
Foto de eMotion Tech no Unsplash
Prefácio
Este post apresenta uma forma de resolver um desafio clássico em sistemas de data warehouse: manter os dados sempre atualizados sem precisar recorrer a grandes mutações.
Na DoiT, ajudamos diversos clientes a construir sistemas bem arquitetados e a usar serviços de nuvem com eficiência. O conteúdo a seguir nasceu de um caso real de cliente.
Contexto
Uma empresa SaaS oferece a seus clientes uma plataforma analítica em cima do BigQuery. Para alguns clientes, os dados chegam como um snapshot completo, com todo o histórico — não apenas as mudanças incrementais desde a última atualização.
Um desses clientes envia um snapshot de 15TB, mas só 0,1% dos dados realmente mudou. Como não havia como receber apenas as mudanças incrementais, o time tinha o desafio de encontrar a forma mais confiável e eficiente, em performance e custo, de manter a tabela existente atualizada com os dados do novo snapshot.
Requisitos do data pipeline
A empresa e o cliente definiram um contrato de dados para que o pipeline atendesse aos requisitos de negócio e técnicos:
- Os dados de entrada são um snapshot completo de uma janela deslizante de dois anos, com cadência de chegada de seis vezes por dia.
- Os dados são particionados por dia (cada partição tem cerca de 20GiB~) e marcados com um snapshot ID (valor incremental).
- Os dados podem trazer registros novos (chaves novas) e registros alterados (atualizações de dados existentes).
- Expiração de partição configurada para 2 anos.
- Registros que existem no snapshot atual, mas não aparecem no novo snapshot, permanecem até a expiração da partição.
O time de produto da empresa SaaS definiu os seguintes requisitos:
- Modelagem: duas tabelas vão guardar os dados existentes e os novos.
Os dados novos ficam em uma tabela chamada "staging", e os existentes (expostos ao cliente) ficam em uma tabela chamada "target".
- Unicidade: os dados da tabela "target" são únicos (sem chaves duplicadas).
- Atualidade: a tabela "target" é atualizada em até uma hora após a chegada do snapshot.
- Disponibilidade: o usuário final sempre recebe uma resposta para sua consulta.
O desafio das mutações
Como explica o blog do Google a seguir, o BigQuery não foi construído como bancos OLTP transacionais, que são nativamente eficientes em mutações de grande volume.
"BigQuery is not unique among OLAP databases in being constrained on mutation frequency, either explicitly (through quotas) or implicitly (resulting in significant performance degradation), since these types of databases are optimized for large-scale ingestion and analytical queries as opposed to transaction processing. Furthermore, BigQuery allows you to read the state of a table at any instant in time during the preceding seven days. This look-back window requires retaining data that the user has already deleted. To support cost-effective and efficient queries at scale, BigQuery limits the frequency of mutations using quotas." ( Performing large-scale mutations in BigQuery | Google Cloud Blog )
Uma substituição completa, que apaga o snapshot antigo e troca pelo novo, não resolve, porque é preciso manter registros que existem no snapshot atual mas não aparecem no snapshot mais recente.
Ou seja, é necessário comparar registros entre o snapshot existente e o novo — algo que a substituição tradicional simplesmente não faz.
Para mostrar as opções de mutação e suas diferenças, vamos definir o problema com precisão, com a modelagem de dados e a lógica de mutação exatas.
Modelagem de dados
Schema da tabela:
Um registro em uma tabela ('staging' ou 'target') contém um attribute_id e um valor para um produto específico (product_id) em uma loja (store_id), em uma determinada data, além da referência ao snapshot em que ele existia (update_id).

Exemplo de registro:
Com base nos dados recebidos no snapshot de ID 1 (update_id), o valor da Quantidade Total (attribute_id = 1) de um produto (product_id = 301865) em uma loja (store_id = 2072) era 20 em 21/04/2017.
Exemplo da lógica de mutação:
Veja a seguir uma amostra de uma partição (data específica) em dois snapshots diferentes.
