Vorwort
Dieser Blogbeitrag stellt einen Ansatz vor, mit dem sich eine bekannte Herausforderung in Data-Warehouse-Systemen lösen lässt: Daten aktuell zu halten, ohne dabei umfangreiche Mutationen anzustoßen.
Bei DoiT arbeiten wir mit vielen Kunden am Aufbau sauber architekturierter Systeme und an der effizienten Nutzung von Cloud-Diensten. Der folgende Beitrag basiert auf einem konkreten Kundenprojekt.
Hintergrund
Ein SaaS-Unternehmen bietet seinen Kunden eine Analyseplattform auf Basis von BigQuery. Bei einigen Kunden werden die Daten als vollständiger Snapshot übermittelt – inklusive der gesamten Historie, nicht nur der inkrementellen Änderungen seit dem letzten Update.
Einer dieser Kunden liefert einen Snapshot von 15 TB, wobei die tatsächlich aktualisierten Daten lediglich 0,1 % ausmachen. Da es keine Möglichkeit gab, ausschließlich die inkrementellen Änderungen zu beziehen, stand das Team vor der Aufgabe, einen möglichst zuverlässigen sowie performance- und kostenseitig effizienten Weg zu finden, um die bestehende Tabelle mit den neuen Snapshot-Daten aktuell zu halten.
Anforderungen an die Datenpipeline
Unternehmen und Kunde haben einen Datenvertrag definiert, der die fachlichen und technischen Anforderungen an die Datenpipeline festlegt:
- Die eingehenden Daten sind ein vollständiger Snapshot eines gleitenden Zwei-Jahres-Fensters und treffen sechsmal täglich ein.
- Die Daten sind nach Tag partitioniert (Partitionsgröße ca. 20 GiB) und mit einer Snapshot-ID (inkrementeller Wert) gekennzeichnet.
- Die Daten enthalten neue Datensätze (neue Schlüssel) und geänderte Datensätze (Updates bestehender Daten).
- Die Partitionsablaufkonfiguration beträgt 2 Jahre.
- Datensätze, die im aktuellen Snapshot vorhanden sind, im neuen jedoch fehlen, bleiben bis zum Partitionsablauf erhalten.
Das Produktteam des SaaS-Unternehmens hat folgende Anforderungen festgelegt:
- Modellierung: Zwei Tabellen enthalten die bestehenden und die neuen Daten.
Die neuen Daten liegen in einer Tabelle namens "staging", die bestehenden Daten (die dem Kunden bereitgestellt werden) in einer Tabelle namens "target".
- Eindeutigkeit: Die Daten in der "target"-Tabelle sind eindeutig (keine doppelten Schlüssel).
- Aktualität: Die "target"-Tabelle wird innerhalb einer Stunde nach Eintreffen des Snapshots aktualisiert.
- Verfügbarkeit: Endnutzer erhalten stets eine Antwort auf ihre Anfragen.
Die Mutations-Herausforderung
Wie der folgende Beitrag im Google-Blog beschreibt, ist BigQuery anders aufgebaut als OLTP-Datenbanken, die von Haus aus effizient mit umfangreichen Mutationen umgehen.
"BigQuery steht unter den OLAP-Datenbanken nicht allein damit, in der Mutationsfrequenz beschränkt zu sein – sei es explizit (über Quotas) oder implizit (durch deutliche Performance-Einbußen). Diese Datenbanktypen sind auf Massen-Ingestion und analytische Abfragen optimiert, nicht auf Transaktionsverarbeitung.
Darüber hinaus erlaubt BigQuery, den Zustand einer Tabelle zu jedem beliebigen Zeitpunkt innerhalb der vergangenen sieben Tage zu lesen. Dieses Look-back-Fenster setzt voraus, dass auch bereits gelöschte Daten weiterhin vorgehalten werden. Um kosteneffiziente und performante Abfragen im großen Maßstab zu ermöglichen, begrenzt BigQuery die Mutationsfrequenz über Quotas." (Performing large-scale mutations in BigQuery | Google Cloud Blog)
Ein vollständiges Ersetzen, bei dem der alte Snapshot durch den neuen ausgetauscht wird, reicht hier nicht aus, denn Datensätze, die zwar im aktuellen, aber nicht mehr im neuesten Snapshot vorkommen, müssen erhalten bleiben.
