
Photo d'eMotion Tech sur Unsplash
Préambule
Ce billet présente une manière d'aborder un défi bien connu des entrepôts de données : maintenir des données fraîches et à jour tout en évitant les mutations massives.
Chez DoiT, nous accompagnons de nombreux clients dans la conception de systèmes bien architecturés et dans l'utilisation efficace des services cloud. Ce qui suit s'inspire d'un cas client.
Contexte
Une entreprise SaaS propose à ses clients une plateforme analytique bâtie sur BigQuery. Pour certains d'entre eux, les données sont reçues sous forme de snapshot complet, incluant tout l'historique et pas uniquement les modifications incrémentales depuis la dernière mise à jour.
L'un de ces clients fournit un snapshot de 15 To, alors que les données réellement modifiées ne représentent que 0,1 %. Faute de pouvoir récupérer uniquement les changements incrémentaux, l'équipe devait identifier la méthode la plus fiable et la plus efficace, en termes de performance et de coût, pour maintenir la table existante à jour avec les données du nouveau snapshot.
Exigences du pipeline de données
L'entreprise et son client ont défini un contrat de données pour le pipeline afin de répondre aux exigences métier et techniques :
- Les données entrantes constituent un snapshot complet sur une fenêtre glissante de deux ans, livré six fois par jour.
- Les données sont partitionnées par jour (taille de partition d'environ 20 Gio) et marquées par un identifiant de snapshot (valeur incrémentale).
- Les données contiennent à la fois des données nouvelles (nouvelles clés) et des données modifiées (mises à jour de données existantes).
- Expiration des partitions configurée à 2 ans.
- Les enregistrements présents dans le snapshot actuel mais absents du nouveau sont conservés jusqu'à l'expiration de la partition.
L'équipe produit de l'entreprise SaaS a défini les exigences suivantes :
- Modélisation : deux tables contiendront les données existantes et les nouvelles.
Les nouvelles données résident dans une table nommée staging, et les données existantes (exposées au client) dans une table nommée target.
- Unicité : les données de la table target sont uniques (pas de clés en doublon).
- Fraîcheur : la table target est rafraîchie dans l'heure suivant l'arrivée du snapshot.
- Disponibilité : l'utilisateur final obtient toujours une réponse à sa requête.
Le défi des mutations
Comme l'explique le billet Google ci-dessous, BigQuery n'est pas conçu comme les bases OLTP transactionnelles, qui sont nativement efficaces pour les mutations volumineuses.
" BigQuery n'est pas la seule base OLAP à être contrainte sur la fréquence des mutations, que ce soit explicitement (via des quotas) ou implicitement (avec une dégradation significative des performances). Ces bases sont en effet optimisées pour l'ingestion à grande échelle et les requêtes analytiques, et non pour le traitement transactionnel. BigQuery permet par ailleurs de lire l'état d'une table à n'importe quel instant des sept jours précédents. Cette fenêtre rétrospective impose de conserver des données déjà supprimées par l'utilisateur. Pour garantir des requêtes efficaces et économiques à grande échelle, BigQuery limite la fréquence des mutations via des quotas. " ( Performing large-scale mutations in BigQuery | Google Cloud Blog )
Un remplacement complet, qui supprimerait l'ancien snapshot pour le remplacer par le nouveau, ne suffit pas : il faut conserver les enregistrements présents dans le snapshot actuel mais absents du dernier.
Il faut donc comparer les enregistrements entre le snapshot existant et le nouveau, ce qu'une approche de remplacement classique ne permet pas.
Pour illustrer les différentes options de mutation, posons précisément le problème avec une modélisation de données et une logique de mutation concrètes.
Modélisation des données
Schéma de la table :
Un enregistrement d'une table (staging ou target) contient un attribute_id et une valeur pour un produit donné (product_id) dans un magasin (store_id), à une date précise, ainsi que la référence du snapshot dans lequel il figurait (update_id).