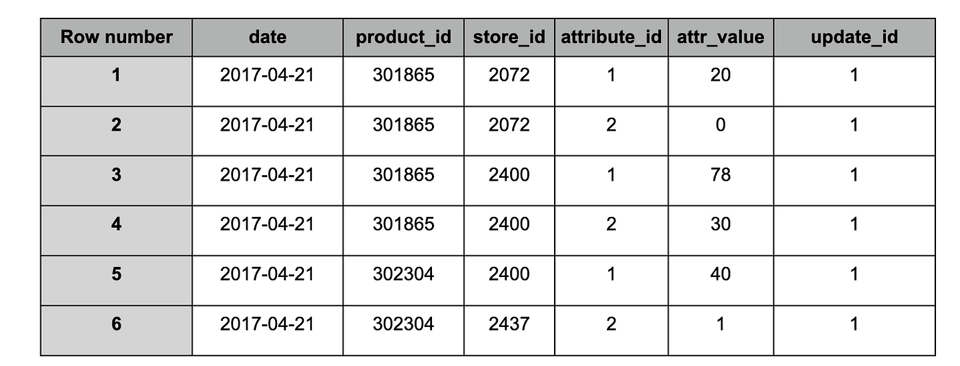
tabela 'target' após a ingestão do snapshot #1
O snapshot #2 trouxe as seguintes mudanças:
1. Azul: registros atualizados (aparecem nos dois snapshots), com valor alterado.
2. Vermelho: registro histórico (aparece apenas no snapshot #1).
3. Verde — novo registro (aparece apenas no snapshot #2).
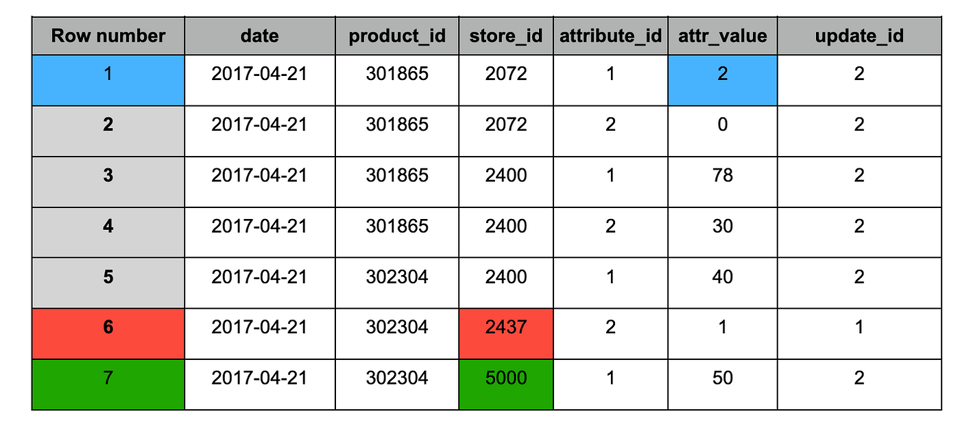
tabela 'target' após a ingestão do snapshot #2
Como o BigQuery suporta MERGE, fazer o merge da staging com a target é a abordagem intuitiva, com a lógica a seguir.
Lógica do merge
Esta lógica de MERGE define as mutações a serem aplicadas em cada caso, com base em uma chave de junção formada pelos campos: product_id, store_id, attribute_id.
