
Foto de eMotion Tech en Unsplash
Prefacio
En este artículo te mostramos una forma de resolver un reto conocido en los sistemas de data warehouse: mantener los datos frescos y actualizados sin recurrir a mutaciones masivas.
En DoiT acompañamos a muchos clientes en el diseño de sistemas bien arquitectados, aprovechando los servicios de nube de forma eficiente. Lo que sigue nace de la historia de uno de ellos.
Contexto
Una empresa SaaS ofrece a sus clientes una plataforma analítica construida sobre BigQuery. En el caso de algunos clientes, los datos llegan como un snapshot completo, con todo el historial y no únicamente los cambios incrementales desde la última actualización.
Uno de esos clientes envía un snapshot de 15 TB, aunque los datos realmente actualizados representan apenas el 0,1%. Como no había manera de obtener únicamente los cambios incrementales, el equipo se enfrentaba al reto de encontrar la forma más confiable y eficiente, en rendimiento y costo, de mantener la tabla existente al día con cada nuevo snapshot.
Requisitos del data pipeline
La empresa y el cliente definieron un contrato de datos para que el pipeline cumpliera los requisitos de negocio y técnicos:
- Los datos entrantes son un snapshot completo de una ventana deslizante de dos años, con una frecuencia de llegada de seis veces al día.
- Los datos están particionados por día (cada partición pesa cerca de 20 GiB) y se marcan con un ID de snapshot (un valor incremental).
- Los datos incluirán registros nuevos (claves nuevas) y registros modificados (actualizaciones de datos existentes).
- Configuración de expiración de partición a 2 años.
- Los registros que estén en el snapshot actual pero no aparezcan en el nuevo se conservan hasta que expire la partición.
El equipo de producto de la empresa SaaS definió los siguientes requisitos:
- Modelado: dos tablas almacenarán los datos existentes y los nuevos.
Los datos nuevos se guardan en una tabla llamada "staging", y los existentes (los que ve el cliente) en una tabla llamada "target".
- Unicidad: los datos de la tabla "target" son únicos (sin claves duplicadas).
- Frescura: la tabla "target" se actualiza dentro de la hora siguiente a la llegada del snapshot.
- Disponibilidad: el usuario final siempre recibe respuesta a su consulta.
El reto de las mutaciones
Como explica el siguiente blog de Google, BigQuery no está construido como las bases de datos OLTP transaccionales, que son nativamente eficientes con mutaciones de gran volumen.
"BigQuery no es la única base de datos OLAP con limitaciones en la frecuencia de mutaciones, ya sea de forma explícita (mediante cuotas) o implícita (con una degradación importante del rendimiento), porque este tipo de bases están optimizadas para ingestas a gran escala y consultas analíticas, no para procesamiento transaccional. Además, BigQuery permite leer el estado de una tabla en cualquier instante de los siete días anteriores. Esa ventana de retroceso obliga a conservar datos que el usuario ya eliminó. Para sostener consultas eficientes y rentables a gran escala, BigQuery limita la frecuencia de mutaciones mediante cuotas." ( Performing large-scale mutations in BigQuery | Google Cloud Blog )
Un reemplazo total, en el que se elimina el snapshot anterior y se sustituye por el nuevo, no alcanza, porque hay que conservar los registros que están en el snapshot actual pero no aparecen en el más reciente.
Es decir, hay que comparar los registros entre el snapshot existente y el nuevo, algo que el reemplazo tradicional no hace.
Para mostrar las opciones de mutación y sus diferencias, definamos el problema con precisión, junto con el modelado y la lógica de mutación exactos.
Modelado de datos
Esquema de la tabla:
Un registro en una tabla ("staging" o "target") contiene un attribute_id y un valor para un producto específico (product_id) en una tienda (store_id) para una fecha determinada, junto con la referencia del snapshot en el que existió (update_id).

Ejemplo de registro:
Según los datos recibidos en el snapshot ID 1 (update_id), el valor de cantidad total (attribute_id = 1) de un producto (product_id = 301865) en una tienda (store_id = 2072) era 20 el 2017-04-21.