Das heißt: Es ist ein Vergleich zwischen den Datensätzen des bestehenden und des neuen Snapshots erforderlich – etwas, das ein klassischer Ersetzungsansatz nicht leistet.
Um die Mutationsoptionen und ihre Unterschiede gegenüberzustellen, definieren wir das Problem mit der konkreten Datenmodellierung und Mutationslogik präzise.
Datenmodellierung
Tabellenschema:
Ein Datensatz in einer Tabelle ("staging" oder "target") enthält eine attribute_id und einen Wert für ein bestimmtes Produkt (product_id) in einer Filiale (store_id) zu einem bestimmten Datum sowie die Referenz auf den Snapshot, in dem er existierte (update_id).

Beispiel für einen Datensatz:
Auf Grundlage der Daten aus Snapshot-ID 1 (update_id) betrug die Gesamtmenge (attribute_id = 1) eines Produkts (product_id = 301865) in einer Filiale (store_id = 2072) am 21.04.2017 den Wert 20.
Beispiel für die Mutationslogik:
Im Folgenden sehen Sie eine Stichprobe aus einer Partition (bestimmtes Datum) aus zwei verschiedenen Snapshots.
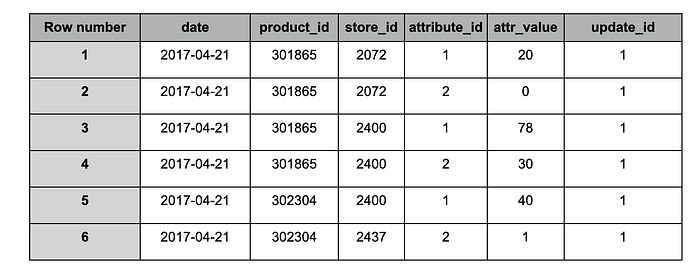
"target"-Tabelle nach dem Ingest von Snapshot #1
Snapshot #2 enthielt folgende Änderungen:
1. Blau: aktualisierte Datensätze (in beiden Snapshots vorhanden), Wert geändert.
2. Rot: historischer Datensatz (nur in Snapshot #1 vorhanden).
3. Grün: neuer Datensatz (nur in Snapshot #2 vorhanden).
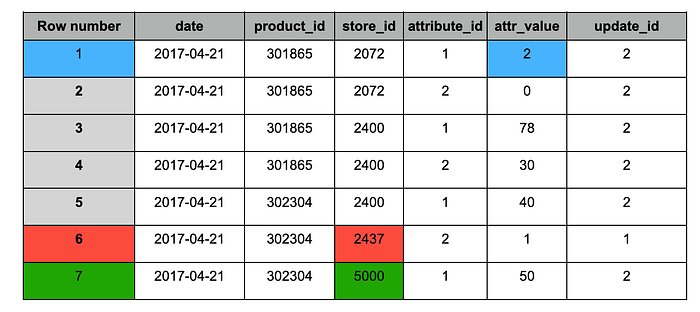
"target"-Tabelle nach dem Ingest von Snapshot #2
Da BigQuery MERGE unterstützt, liegt es nahe, die Staging- mit der Target-Tabelle zu mergen – nach folgender Logik.
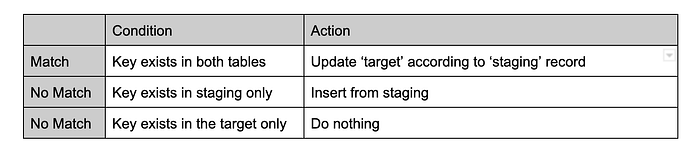
Merge-Logik
Diese MERGE-Logik definiert die anzuwendenden Mutationen je nach Fall, basierend auf einem zusammengesetzten Schlüssel aus den Feldern: product_id, store_id, attribute_id.
