
Photo by eMotion Tech on Unsplash
はじめに
本記事では、データウェアハウスでよく知られた課題、すなわち「データの鮮度を保ちながら大規模なミューテーションを避ける」というテーマへの対処法をご紹介します。
DoiTでは多くのお客様とともに、Well-Architectedなシステム構築やクラウドサービスの効率的な活用に取り組んでおり、本記事はその中で得られたお客様事例に基づいています。
背景
あるSaaS企業は、BigQuery上に構築した分析プラットフォームを顧客に提供しています。一部の顧客については、最新の差分のみではなく、全履歴を含む完全なスナップショットとしてデータを受領しています。
そのうちの1社からは15TBのスナップショットが届きますが、実際に更新されているデータはわずか0.1%にすぎません。差分のみを取得する手段がないため、新しいスナップショットで既存テーブルを更新する際に、性能とコストの両面で最も信頼性が高く効率的な方法を見つけることが、チームに課せられた課題でした。
データパイプラインの要件
同社と顧客は、ビジネス要件と技術要件を満たすために、データパイプラインのデータコントラクトを次のように定義しました。
- 受信データは2年間のスライディングウィンドウを対象とした完全なスナップショットで、1日6回到着する。
- データは日付でパーティショニングされており(パーティションサイズは約20GiB)、スナップショットID(増分値)が付与される。
- データには新規データ(新しいキー)と変更データ(既存データの更新)が含まれる。
- パーティションの有効期限は2年に設定。
- 現スナップショットには存在するが新スナップショットには存在しないレコードは、パーティション有効期限まで保持する。
SaaS企業のプロダクトチームは、次の要件を定義しました。
- モデリング:既存データと新規データを保持する2つのテーブルを使用する。
新規データは「staging」というテーブルに、既存データ(顧客に公開するデータ)は「target」というテーブルに格納します。
- 一意性:「target」テーブルのデータは一意である(キーの重複なし)。
- 鮮度:「target」テーブルはスナップショット到着から1時間以内に更新される。
- 可用性:エンドユーザーはクエリリクエストに対して常に応答を得られる。
ミューテーションという難題
以下のGoogleブログで述べられているとおり、BigQueryは大規模なミューテーションを得意とするOLTP(トランザクション処理)型DBとは異なる設計思想で作られています。
「BigQueryに限らず、OLAP系データベースはミューテーション頻度に対して制約を持っています。これは明示的にはクォータとして、暗黙的には大幅な性能劣化として現れます。これらのデータベースはトランザクション処理ではなく、大規模な取り込みと分析クエリに最適化されているためです。さらにBigQueryでは、過去7日間の任意の時点におけるテーブルの状態を読み取ることができます。このルックバック期間を実現するには、ユーザーがすでに削除したデータも保持しておく必要があります。コスト効率と性能を両立した大規模クエリを実現するため、BigQueryはクォータによってミューテーション頻度を制限しています。」 ( Performing large-scale mutations in BigQuery | Google Cloud Blog )