Exemple d'enregistrement :
D'après les données reçues dans le snapshot ID 1 (update_id), la quantité totale (attribute_id = 1) d'un produit (product_id = 301865) dans un magasin (store_id = 2072) était de 20 le 21/04/2017.
Exemple de logique de mutation :
Voici un échantillon issu d'une partition (date donnée) provenant de deux snapshots différents.
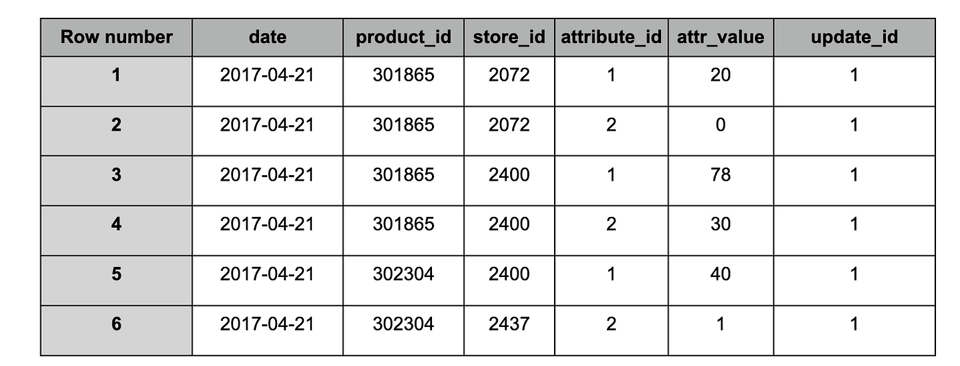
Table target après ingestion du snapshot n°1
Le snapshot n°2 contenait les changements suivants :
1. Bleu : enregistrements mis à jour (présents dans les deux snapshots), valeur modifiée.
2. Rouge : enregistrement historique (présent uniquement dans le snapshot n°1).
3. Vert : nouvel enregistrement (présent uniquement dans le snapshot n°2).
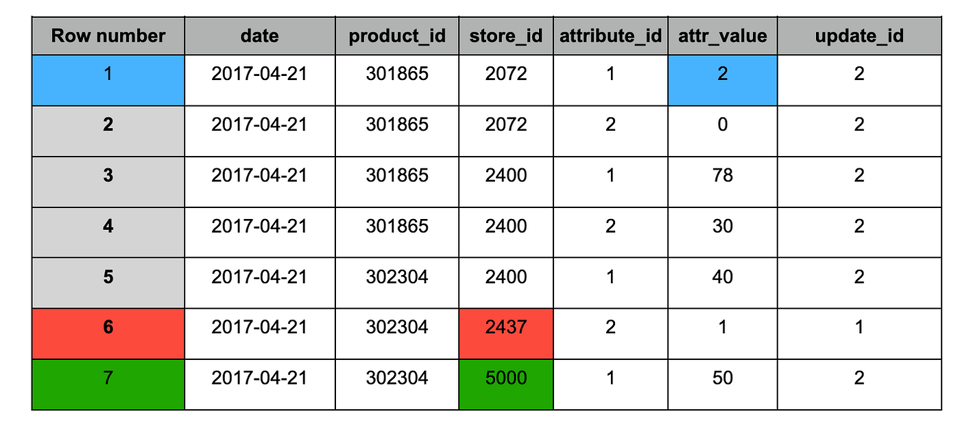
Table target après ingestion du snapshot n°2
BigQuery prenant en charge l'opération MERGE, fusionner la table de staging avec la table cible constitue l'approche intuitive, suivant la logique ci-dessous.
Logique de fusion
Cette logique MERGE définit les mutations à appliquer selon les différents cas, à partir d'une clé de jointure composée des champs suivants : product_id, store_id, attribute_id.
