshot load con un fattore 56 rispetto al test eseguito (730 partizioni-giorno in 2 anni; 730/13 = 56).
La stima dei costi non è puntuale, perché esistono diverse configurazioni e commitments applicabili. L'obiettivo è soprattutto evidenziare la differenza tra le due opzioni.
Confronto della stima dei costi tra le edizioni di BigQuery (prezzi US)
Appendice
Esistono diversi modi per implementare la deduplicazione (con ROWNUM o GROUP BY). La deduplicazione tramite ROWNUM ha mostrato performance simili a quella con clausola QUALIFY, anche se QUALIFY risulta un comando più pulito. "GROUP BY" ha invece prodotto performance peggiori, paragonabili a quelle del Merge.
Esiste poi un altro approccio efficiente: le stored procedure per Apache Spark, che approfondiremo nel prossimo articolo…
Come illustrato nel caso d'uso, si tratta di una mutazione su larga scala basata su una logica di join con i dati esistenti. La strada migliore è proprio quella di evitare modifiche ai dati.
L'approccio basato su 'deduplicazione' e CLONE permette di aggirare i limiti del DML e di migliorare in modo significativo entrambe le dimensioni — Elapsed Time e utilizzo degli slot — con una riduzione di performance e costi pari a circa il 50%.