古いスナップショットを削除して新しいスナップショットで丸ごと置き換える方法では、現スナップショットには存在するが最新スナップショットには存在しないレコードを保持する必要があるため、要件を満たせません。
つまり、既存スナップショットと新スナップショットのレコードを比較する必要がありますが、単純な置き換えではそうした比較は行われません。
各方式の違いを明確にするため、データモデリングとミューテーションロジックを正確に定義しながら、問題を整理していきましょう。
データモデリング
テーブルスキーマ:
テーブル(「staging」または「target」)の1レコードには、特定の店舗(store_id)における特定の商品(product_id)について、ある日付の属性(attribute_id)とその値、およびそのレコードが属するスナップショットの参照(update_id)が含まれます。

レコードの例:
スナップショットID 1(update_id)で受信したデータによると、店舗(store_id = 2072)における商品(product_id = 301865)の総数量(attribute_id = 1)は、2017–04–21時点で20でした。
ミューテーションロジックの例:
以下は、2つの異なるスナップショットから取り出した同一パーティション(特定日付)のサンプルです。
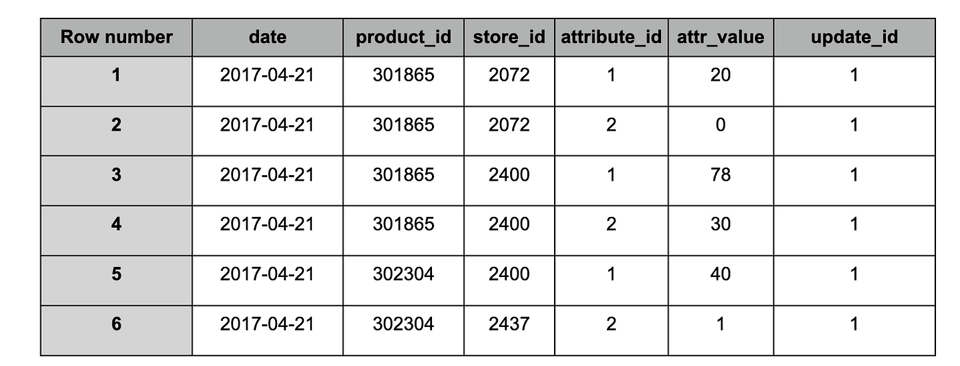
スナップショット#1取り込み後の「target」テーブル
スナップショット#2には、次の変更が含まれていました。
1. 青:更新されたレコード(両スナップショットに存在し、値が変化)。
2. 赤:過去のレコード(スナップショット#1のみに存在)。
3. 緑:新規レコード(スナップショット#2のみに存在)。
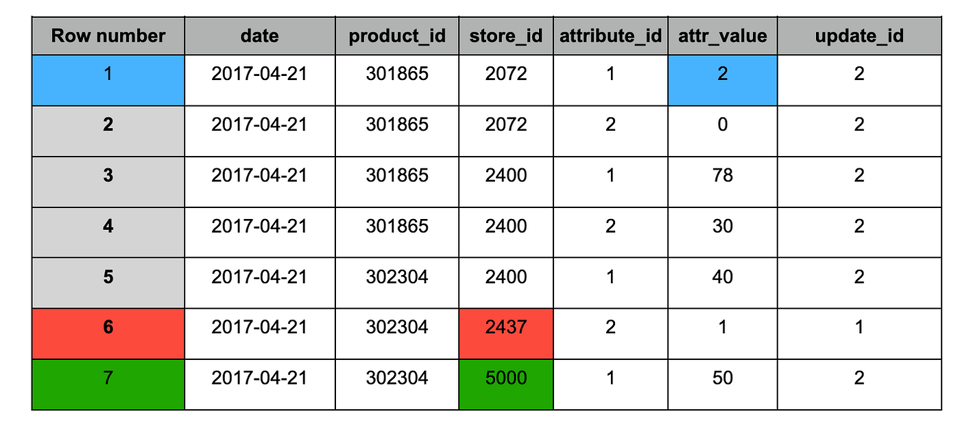
スナップショット#2取り込み後の「target」テーブル
BigQueryはMERGEをサポートしているため、stagingテーブルとtargetテーブルをマージするのが直感的なアプローチです。次のロジックを使用します。
マージのロジック
このMERGEロジックは、product_id、store_id、attribute_idで構成される結合キーに基づき、ケースごとに適用するミューテーションを定義します。
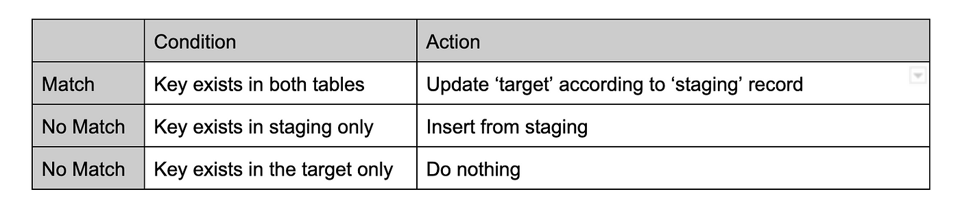
MERGEロジックの実装コードは次のとおりです。
MERGEnw-playground.demo.merge_target TUSINGnw-playground.demo.merge_staging SON T.product_Id = S.product_Id AND T.store_Id = S.store_Id AND T.attribute_Id = S.attribute_Id AND T.date = S.date WHEN MATCHED and T.date >= '2017-04-14' and T.date <= '2017-04-26' THEN UPDATE