Voici l'implémentation de la logique MERGE :
MERGEnw-playground.demo.merge_target TUSINGnw-playground.demo.merge_staging SON T.product_Id = S.product_Id AND T.store_Id = S.store_Id AND T.attribute_Id = S.attribute_Id AND T.date = S.date WHEN MATCHED and T.date >= '2017-04-14' and T.date <= '2017-04-26' THEN UPDATE SET T.attr_value = S.attr_value, T.update_id = S.update_id WHEN NOT MATCHED BY TARGET and S.date >= '2017-04-14' and S.date <= '2017-04-26' THENINSERT (date, product_Id, store_Id, attribute_Id, attr_value, update_id)VALUES (S.date, S.Product_id, S.store_Id, S.attribute_Id, S.attr_value, S.update_id);Problème :
Comme indiqué plus haut, l'opération MERGE est très coûteuse dans BigQuery et soumise à des limitations, car elle implique un brassage (shuffle) et la mutation des données existantes.
Il faut donc trouver un moyen d'éviter à la fois le MERGE et la mutation des données.
Approche : déduplication et clonage
Que va-t-on faire ?
Au lieu de fusionner les enregistrements des tables staging et target, voici la marche à suivre :
- Ajouter le nouveau snapshot à la table staging.
- Dédupliquer les enregistrements similaires en ne conservant que le plus récent.
La déduplication est un procédé qui supprime les enregistrements dupliqués pour n'en conserver qu'un seul. Elle s'appuie sur une clé permettant d'identifier les enregistrements similaires et sur une logique pour décider lequel conserver parmi les doublons (par exemple, le plus récent). 3. Remplacer la table staging par le résultat de la déduplication. 4. Remplacer la table target par un CLONE de la table staging.
CLONE : un clone de table est une copie légère et modifiable d'une autre table (appelée table de base). Vous n'êtes facturé que pour le stockage des données du clone qui diffèrent de la table de base ; au départ, il n'y a donc aucun coût de stockage pour le clone. Hormis le modèle de facturation du stockage et quelques métadonnées supplémentaires concernant la table de base, un clone se comporte comme une table standard : vous pouvez l'interroger, le copier, le supprimer, etc. Une fois créé, un clone est indépendant de la table de base. Aucune modification apportée à la table de base ou au clone n'est répercutée sur l'autre. table-clones-intro
Comment va-t-on procéder ?
- Ajout des données : utiliser la commande
LOADen mode append, afin que la table de staging contienne le snapshot actuel et le nouveau. - Déduplication : dédupliquer les enregistrements similaires (même clé) en gardant le plus récent. La déduplication n'affecte ni les enregistrements entièrement nouveaux, ni ceux présents uniquement dans le snapshot actuel. Elle s'appuie sur des window functions, qui calculent des valeurs sur un groupe de lignes, et sur l'opération
QUALIFY. La clauseQUALIFYpermet de filtrer les résultats d'une window function. - Remplacer staging : utiliser
CREATE OR REPLACEà partir du résultat de la requête de déduplication. - Cloner staging vers target : utiliser
CREATE OR REPLACE TABLE ... CLONE.
Pourquoi cette approche ?
Elle présente plusieurs atouts par rapport au MERGE :
1. Moins de brassage : ajouter le nouveau snapshot à l'existant évite le shuffle entre deux tables.
2. Pas d'opération MERGE/JOIN : la déduplication s'appuie sur une window function avec une clause PARTITION BY, qui découpe les lignes en partitions évaluées indépendamment.