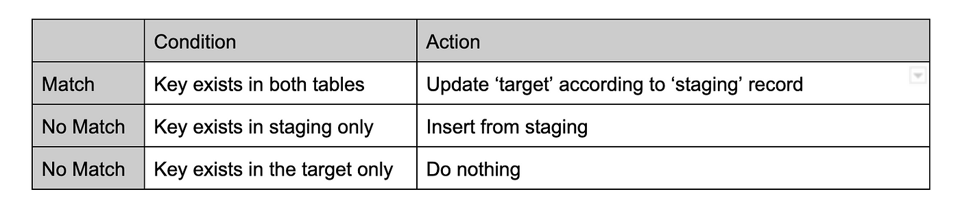
Esta é a implementação em código da lógica de MERGE:
MERGEnw-playground.demo.merge_target TUSINGnw-playground.demo.merge_staging SON T.product_Id = S.product_Id AND T.store_Id = S.store_Id AND T.attribute_Id = S.attribute_Id AND T.date = S.date WHEN MATCHED and T.date >= '2017-04-14' and T.date <= '2017-04-26' THEN UPDATE SET T.attr_value = S.attr_value, T.update_id = S.update_id WHEN NOT MATCHED BY TARGET and S.date >= '2017-04-14' and S.date <= '2017-04-26' THENINSERT (date, product_Id, store_Id, attribute_Id, attr_value, update_id)VALUES (S.date, S.Product_id, S.store_Id, S.attribute_Id, S.attr_value, S.update_id);Problema:
Como dito acima, a operação MERGE é muito custosa no BQ e tem limitações, exigindo shuffling e mutação dos dados existentes.
Ou seja, precisamos achar um jeito de evitar o MERGE e a mutação de dados.
Abordagem Deduplicate e Clone
O que vamos fazer?
Em vez de fazer o merge dos registros das tabelas 'staging' e 'target', vamos seguir estes passos:
- Anexar o novo snapshot à tabela 'staging'.
- Deduplicar registros similares e manter o mais recente.
Deduplicação é o processo de remover registros duplicados, deixando apenas um. É feita definindo uma chave para identificar registros similares e uma lógica para decidir qual manter entre os duplicados (por exemplo, o mais recente). 3. Substituir a tabela 'staging' pelos resultados da deduplicação. 4. Substituir a tabela 'target' por um CLONE da 'staging'.
"CLONE Um clone de tabela é uma cópia leve e gravável de outra tabela (chamada de tabela base). Você só paga pelo armazenamento dos dados que diferem da tabela base, então, no início, não há custo de armazenamento para o clone. Tirando o modelo de cobrança de armazenamento e alguns metadados adicionais da tabela base, um clone se comporta como uma tabela padrão — você pode consultá-lo, copiá-lo, excluí-lo etc. Depois de criado, o clone é independente da tabela base. Quaisquer alterações feitas na tabela base ou no clone não são refletidas no outro." table-clones-intro
Como vamos fazer?
- Append dos dados: usando o comando
LOADem modo 'append', para que a staging contenha o snapshot atual e o novo. - Deduplicação: deduplicar registros similares (mesma chave), mantendo o mais recente entre eles. A deduplicação não afeta registros totalmente novos nem os que existem só no snapshot atual. Ela é implementada com ' Window functions', que calculam valores sobre um grupo de linhas, e a operação
QUALIFY. A cláusulaQUALIFYfiltra os resultados de uma window function (grupo de linhas). - Substituir a 'staging': usando
CREATE OR REPLACEcom base nos resultados da query de deduplicação. - Clonar a 'staging' para a 'target': usando
CREATE OR REPLACE TABLE ... CLONE.
Por que fazer assim?
Essa abordagem traz alguns ganhos em relação ao MERGE:
1. Reduz o data shuffling: anexar o novo snapshot ao existente evita shuffling entre duas tabelas.
2. Evita a operação MERGE/JOIN: a deduplicação é feita por uma window function que usa a cláusula PARTITION BY, que separa as linhas de entrada em partições independentes, sobre as quais a window function é avaliada de forma isolada.