So sieht die Code-Implementierung der MERGE-Logik aus:
MERGE
nw-playground.demo.merge_target T
USING
nw-playground.demo.merge_staging S
ON
T.product_Id = S.product_Id
AND T.store_Id = S.store_Id
AND T.attribute_Id = S.attribute_Id
AND T.date = S.date
WHEN MATCHED and T.date >= '2017-04-14' and T.date <= '2017-04-26'
THEN UPDATE SET T.attr_value = S.attr_value, T.update_id = S.update_id
WHEN NOT MATCHED BY TARGET and S.date >= '2017-04-14' and S.date <= '2017-04-26'
THEN
INSERT
(date,
product_Id,
store_Id,
attribute_Id,
attr_value,
update_id)
VALUES
(S.date, S.Product_id, S.store_Id, S.attribute_Id, S.attr_value, S.update_id);
Problem:
Wie oben erwähnt, ist die MERGE-Operation in BQ teuer und unterliegt Einschränkungen, denn sie erzwingt Shuffling und eine Mutation der bestehenden Daten.
Wir brauchen also einen Weg, MERGE und Datenmutation zu vermeiden.
Ansatz: Deduplizieren und Clonen
Was machen wir? Statt die Datensätze von "staging" und "target" zu mergen, gehen wir folgendermaßen vor:
- Den neuen Snapshot an die "staging"-Tabelle anhängen.
- Ähnliche Datensätze deduplizieren und nur den neuesten behalten.
Deduplizierung ist ein Verfahren, um doppelte Datensätze zu entfernen, sodass nur ein einziger Datensatz übrig bleibt. Dazu wird ein Datensatzschlüssel zur Identifikation ähnlicher Datensätze definiert, kombiniert mit einer Logik, die festlegt, welcher der Duplikate erhalten bleibt (z. B. der neueste).
3. Die "staging"-Tabelle durch das Deduplizierungsergebnis ersetzen.
4. Die "target"-Tabelle durch einen CLONE der "staging"-Tabelle ersetzen.
"CLONE: Ein Tabellen-Clone ist eine ressourcenschonende, schreibbare Kopie einer anderen Tabelle (der sogenannten Basistabelle). Berechnet wird Ihnen nur der Datenspeicher im Clone, der sich von der Basistabelle unterscheidet – anfangs entstehen daher keine Speicherkosten für einen Tabellen-Clone. Abgesehen vom Abrechnungsmodell für den Speicher und einigen zusätzlichen Metadaten der Basistabelle verhält sich ein Tabellen-Clone wie eine reguläre Tabelle – Sie können ihn abfragen, kopieren, löschen und so weiter. Nach der Erstellung ist ein Tabellen-Clone unabhängig von der Basistabelle. Änderungen an der Basistabelle oder am Clone wirken sich nicht auf die jeweils andere Tabelle aus." table-clones-intro
Wie machen wir das?
- Daten anhängen: per
LOAD-Befehl im "append"-Modus, sodass die Staging-Tabelle den aktuellen und den neuen Snapshot enthält. - Deduplizierung: ähnliche Datensätze (gleicher Schlüssel) deduplizieren und davon den neuesten behalten. Vollständig neue Datensätze oder solche, die nur im aktuellen Snapshot vorkommen, bleiben unberührt. Umgesetzt wird die Deduplizierung über Window-Funktionen, die Werte über eine Gruppe von Zeilen hinweg berechnen, in Kombination mit der
QUALIFY-Operation. DieQUALIFY-Klausel filtert die Ergebnisse einer Window-Funktion (Zeilengruppe). - "staging" ersetzen: per
CREATE OR REPLACEauf Basis der Deduplizierungs-Abfrageergebnisse. - "staging" in "target" klonen: per
CREATE OR REPLACE TABLE ... CLONE.