Ejemplo de la lógica de mutación:
A continuación se muestra una muestra de una partición (fecha específica) tomada de dos snapshots distintos.
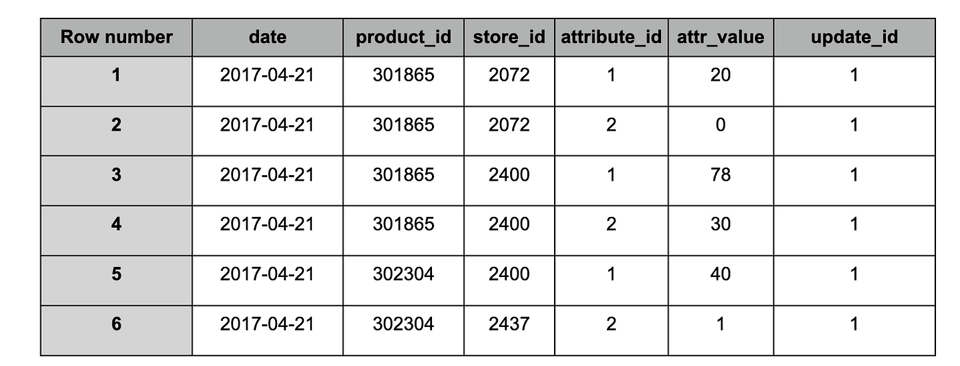
Tabla "target" tras la ingesta del snapshot #1
El snapshot #2 trajo los siguientes cambios:
1. Azul: registros actualizados (presentes en ambos snapshots), con valor modificado.
2. Rojo: registro histórico (presente solo en el snapshot #1).
3. Verde: registro nuevo (presente solo en el snapshot #2).
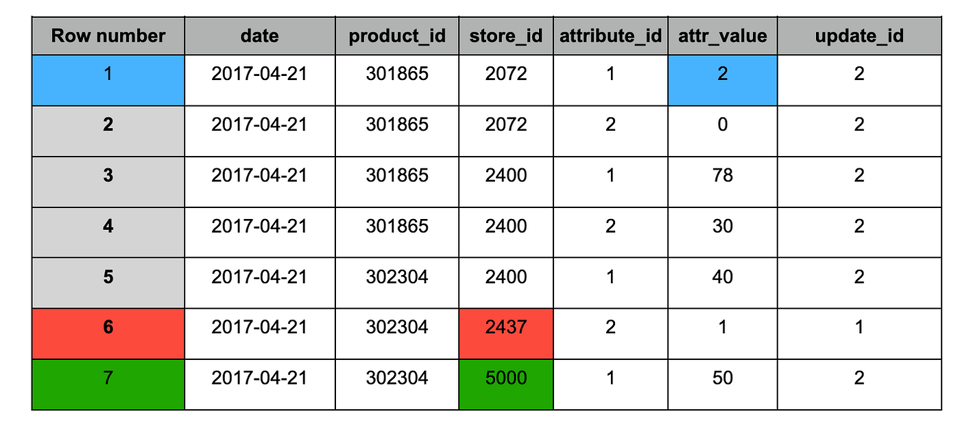
Tabla "target" tras la ingesta del snapshot #2
Como BigQuery soporta MERGE, lo intuitivo es fusionar la tabla staging con la target siguiendo la lógica que se muestra a continuación.
Lógica del Merge
Esta lógica de MERGE define las mutaciones que se aplican según los distintos casos, a partir de una clave conjunta formada por los siguientes campos: product_id, store_id, attribute_id.