3. Evita mutações: as tabelas são criadas ou clonadas, contornando os limites de cota de mutação do BigQuery.
Exemplo da lógica de append e deduplicação:
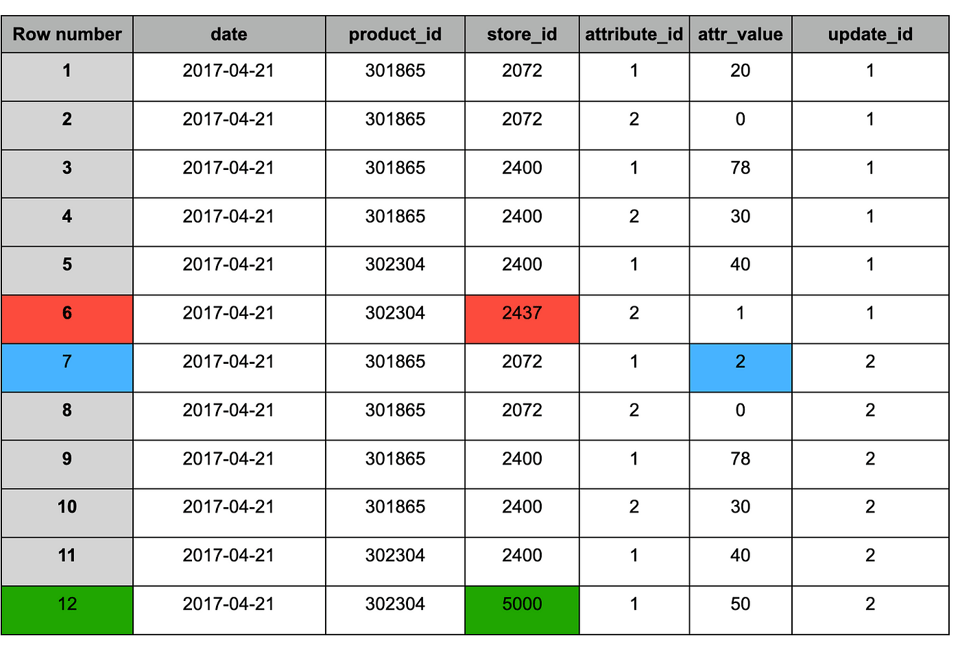
Tabela staging após o append do novo snapshot (#2)
Assim como no resultado do MERGE, a tabela após a deduplicação traz as seguintes mudanças:
1. Azul — registros atualizados (aparecem nos dois snapshots), com valor alterado.
2. Vermelho — registros antigos que devem ser mantidos (aparecem apenas no snapshot #1).
3. Verde — novo registro (aparece apenas no snapshot #2).
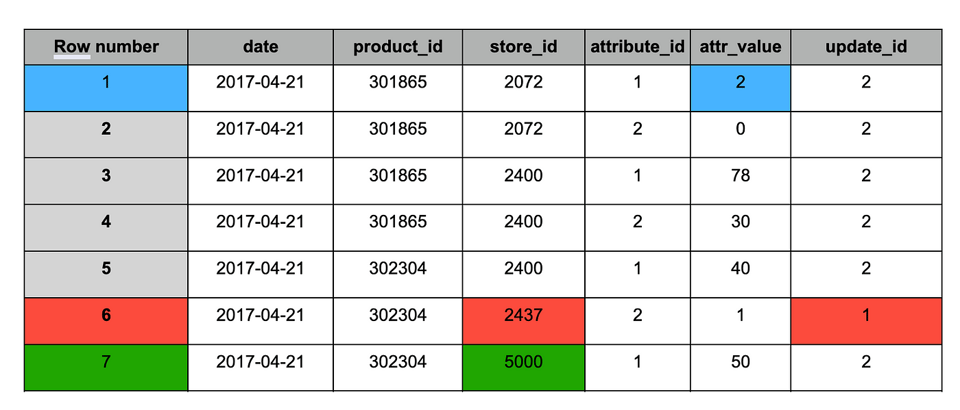
Tabela staging após a deduplicação
Quando o próximo snapshot chegar, ele segue exatamente o mesmo processo.
Exemplos de código:
O código a seguir cria uma nova tabela staging a partir dos resultados da deduplicação, substituindo a tabela existente. Ele usa a cláusula QUALIFY e atribui um row number a cada registro com chave similar — o 1º registro (rownum=1) é o mais recente.