Warum machen wir das?
Gegenüber dem MERGE-Ansatz ergeben sich daraus mehrere Vorteile:
1. Weniger Daten-Shuffling: Das Anhängen des neuen Snapshots an den bestehenden vermeidet Shuffling zwischen zwei Tabellen.
2. Keine MERGE/JOIN-Operation: Die Deduplizierung erfolgt über eine Window-Funktion mit PARTITION BY-Klausel, die die Eingabezeilen in separate Partitionen aufteilt, über die die Window-Funktion unabhängig ausgewertet wird.
3. Keine Mutation: Es werden neue Tabellen erstellt oder geklont. Damit umgehen Sie die Mutations-Quotenlimits von BigQuery.
Beispiel für die Append- und Deduplizierungslogik:
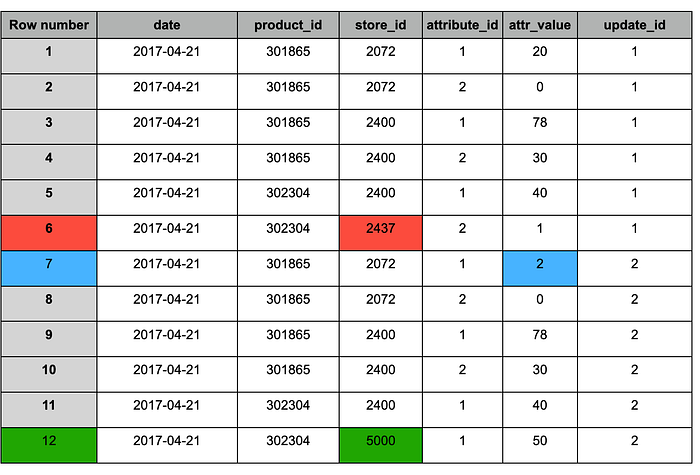
Staging-Tabelle nach dem Anhängen des neuen Snapshots (#2)
Analog zum MERGE-Ergebnis enthält die Tabelle nach der Deduplizierung folgende Änderungen:
1. Blau – aktualisierte Datensätze (in beiden Snapshots vorhanden), Wert geändert.
2. Rot – alte Datensätze, die erhalten bleiben sollen (nur in Snapshot #1 vorhanden).
3. Grün – neuer Datensatz (nur in Snapshot #2 vorhanden).
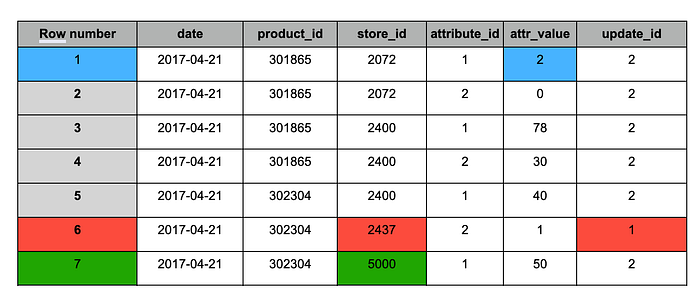
Staging-Tabelle nach der Deduplizierung
Beim Eintreffen des nächsten Snapshots wird derselbe Prozess erneut durchlaufen.
Code-Beispiele
Der folgende Code erstellt aus den Deduplizierungsergebnissen eine neue Staging-Tabelle, die die bestehende ersetzt. Dabei kommt die QUALIFY-Klausel zum Einsatz, die jedem Datensatz mit gleichem Schlüssel eine Zeilennummer zuweist – wobei der erste Datensatz (rownum = 1) der neueste ist.