3. Pas de mutation : on crée ou on clone des tables, ce qui contourne les quotas de mutation BigQuery.
Exemple de logique d'ajout et de déduplication :
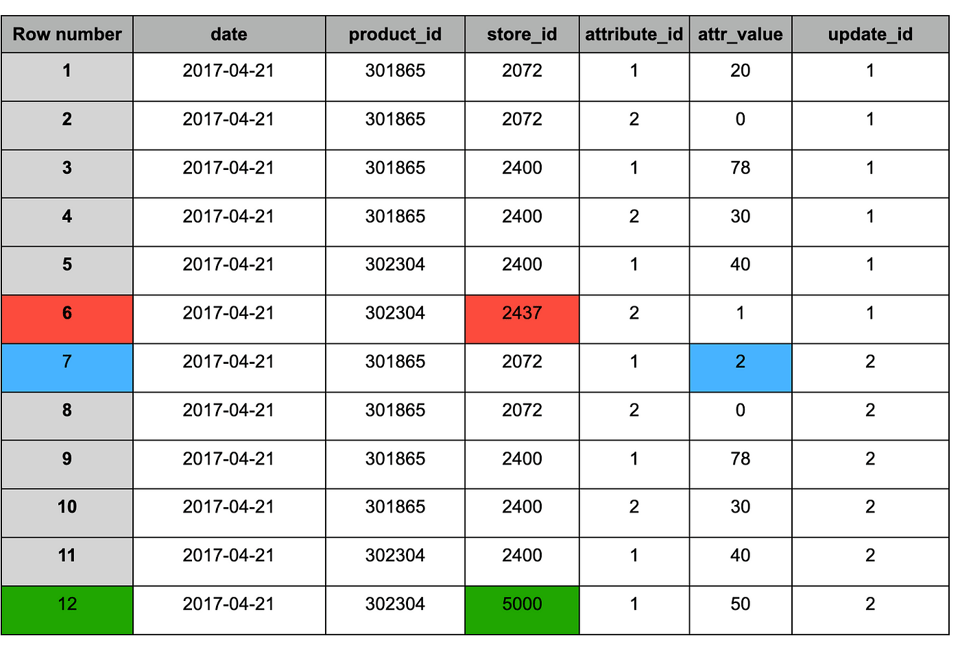
Table de staging après ajout du nouveau snapshot (n°2)
À l'instar du résultat du MERGE, la table après déduplication contient les changements suivants :
1. Bleu : enregistrements mis à jour (présents dans les deux snapshots), valeur modifiée.
2. Rouge : anciens enregistrements à conserver (présents uniquement dans le snapshot n°1).
3. Vert : nouvel enregistrement (présent uniquement dans le snapshot n°2).
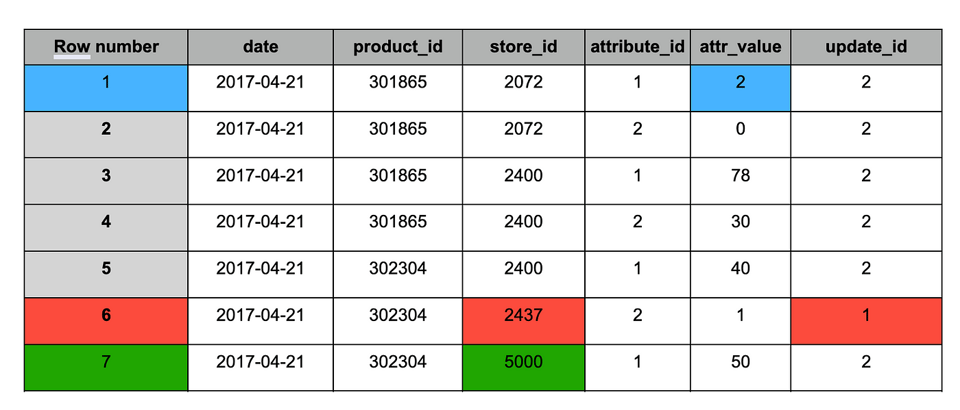
Table de staging après déduplication
À l'arrivée du snapshot suivant, le même processus s'applique.
Exemples de code
Le code ci-dessous crée une nouvelle table de staging à partir du résultat de la déduplication, qui remplace la table existante grâce à la clause QUALIFY. Un numéro de ligne est attribué à chaque enregistrement partageant une clé identique, le 1er enregistrement (rownum=1) étant le plus récent.