CREATE OR REPLACE TABLE `nw-playground.demo.dedup_staging` (date DATE, product_id INT64, store_id INT64, attribute_id INT64, attr_value INT64, update_id INT64)PARTITION BY dateCLUSTER BY product_id, store_id ASSELECT date, product_id, store_id, attribute_id, attr_value, update_idFROM `nw-playground.demo.dedup_staging`WHERE date >= '2017-04-14' AND date <= '2017-04-26' QUALIFY ROW_NUMBER() OVER(PARTITION BY date, product_id, store_id, attribute_id ORDER BY update_id DESC ) = 1;
CREATE OR REPLACE TABLE`nw-playground.nw_demo.dedup_target`CLONE `nw-playground.nw_demo.dedup_staging`;Dados de teste e resultados
Os testes foram feitos com 7,8 bilhões de registros (350GiB), distribuídos em 13 partições, com cerca de 3M de diferenças (todos os tipos de mudança) entre 'staging' e 'target'. Os testes usaram o modelo de cobrança on-demand.
No caso do MERGE, a 'staging' continha apenas o novo snapshot e a 'target' tinha o snapshot existente. Já no caso da deduplicação, a staging tinha o snapshot existente e o novo, e a 'target' era um clone do 1º snapshot da staging.
Comparação dos resultados
A tabela a seguir mostra a comparação dos resultados:

Resumo comparativo dos detalhes de execução
Comparando os planos de execução, fica claro que a duração e o uso de slots no teste do MERGE são o dobro do DEDUPLICATE:

Duração e uso de slots da operação principal
Comparação de custos
Modelo de cobrança on-demand:
O custo é parecido entre os testes, já que escaneamos o mesmo volume de dados. Em uma carga completa, chega a cerca de US$ 187 (US$ 6,25 por 1TiB), considerando 30TB para 2 snapshots.
BigQuery Editions:
O novo modelo de cobrança lançado pelo Google em abril de 2023 é baseado em precificação por capacidade (pagamento por slot/hora) e tem três edições. Para estimar o custo de uma carga em produção, podemos calcular a carga completa de um snapshot por um fator de 56 em relação ao teste que fizemos (730 partições-dia em 2 anos, 730/13=56).
A estimativa não é exata, porque também há diferentes configurações e commitments a considerar. Ela serve principalmente para mostrar a diferença entre as duas opções.
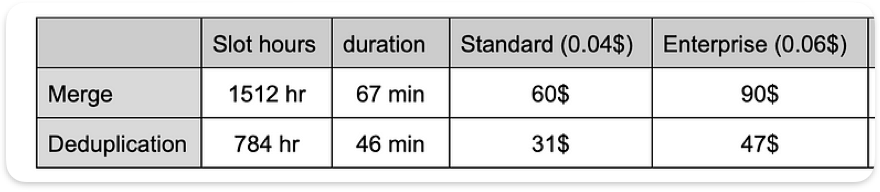
Comparação de custo estimado entre as edições do BigQuery (preços nos EUA)
Apêndice
Existem várias formas de implementar a deduplicação (com ROWNUM ou Group By). A deduplicação com ROWNUM teve performance parecida com a da cláusula QUALIFY — por isso, QUALIFY é um comando mais limpo. Já o "Group By" entregou performance pior, no mesmo nível dos resultados do Merge.
Existe ainda outra forma eficiente de implementação: stored procedures para Apache Spark, que vamos explorar no próximo post…
Como descrito no caso de uso, há uma mutação em larga escala envolvida, que depende de uma lógica de join com os dados existentes. A melhor forma de lidar com isso é evitar modificações nos dados.
Usar a opção de 'deduplicação' com CLONE contorna as limitações de DML e melhora bastante as duas dimensões — Tempo Decorrido e uso de Slots —, resultando em uma redução de cerca de 50% em performance e custo.