Prefácio
Este post apresenta uma forma de enfrentar um desafio conhecido em sistemas de data warehouse: manter os dados sempre atualizados sem precisar recorrer a mutações em larga escala.
Na DoiT, trabalhamos com diversos clientes na construção de sistemas bem arquitetados e no uso eficiente de serviços de nuvem. O conteúdo a seguir é baseado em um caso real de cliente.
Contexto
Uma empresa SaaS oferece aos seus clientes uma plataforma analítica construída sobre o BigQuery. Para alguns desses clientes, os dados chegam como um snapshot completo, contendo todo o histórico — e não apenas as alterações incrementais desde a última atualização.
Um desses clientes envia um snapshot de 15TB, mas os dados realmente atualizados representam apenas 0,1% do total. Como não havia como receber somente as mudanças incrementais, o time precisava encontrar a forma mais confiável e eficiente — em desempenho e custo — de manter a tabela existente atualizada com os novos dados do snapshot.
Requisitos do data pipeline
A empresa e o cliente definiram um contrato de dados para que o pipeline atendesse aos requisitos técnicos e de negócio:
- Os dados recebidos são um snapshot completo de uma janela deslizante de dois anos, com cadência de chegada de seis vezes ao dia.
- Os dados são particionados por dia (cada partição tem cerca de 20GiB) e marcados com um snapshot ID (valor incremental).
- Os dados contêm registros novos (novas chaves) e registros alterados (atualizações de dados existentes).
- Configuração de expiração de partição em 2 anos.
- Registros que estão no snapshot atual, mas ausentes no novo snapshot, permanecem até a expiração da partição.
O time de produto da empresa SaaS definiu os seguintes requisitos:
- Modelagem: duas tabelas vão conter os dados existentes e os novos.
Os novos dados ficam em uma tabela chamada "staging", e os dados existentes (expostos ao cliente) ficam em uma tabela chamada "target".
- Unicidade: os dados da tabela "target" são únicos (sem chaves duplicadas).
- Atualidade: a tabela "target" é atualizada em até uma hora após a chegada do snapshot.
- Disponibilidade: o usuário final sempre recebe uma resposta para sua consulta.
O desafio da mutação
Como descreve o blog do Google a seguir, o BigQuery não foi projetado nos moldes dos bancos OLTP transacionais, que são naturalmente eficientes em mutações de grande volume.
"O BigQuery não é o único banco OLAP a ter restrições na frequência de mutações, seja explicitamente (por meio de quotas) ou implicitamente (com queda significativa de desempenho), já que esses bancos são otimizados para ingestão em larga escala e consultas analíticas, e não para processamento transacional.
Além disso, o BigQuery permite ler o estado de uma tabela em qualquer instante dos sete dias anteriores. Essa janela de retrospectiva exige manter dados que o usuário já apagou. Para viabilizar consultas em escala de forma eficiente e econômica, o BigQuery limita a frequência de mutações por meio de quotas." ( Performing large-scale mutations in BigQuery | Google Cloud Blog )
Uma substituição completa, que remove e troca o snapshot antigo pelo novo, não resolve, pois é preciso preservar os registros que existem no snapshot atual mas estão ausentes no novo snapshot.
Ou seja, é necessário comparar registros entre o snapshot atual e o novo — algo que a abordagem padrão de substituição não faz.
Para mostrar as opções de mutação e suas diferenças, vamos definir o problema com precisão, com a modelagem de dados exata e a lógica de mutação.
Modelagem de dados
Schema da tabela:
Um registro na tabela ("staging" ou "target") contém um attribute_id e um valor para um determinado produto (product_id) em uma loja (store_id) em uma data específica, além da referência ao snapshot em que existia (update_id).

Exemplo de registro:
Com base nos dados recebidos no snapshot ID 1 (update_id), a quantidade total (attribute_id = 1) de um produto (product_id = 301865) em uma loja (store_id = 2072) era 20 em 21/04/2017.
Exemplo de lógica de mutação:
A seguir, um exemplo de uma amostra de uma partição (data específica) em dois snapshots diferentes.