SET T.attr_value = S.attr_value, T.update_id = S.update_id WHEN NOT MATCHED BY TARGET and S.date >= '2017-04-14' and S.date <= '2017-04-26' THENINSERT (date, product_Id, store_Id, attribute_Id, attr_value, update_id)VALUES (S.date, S.Product_id, S.store_Id, S.attribute_Id, S.attr_value, S.update_id);問題点:
前述のとおり、BigQueryのMERGEはコストが非常に高く、既存データのシャッフルとミューテーションを伴うという制約があります。
そこで、MERGEとデータミューテーションを回避する方法を考える必要があります。
重複排除とCLONEによるアプローチ
何をするのか?
「staging」と「target」のレコードをマージする代わりに、次のステップを実行します。
- 新しいスナップショットを「staging」テーブルに追記する。
- 類似レコードを重複排除し、最新のレコードのみを残す。
重複排除(Deduplication) とは、重複したレコードを取り除き、1件だけを残す処理です。類似レコードを識別するためのレコードキーと、重複したレコードのうちどれを残すかを決めるロジック(例:最新レコードを残す)を設定することで実現します。 3. 重複排除の結果で「staging」テーブルを置き換える。 4. 「target」テーブルを「staging」テーブルのCLONEで置き換える。
「CLONE テーブルクローンとは、別のテーブル(ベーステーブル)の軽量で書き込み可能なコピーです。テーブルクローンのうちベーステーブルと差分のあるデータストレージに対してのみ課金されるため、作成直後のストレージコストはゼロです。ストレージの課金モデルとベーステーブルに関する追加メタデータを除けば、テーブルクローンは標準テーブルとほぼ同じで、クエリの実行、コピー作成、削除などが可能です。テーブルクローンを作成した時点で、ベーステーブルからは独立した存在となります。ベーステーブルとテーブルクローンのいずれかに加えた変更は、もう一方には反映されません。」 table-clones-intro
どのように行うのか?
- データの追記:
LOADコマンドを「append」モードで実行し、stagingテーブルに現スナップショットと新スナップショットの両方を保持する。 - 重複排除:類似レコード(同一キー)を重複排除し、最新のレコードのみを残す。完全な新規レコードや現スナップショットのみに存在するレコードは影響を受けない。重複排除は、行のグループに対して値を計算する「ウィンドウ関数」と
QUALIFYを使って実装する。QUALIFY句はウィンドウ関数(行のグループ)の結果をフィルタリングできる。 - 「staging」の置き換え:重複排除クエリの結果をもとに
CREATE OR REPLACEを実行する。 - 「staging」を「target」へクローン:
CREATE OR REPLACE TABLE ... CLONEを使用する。
なぜそれを行うのか?