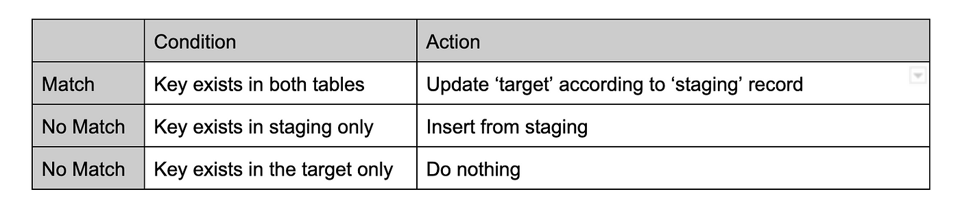
Esta es la implementación en código de la lógica del MERGE:
MERGEnw-playground.demo.merge_target TUSINGnw-playground.demo.merge_staging SON T.product_Id = S.product_Id AND T.store_Id = S.store_Id AND T.attribute_Id = S.attribute_Id AND T.date = S.date WHEN MATCHED and T.date >= '2017-04-14' and T.date <= '2017-04-26' THEN UPDATE SET T.attr_value = S.attr_value, T.update_id = S.update_id WHEN NOT MATCHED BY TARGET and S.date >= '2017-04-14' and S.date <= '2017-04-26' THENINSERT (date, product_Id, store_Id, attribute_Id, attr_value, update_id)VALUES (S.date, S.Product_id, S.store_Id, S.attribute_Id, S.attr_value, S.update_id);Problema:
Como ya se mencionó, la operación MERGE resulta muy costosa en BQ y tiene limitaciones, ya que requiere shuffling y mutación de los datos existentes.
Por eso, hay que encontrar la forma de evitar el MERGE y la mutación de datos.
Enfoque de Deduplicación y Clonación
¿Qué vamos a hacer?
En lugar de fusionar los registros de las tablas "staging" y "target", aplicamos los siguientes pasos:
- Anexar el nuevo snapshot a la tabla "staging".
- Deduplicar los registros similares y conservar el más reciente.
La deduplicación es un proceso para eliminar registros duplicados y dejar solo uno. Se consigue definiendo una clave de registro que identifica a los duplicados y una lógica para decidir cuál conservar entre ellos (por ejemplo, el más reciente). 3. Reemplazar la tabla "staging" con el resultado de la deduplicación. 4. Reemplazar la tabla "target" con un CLONE de la tabla "staging".
"CLONE Un clon de tabla es una copia ligera y modificable de otra tabla (la tabla base). Solo se cobra por el almacenamiento de los datos del clon que difieren de la tabla base, así que al inicio no hay costo de almacenamiento. Más allá del modelo de facturación del almacenamiento y de algunos metadatos adicionales para la tabla base, un clon de tabla se comporta como una tabla estándar: puedes consultarlo, copiarlo, eliminarlo, etc. Una vez creado, el clon es independiente de la tabla base. Cualquier cambio en la tabla base o en el clon no se refleja en la otra." table-clones-intro
¿Cómo lo haremos?
- Anexado de datos: con el comando
LOADen modo "append", para que la tabla staging contenga el snapshot actual y el nuevo. - Deduplicación: deduplicar los registros similares (misma clave) y conservar el más reciente entre ellos. La deduplicación no afecta a los registros completamente nuevos ni a los que solo existen en el snapshot actual. Se implementa con funciones de ventana, que calculan valores sobre un grupo de filas, junto con la operación
QUALIFY. La cláusulaQUALIFYpermite filtrar los resultados de una función de ventana (grupo de filas). - Reemplazar "staging": con
CREATE OR REPLACEa partir del resultado de la consulta de deduplicación. - Clonar "staging" en "target": con
CREATE OR REPLACE TABLE ... CLONE.
¿Por qué lo hacemos así?
Este enfoque aporta varias ventajas frente al de MERGE:
1. Reduce el shuffling de datos: anexar el nuevo snapshot al existente evita el shuffling entre dos tablas.
2. Evita la operación MERGE/JOIN: la deduplicación se implementa con una función de ventana que utiliza la cláusula PARTITION BY, que divide las filas de entrada en particiones independientes sobre las que la función se evalúa por separado.