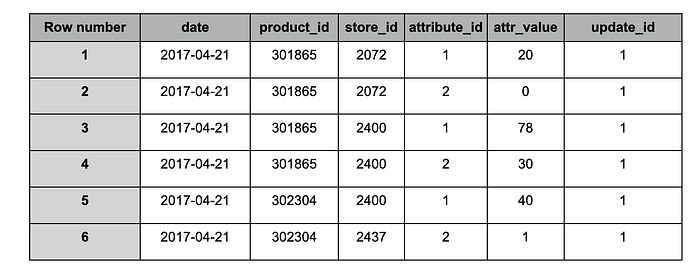
Tabela "target" após a ingestão do snapshot #1
O snapshot #2 trouxe as seguintes alterações:
1. Azul: registros atualizados (aparecem em ambos os snapshots), com valor alterado.
2. Vermelho: registro histórico (aparece apenas no snapshot #1).
3. Verde — novo registro (aparece apenas no snapshot #2).
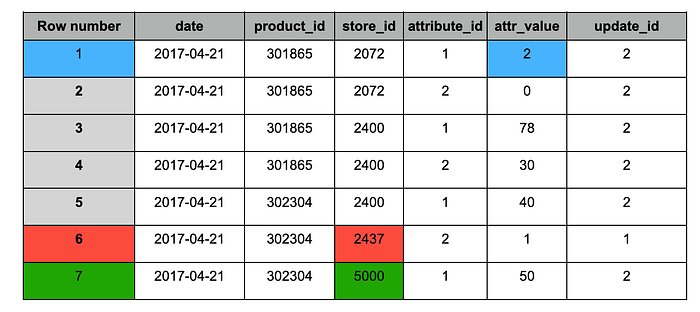
Tabela "target" após a ingestão do snapshot #2
Como o BigQuery oferece suporte ao MERGE, fazer o merge da tabela de staging com a target é a abordagem intuitiva, usando a lógica abaixo.
Lógica do merge
Esta lógica de MERGE define as mutações a serem aplicadas conforme cada caso, com base em uma chave de junção formada pelos campos: product_id, store_id, attribute_id.
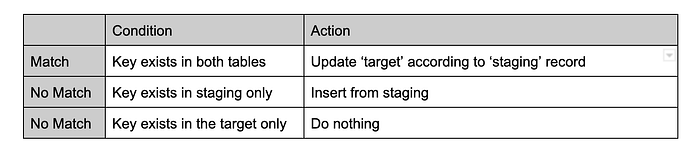
Esta é a implementação em código da lógica de MERGE:
MERGE
nw-playground.demo.merge_target T
USING
nw-playground.demo.merge_staging S
ON
T.product_Id = S.product_Id
AND T.store_Id = S.store_Id
AND T.attribute_Id = S.attribute_Id
AND T.date = S.date
WHEN MATCHED and T.date >= '2017-04-14' and T.date <= '2017-04-26'
THEN UPDATE SET T.attr_value = S.attr_value, T.update_id = S.update_id
WHEN NOT MATCHED BY TARGET and S.date >= '2017-04-14' and S.date <= '2017-04-26'
THEN
INSERT
(date,
product_Id,
store_Id,
attribute_Id,
attr_value,
update_id)
VALUES
(S.date, S.Product_id, S.store_Id, S.attribute_Id, S.attr_value, S.update_id);
Problema:
Como mencionamos, a operação MERGE tem custo elevado no BQ e apresenta limitações, exigindo shuffle e mutação dos dados existentes.
Ou seja, precisamos de uma forma de evitar o MERGE e a mutação de dados.
Abordagem de deduplicação e clone
O que vamos fazer? Em vez de fazer o merge dos registros das tabelas "staging" e "target", vamos seguir estes passos:
- Acrescentar o novo snapshot à tabela "staging".
- Deduplicar registros similares e manter o mais recente.
Deduplicação é o processo de remover registros duplicados e manter apenas um único registro. Para isso, define-se uma chave que identifique os registros similares e uma lógica para decidir qual deles manter (por exemplo, o mais recente).