このアプローチには、MERGE方式と比べて次のような利点があります。
1. データシャッフルの削減:新しいスナップショットを既存のものに追記することで、2つのテーブル間のシャッフルを回避できます。
2. MERGE/JOIN操作の回避:重複排除はPARTITION BY句を使ったウィンドウ関数で実装されており、入力行を独立したパーティションに分割し、その単位でウィンドウ関数を独立に評価します。
3. ミューテーションの回避:新しいテーブルを作成またはクローンするため、BigQueryのミューテーションクォータの制限にも引っかかりません。
追記と重複排除ロジックの例:
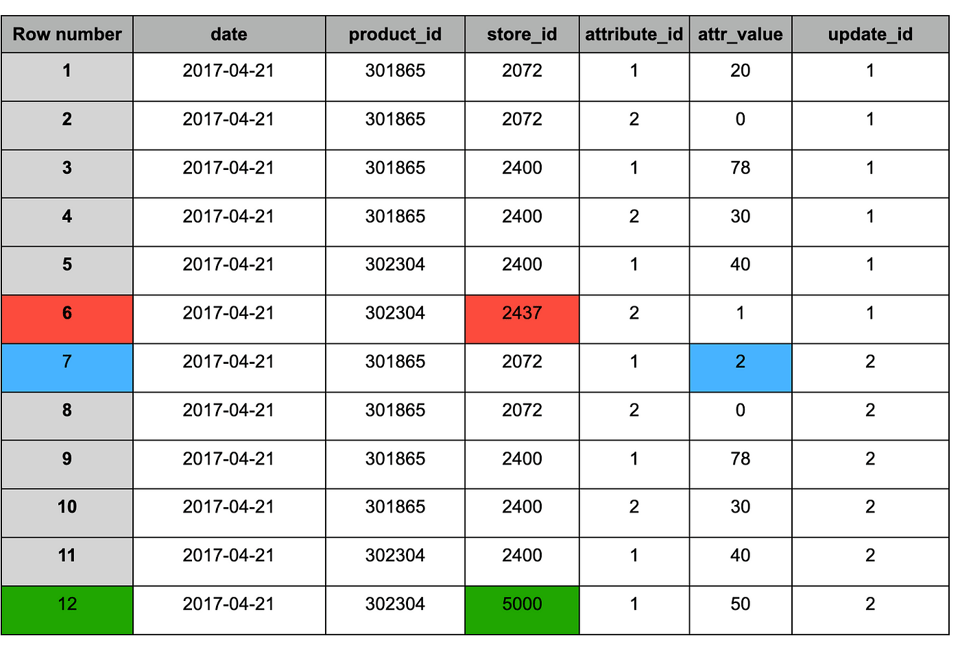
新しいスナップショット(#2)を追記した後のstagingテーブル
MERGEの結果と同様に、重複排除後のテーブルには次の変更が反映されます。
1. 青 — 更新されたレコード(両スナップショットに存在し、値が変化)。
2. 赤 — 残すべき古いレコード(スナップショット#1のみに存在)。
3. 緑 — 新規レコード(スナップショット#2のみに存在)。
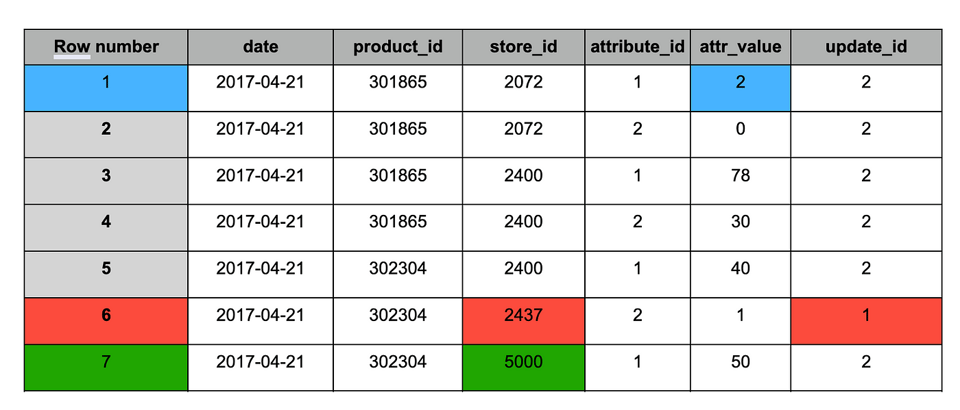
重複排除後のstagingテーブル
次のスナップショットが到着した際も、同じプロセスを繰り返します。
コード例
次のコードでは、QUALIFY句で同一キーを持つレコードに行番号を付与し(rownum=1のレコードが最新)、重複排除の結果をもとに新しいstagingテーブルを作成して既存のテーブルを置き換えます。
CREATE OR REPLACE TABLE `nw-playground.demo.dedup_staging` (date DATE, product_id INT64, store_id INT64, attribute_id INT64, attr_value INT64, update_id INT64)PARTITION BY dateCLUSTER BY product_id, store_id ASSELECT date, product_id, store_id, attribute_id, attr_value, update_idFROM `nw-playground.demo.dedup_staging`WHERE date >= '2017-04-14' AND date <= '2017-04-26' QUALIFY ROW_NUMBER() OVER(PARTITION BY date, product_id, store_id, attribute_id ORDER BY update_id DESC ) = 1;
CREATE OR REPLACE TABLE`nw-playground.nw_demo.dedup_target`CLONE `nw-playground.nw_demo.dedup_staging`;テストデータと結果