CREATE OR REPLACE TABLE `nw-playground.demo.dedup_staging` (date DATE, product_id INT64, store_id INT64, attribute_id INT64, attr_value INT64, update_id INT64)PARTITION BY dateCLUSTER BY product_id, store_id ASSELECT date, product_id, store_id, attribute_id, attr_value, update_idFROM `nw-playground.demo.dedup_staging`WHERE date >= '2017-04-14' AND date <= '2017-04-26' QUALIFY ROW_NUMBER() OVER(PARTITION BY date, product_id, store_id, attribute_id ORDER BY update_id DESC ) = 1;
CREATE OR REPLACE TABLE`nw-playground.nw_demo.dedup_target`CLONE `nw-playground.nw_demo.dedup_staging`;Données de test et résultats
Les tests ont porté sur 7,8 milliards d'enregistrements (350 Gio) répartis sur 13 partitions, avec environ 3 M de différences (tous types de changements) entre les tables staging et target. Ils ont été réalisés avec le modèle de facturation à la demande.
Dans le cas du MERGE, la table staging ne contenait que le nouveau snapshot et la table target contenait le snapshot existant. Dans le cas de la déduplication, la table de staging contenait à la fois le snapshot existant et le nouveau, tandis que la target était un clone du premier snapshot de staging.
Comparaison des résultats
Le tableau suivant compare les résultats :

Synthèse comparative des détails d'exécution
La comparaison des plans d'exécution montre clairement que la durée et l'utilisation des slots du MERGE sont le double de celles du DEDUPLICATE :

Durée de l'opération principale et utilisation des slots
Comparaison des coûts
Modèle de facturation à la demande
Le coût est similaire entre les tests, puisque le volume de données scanné est identique. Il atteindrait environ 187 $ (6,25 $ par Tio) en charge complète, sur la base de 30 To pour 2 snapshots.
BigQuery Editions
Le nouveau modèle de facturation introduit par Google en avril 2023 repose sur une tarification à la capacité (paiement par slot/heure) et propose trois éditions. Pour estimer le coût d'une charge en production, on peut multiplier par 56 le test réalisé (730 partitions journalières sur 2 ans, soit 730/13 = 56).
L'estimation reste approximative, car différentes configurations et commitments peuvent s'appliquer. Elle illustre surtout l'écart entre les deux options.
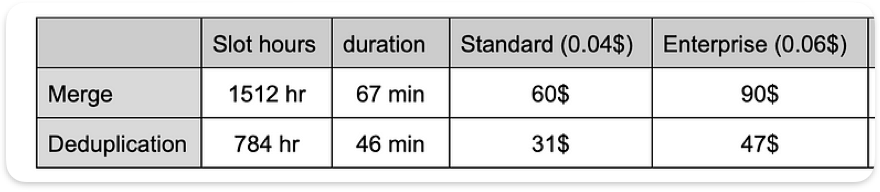
Comparaison des coûts estimés entre les éditions BigQuery (tarifs US)
Annexe
Il existe plusieurs façons d'implémenter la déduplication (avec ROWNUM ou GROUP BY). La déduplication via ROWNUM offre des performances comparables à la clause QUALIFY ; QUALIFY reste néanmoins une commande plus claire. Avec GROUP BY, les performances étaient moins bonnes, équivalentes à celles du MERGE.
Une autre approche efficace est envisageable : les procédures stockées pour Apache Spark. À suivre dans un prochain billet…
Comme l'illustre ce cas d'usage, on est confronté à une mutation à grande échelle qui repose sur une logique de jointure avec les données existantes. La meilleure approche consiste à éviter toute modification des données.
Le recours à la déduplication et au CLONE contourne les limitations DML et améliore considérablement les deux dimensions, durée d'exécution et utilisation des slots, soit une réduction d'environ 50 % en performance et en coût.