3. Substituir a tabela "staging" pelos resultados da deduplicação.
4. Substituir a tabela "target" por um CLONE da tabela "staging".
"CLONE Um clone de tabela é uma cópia leve e gravável de outra tabela (chamada de tabela base). Você só é cobrado pelo armazenamento dos dados do clone que diferem da tabela base, então, inicialmente, não há custo de armazenamento para o clone . Tirando o modelo de cobrança de armazenamento e alguns metadados adicionais para a tabela base, o clone se comporta como uma tabela padrão — você pode consultá-lo, copiá-lo, excluí-lo e assim por diante. Depois de criado, o clone passa a ser independente da tabela base. Quaisquer mudanças feitas na tabela base ou no clone não são refletidas na outra. " table-clones-intro
Como vamos fazer?
- Append dos dados: usando o comando
LOADem modo "append", de modo que a tabela de staging contenha o snapshot atual e o novo. - Deduplicação: deduplicar registros similares (mesma chave) e manter o mais recente. A deduplicação não afeta registros totalmente novos nem registros que existam apenas no snapshot atual. Ela é implementada com funções de janela (Window functions), que computam valores sobre um grupo de linhas, junto com a operação
QUALIFY. A cláusulaQUALIFYpermite filtrar os resultados de uma função de janela (grupo de linhas). - Substituir "staging": usando
CREATE OR REPLACEcom base nos resultados da query de deduplicação. - Clonar "staging" para "target": usando
CREATE OR REPLACE TABLE ... CLONE.
Por que fazer assim?
Esta abordagem traz diversas vantagens em comparação ao MERGE:
1. Reduz o data shuffling: acrescentar o novo snapshot ao existente evita o shuffle entre duas tabelas.
2. Evita operações de MERGE/JOIN: a deduplicação é feita por uma função de janela que usa a cláusula PARTITION BY, dividindo as linhas de entrada em partições separadas, sobre as quais a função de janela é avaliada de forma independente.
3. Evita mutação: novas tabelas são criadas ou clonadas, contornando os limites de quota de mutação do BigQuery.
Exemplo da lógica de append e deduplicação:
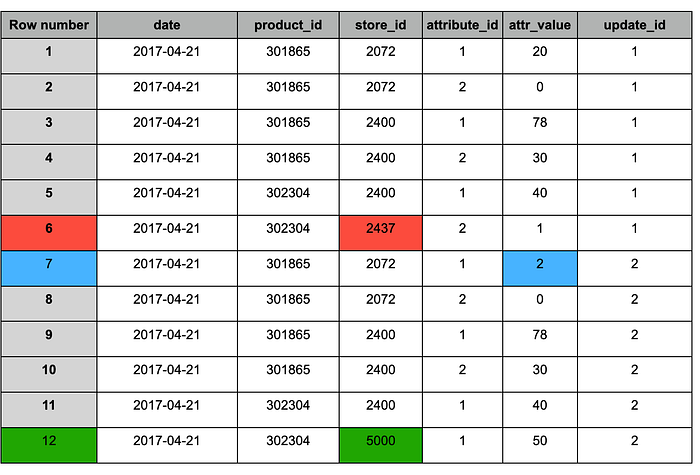
Tabela de staging após o append do novo snapshot (#2)
De forma semelhante ao resultado do MERGE, a tabela após a deduplicação contém as seguintes alterações:
1. Azul — registros atualizados (aparecem em ambos os snapshots), com valor alterado.
2. Vermelho — registros antigos que devem ser preservados (aparecem apenas no snapshot #1).
3. Verde — novo registro (aparece apenas no snapshot #2).
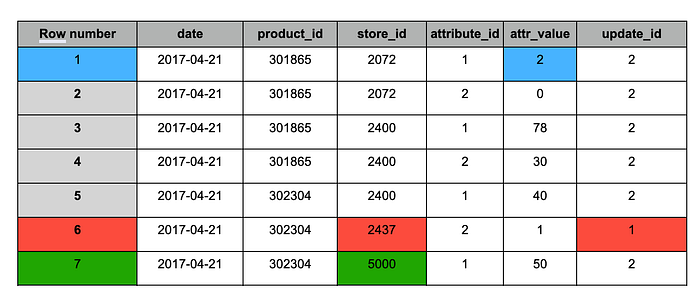
Tabela de staging após a deduplicação
Quando o próximo snapshot chegar, ele seguirá o mesmo processo descrito acima.