CREATE OR REPLACE TABLE
`nw-playground.demo.dedup_staging`
(date DATE, product_id INT64,
store_id INT64, attribute_id INT64,
attr_value INT64, update_id INT64)
PARTITION BY
date
CLUSTER BY
product_id,
store_id AS
SELECT
date, product_id, store_id, attribute_id, attr_value, update_id
FROM
`nw-playground.demo.dedup_staging`
WHERE
date >= '2017-04-14' AND date <= '2017-04-26'
QUALIFY ROW_NUMBER()
OVER(PARTITION BY date, product_id, store_id, attribute_id
ORDER BY update_id DESC ) = 1;
CREATE OR REPLACE TABLE
`nw-playground.nw_demo.dedup_target`
CLONE `nw-playground.nw_demo.dedup_staging`;
Testdaten und Ergebnisse
Getestet wurde mit 7,8 Milliarden Datensätzen (350 GiB), verteilt auf 13 Partitionen, mit ca. 3 Mio. Unterschieden (alle Änderungstypen) zwischen "staging" und "target". Die Tests liefen im On-Demand-Abrechnungsmodell.
Im MERGE-Fall enthielt die "staging"-Tabelle nur den neuen Snapshot und die "target"-Tabelle den bestehenden Snapshot. Im Deduplizierungsfall hingegen enthielt die Staging-Tabelle den bestehenden und den neuen Snapshot, und "target" war ein Clone des ersten Staging-Snapshots.
Vergleich der Ergebnisse
Die folgende Tabelle zeigt den Vergleich der Ergebnisse:

Zusammenfassender Vergleich der Ausführungsdetails
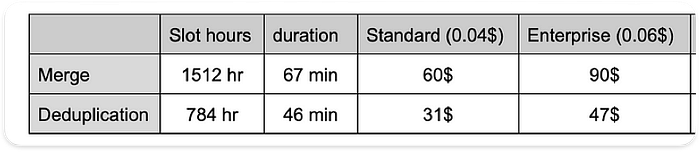
Im Vergleich der Ausführungspläne wird deutlich: Dauer und Slot-Auslastung liegen beim MERGE-Test doppelt so hoch wie bei DEDUPLICATE:

Dauer und Slot-Auslastung der Hauptoperation
Kostenvergleich
On-Demand-Abrechnungsmodell
Die Kosten sind zwischen den Tests vergleichbar, da dieselbe Datenmenge gescannt wird. Bei vollständiger Last erreichen sie auf Basis von 30 TB für 2 Snapshots rund 187 $ (6,25 $ pro 1 TiB).
BigQuery Editions
Das neue Abrechnungsmodell, das Google im April 2023 eingeführt hat, basiert auf Capacity Pricing (Bezahlung pro Slot/Stunde) und umfasst drei Editionen. Für die Produktivlast lässt sich ein vollständiger Snapshot-Load mit dem Faktor 56 gegenüber unserem Test hochrechnen (730 Tagespartitionen in 2 Jahren; 730/13 = 56).
Die Schätzung ist nicht exakt, da auch unterschiedliche Konfigurationen und Commitments einfließen können. Sie zeigt aber den Unterschied zwischen den beiden Optionen.
Vergleich der geschätzten Kosten zwischen den BigQuery Editions (US-Pricing)
Anhang
Es gibt mehrere Wege, eine Deduplizierung umzusetzen (z. B. mit ROWNUM oder Group By). Eine Deduplizierung mit ROWNUM lieferte ähnliche Ergebnisse wie die QUALIFY-Klausel – QUALIFY ist allerdings die schlankere Variante. "Group By" schnitt schlechter ab und lag auf dem Niveau der Merge-Ergebnisse.
Eine weitere effiziente Variante könnten Stored Procedures für Apache Spark sein – dazu mehr im nächsten Blogbeitrag …
Wie im Use Case beschrieben, geht es um eine umfangreiche Mutation, die auf einer Join-Logik mit den bestehenden Daten beruht. Der bevorzugte Lösungsweg besteht darin, Datenmodifikationen ganz zu vermeiden.
Mit der Kombination aus "Deduplizierung" und CLONE umgehen Sie DML-Beschränkungen und verbessern beide Dimensionen – Elapsed Time und Slot-Auslastung – deutlich. Das Ergebnis: rund 50 % weniger Aufwand bei Performance und Kosten.