3. Evita mutaciones: se crean o clonan tablas nuevas, así se esquivan los límites de cuota de mutación de BigQuery.
Ejemplo de la lógica de anexado y deduplicación:
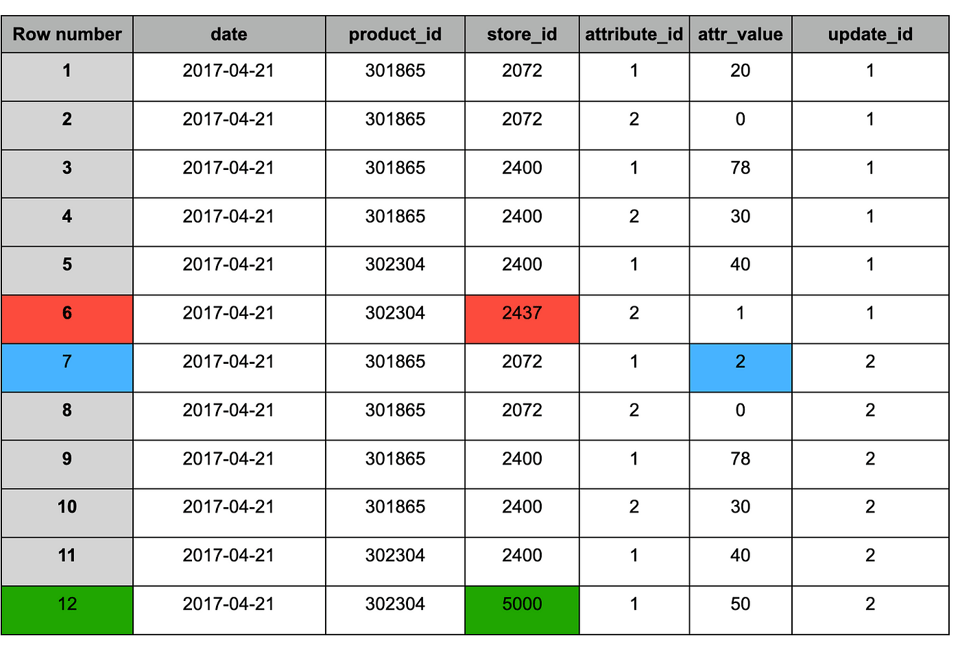
Tabla staging tras anexar el nuevo snapshot (#2)
Al igual que con el resultado de MERGE, la tabla tras la deduplicación contiene los siguientes cambios:
1. Azul: registros actualizados (presentes en ambos snapshots), con valor modificado.
2. Rojo: registros antiguos que deben conservarse (presentes solo en el snapshot #1).
3. Verde: registro nuevo (presente solo en el snapshot #2).
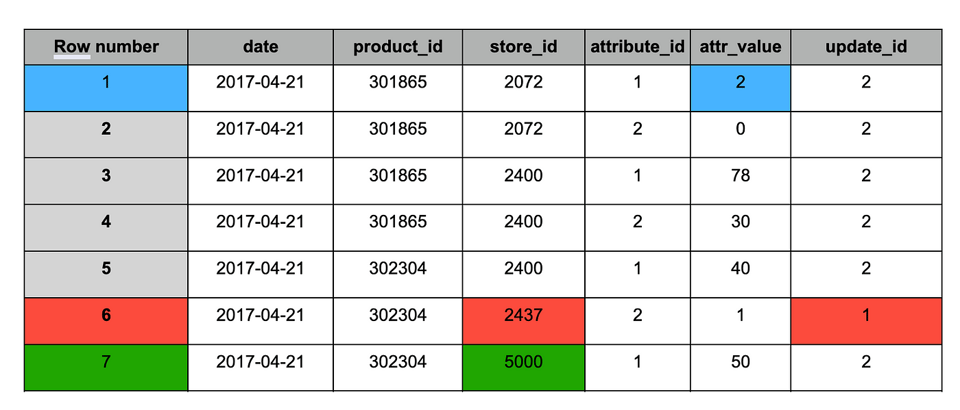
Tabla staging tras la deduplicación
Cuando llegue el siguiente snapshot, se sigue el mismo proceso.
Ejemplos de código:
El siguiente código crea una nueva tabla staging a partir de los resultados de la deduplicación, reemplazando la tabla existente. Usa la cláusula QUALIFY y agrega un número de fila a cada registro con clave similar; el primer registro (rownum=1) es el más reciente.