Exemplos de código:
O código a seguir cria uma nova tabela de staging a partir dos resultados da deduplicação, substituindo a tabela existente. Ele utiliza a cláusula QUALIFY e adiciona um row number a cada registro com chave similar — sendo que o 1º registro (rownum=1) é o mais recente.
CREATE OR REPLACE TABLE
`nw-playground.demo.dedup_staging`
(date DATE, product_id INT64,
store_id INT64, attribute_id INT64,
attr_value INT64, update_id INT64)
PARTITION BY
date
CLUSTER BY
product_id,
store_id AS
SELECT
date, product_id, store_id, attribute_id, attr_value, update_id
FROM
`nw-playground.demo.dedup_staging`
WHERE
date >= '2017-04-14' AND date <= '2017-04-26'
QUALIFY ROW_NUMBER()
OVER(PARTITION BY date, product_id, store_id, attribute_id
ORDER BY update_id DESC ) = 1;
CREATE OR REPLACE TABLE
`nw-playground.nw_demo.dedup_target`
CLONE `nw-playground.nw_demo.dedup_staging`;
Dados de teste e resultados
Os testes foram feitos com 7,8 bilhões de registros (350GiB) distribuídos em 13 partições, com cerca de 3 milhões de diferenças (todos os tipos de mudança) entre "staging" e "target". Os testes foram executados no modelo de cobrança on-demand.
No caso do MERGE, a tabela "staging" continha apenas o novo snapshot, e a "target" tinha o snapshot existente. Já no caso da deduplicação, a tabela de staging continha o snapshot existente mais o novo, e a "target" era um clone do 1º snapshot da staging.
Comparação dos resultados
A tabela a seguir mostra a comparação dos resultados:

Resumo comparativo dos detalhes de execução
Comparando os planos de execução, fica claro que a duração e o uso de slots do teste com MERGE são o dobro dos do DEDUPLICATE:

Duração e uso de slots da operação principal
Comparação de custos
Modelo de cobrança on-demand:
O custo é semelhante entre os testes, já que a quantidade de dados escaneados é a mesma. Em uma carga completa, considerando 30TB em 2 snapshots, fica em torno de US$ 187 (US$ 6,25 por 1TiB).
BigQuery Editions:
O novo modelo de cobrança lançado pelo Google em abril/23 é baseado em precificação por capacidade (pagamento por slot/hora) e tem três edições. Para estimar o custo de uma carga em produção, podemos calcular um snapshot completo aplicando um fator de 56 sobre o teste realizado (730 dias-partições em 2 anos; 730/13=56).
A estimativa de custo não é exata, pois há diferentes configurações e commitments que podem ser aplicados. O objetivo aqui é mostrar a diferença entre as duas opções.
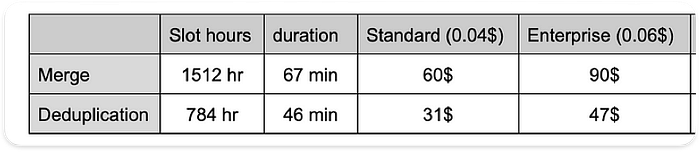
Comparação da estimativa de custo entre as edições do BigQuery (preços nos EUA)
Apêndice
Existem várias formas de implementar a deduplicação (usando ROWNUM ou GROUP BY). Os testes com ROWNUM tiveram desempenho semelhante ao da cláusula QUALIFY, sendo que QUALIFY é um comando mais limpo. Já o uso de "Group By" resultou em desempenho pior, equivalente ao do Merge.
Há ainda outra forma eficiente de implementação: stored procedures para Apache Spark, que será abordada no próximo post…
Como mostramos no caso de uso, trata-se de uma mutação em larga escala que depende de uma lógica de join com os dados existentes. A melhor forma de lidar com isso é evitar modificações nos dados.
A combinação de deduplicação com CLONE evita as limitações de DML e melhora significativamente as duas dimensões — tempo decorrido e uso de slots —, resultando em uma redução de cerca de 50% em desempenho e custo.