テストは、「staging」と「target」の間に約300万件の差分(あらゆる種類の変更を含む)を持つ、13パーティションに分散された78億件のレコード(350GiB)を対象に実施しました。テストはオンデマンド課金モデルで実行しています。
MERGEケースでは、「staging」テーブルには新しいスナップショットのみが入っており、「target」テーブルには既存のスナップショットがありました。一方、重複排除ケースでは、stagingテーブルに既存と新規の両スナップショットが入っており、「target」はstagingの初回スナップショットのクローンとなっています。
結果の比較
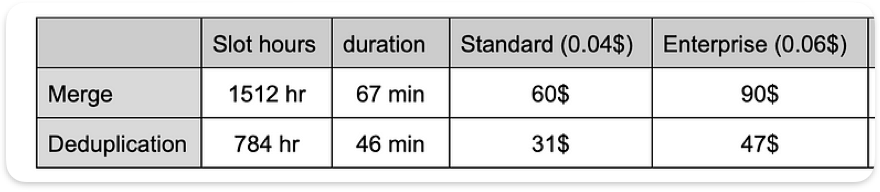
結果の比較は次の表のとおりです。

実行詳細サマリーの比較
実行プランを比べると、MERGEテストの実行時間とスロット使用量が、DEDUPLICATEのおよそ2倍になっていることがはっきり分かります。

主要操作の実行時間とスロット使用量
コスト比較
オンデマンド課金モデル
同じデータサイズをスキャンするため、コストはテスト間でほぼ同等です。30TB×2スナップショットを基準にすると、フルロードで約187ドル(1TiBあたり6.25ドル)に達します。
BigQuery Editions
2023年4月にGoogleが導入した新しい課金モデルはキャパシティ料金(スロット/時間あたりの従量課金)に基づいており、3つのエディションが用意されています。本番環境のロードコストを試算する際は、今回のテストの56倍(2年間で730日分のパーティション、730/13=56)を係数として、フルスナップショットのロードを推定できます。
適用される構成やcommitmentsはケースごとに異なるため、このコスト試算はあくまで目安です。両者の差を示すことが主な目的です。
BigQuery Editionsの推定コスト比較(米国料金)
付録
重複排除の実装方法には、ROWNUMやGroup Byを使うものなど複数の選択肢があります。ROWNUMによる重複排除はQUALIFY句と同等の性能を示しましたが、QUALIFYのほうが記述がシンプルです。「Group By」を使った場合は性能が劣化し、Mergeと同等の結果となりました。
もう1つの効率的な実装手段としてApache Spark向けのストアドプロシージャがあります。こちらは次の記事で取り上げる予定です…
本ユースケースで取り上げたのは、既存データとの結合ロジックを伴う大規模なミューテーションです。これに対処する最善の方法は、データそのものへの変更を避けることです。
「重複排除」とCLONEを組み合わせれば、DMLの制約を回避でき、Elapsed Timeとスロット使用量の両面で大きく改善します。結果として、性能とコストの両方で約50%の削減を実現しました。