CREATE OR REPLACE TABLE `nw-playground.demo.dedup_staging` (date DATE, product_id INT64, store_id INT64, attribute_id INT64, attr_value INT64, update_id INT64)PARTITION BY dateCLUSTER BY product_id, store_id ASSELECT date, product_id, store_id, attribute_id, attr_value, update_idFROM `nw-playground.demo.dedup_staging`WHERE date >= '2017-04-14' AND date <= '2017-04-26' QUALIFY ROW_NUMBER() OVER(PARTITION BY date, product_id, store_id, attribute_id ORDER BY update_id DESC ) = 1;
CREATE OR REPLACE TABLE`nw-playground.nw_demo.dedup_target`CLONE `nw-playground.nw_demo.dedup_staging`;Datos de prueba y resultados
Las pruebas se ejecutaron sobre 7.800 millones de registros (350 GiB) distribuidos en 13 particiones, con cerca de 3 millones de diferencias (de todos los tipos de cambios) entre "staging" y "target". Las pruebas se hicieron con el modelo de facturación on-demand.
En el caso del MERGE, la tabla "staging" contenía solo el snapshot nuevo y "target" tenía el snapshot existente. En el caso de la deduplicación, en cambio, la tabla staging contenía el snapshot existente y el nuevo, y "target" era un clon del primer snapshot de staging.
Comparación de resultados
La siguiente tabla muestra la comparación de los resultados:

Resumen comparativo de los detalles de ejecución
Al comparar los planes de ejecución se ve con claridad que la duración y el uso de slots de la prueba con MERGE duplican los de la prueba con DEDUPLICATE:

Duración de la operación principal y uso de slots
Comparación de costos
Modelo de facturación on-demand:
El costo es similar entre las pruebas, ya que se escanea el mismo volumen de datos. Llegará a unos 187 USD (6,25 USD por 1 TiB) en una carga completa, considerando 30 TB y 2 snapshots.
BigQuery Editions:
El nuevo modelo de facturación que Google lanzó en abril de 2023 se basa en precios por capacidad (pago por slot/hora) y tiene tres ediciones. Para calcular el costo de una carga de producción, se puede estimar una carga completa de snapshot con un factor de 56 respecto a la prueba realizada (730 días-particiones en 2 años; 730/13 ≈ 56).
La estimación de costo no es exacta, ya que también intervienen otras configuraciones y commitments. Lo que sí refleja es la diferencia entre las dos opciones.
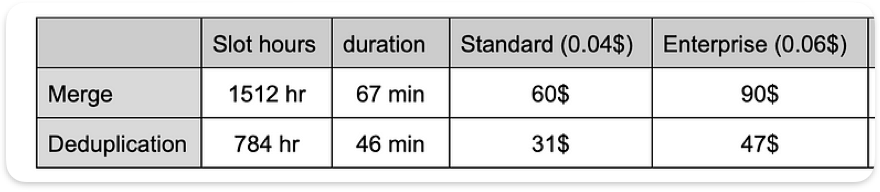
Comparación de costos estimados entre las ediciones de BigQuery (precios de EE. UU.)
Apéndice
Existen varias formas de implementar la deduplicación (con ROWNUM o GROUP BY). La deduplicación con ROWNUM dio un rendimiento similar al de la cláusula QUALIFY; aun así, QUALIFY es un comando más limpio. Usar "GROUP BY" arrojó peor rendimiento, similar al del Merge.
Hay otra forma eficiente de implementarlo: stored procedures para Apache Spark, tema que abordaremos en el siguiente blog…
Como vimos en el caso de uso, hay una mutación a gran escala que depende de una lógica de join con los datos existentes. La forma preferida de abordarla es evitar las modificaciones sobre los datos.
Optar por la "deduplicación" y CLONE evita las limitaciones de DML y mejora notablemente las dos dimensiones, Elapsed Time y uso de slots, con una reducción de cerca del 50% en rendimiento y costo.