本記事では、BigQuery環境を見える化する各種手法を比較し、柔軟性を最大限に引き出すカスタムPythonスクリプトをご紹介します。
はじめに
めまぐるしく進化するデータ分析の世界で、Google BigQueryは大規模データに対して超高速なSQLクエリを実行できるサーバーレスデータウェアハウスとして、ひときわ存在感を放っています。データサイエンティストでも、データエンジニアでも、アナリティクスの専門家でも、BigQueryの幅広い機能を使いこなす過程は、まるで隠された宝探しのようなものです。組織の成長に伴ってBigQueryの利用範囲も広がっていく中、多くのユーザーが直面するのが、さまざまなスコープにまたがるテーブルやデータセットを効率よく一覧化するという課題です。
本記事では、BigQueryでテーブルやデータセットを一覧化するためのさまざまな手法を整理します。最終的なゴールは組織全体でこれらの資産を一覧化することであり、その過程で各手法の制約も明らかにしていきます。
基本的なGUI操作から、より高度なSQLクエリやAPI呼び出しまで、各種テクニックを掘り下げながら、それぞれの強みと弱みを見ていきましょう。記事の最後には、最大の柔軟性を備えた最終的なソリューションをご紹介します。多少の手間はかかりますが、その大部分はすでに私たちが済ませています。
取り上げる選択肢は次のとおりです。
- Google Cloud ConsoleのウェブUI
- BigQuery CLI
- Dataplex(Data Catalog)
- INFORMATION_SCHEMA
- カスタムスクリプト
そして、以下の評価軸で比較していきます。
- 一覧化のスコープ
- 取得できる情報の詳細度
- 柔軟性
- コスト
Google Cloud ConsoleのウェブUI
まずは使い慣れたGoogle Cloud ConsoleのウェブUIから始めるのが手堅い選択です。BigQueryの製品ページからBigQuery Studioに移動すると、現在のプロジェクト(および追加した他のプロジェクト)のデータセットとテーブルがエクスプローラーペインに表示されます。リソース(データセット、テーブル、ビュー)を名前やラベルで検索することもでき、アクセス権を持つprojectsとorganisationsの双方をまたいだ結果が返されます。
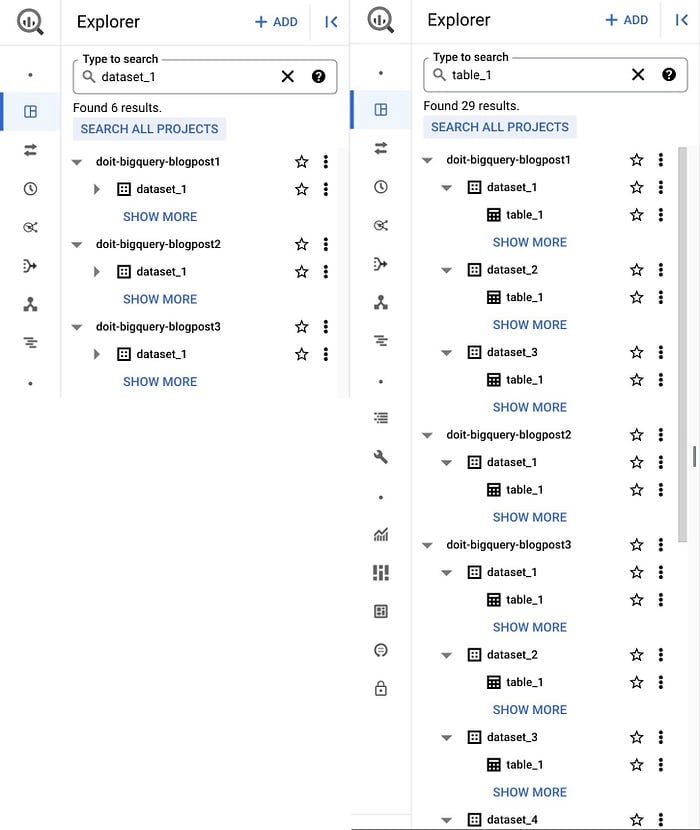
BigQuery UIのデータセット(左)とテーブル(右)
メリット:
- BigQuery Studioから手軽にアクセスできる。
projectsやorganisationsをまたいで検索でき、スコープに制限がない。- 無料で利用できる。
デメリット:
- 組織内、あるいはアクセス権を持つすべてのデータセットやテーブルを網羅的に一覧化することはできない。
- テーブルに関するそれ以上のメタデータは得られない。
BigQuery CLI
UIがあまり好みではなく、コマンドラインで作業するほうが性に合うという方には、BigQuery CLIのほうが魅力的に映るかもしれません。
PROJECT_IDを指定すれば、次のコマンドでそのプロジェクト内のすべてのデータセットを一覧化できます。
bq ls --project_id $PROJECT_ID

BigQuery CLIのデータセット
あるいはPROJECT_IDとDATASET_IDの両方を指定すれば、次のコマンドでそのデータセット内のすべてのテーブルを一覧化できます。
bq ls --project_id $PROJECT_ID --dataset_id=$DATASET_ID

BigQuery CLIのテーブル
メリット:
- 使いやすいCLI。
- 特に
--format: <none|json|prettyjson|csv|sparse|pretty>フラグと組み合わせれば、出力結果をjqなどで軽量に後続処理できる。 - メタデータ操作は無料。
デメリット:
- 一覧化のスコープが限定的で、データセットレベルではプロジェクト、テーブルレベルではデータセットがスコープとなる。
- 返される情報の詳細度もやはり限定的。
Dataplex(Data Catalog)
組織内の関連データをすべて見つけたいと考えたとき、真っ先に思い浮かぶのはData Catalogでしょう。Data Catalogはかつて単独の製品でしたが、2022年中頃以降はDataplexの一機能となりました。Dataplexは、データレイク、ウェアハウス、データベースをまたいだデータの整理・セキュリティ・分析を自動化するGoogle Cloudのインテリジェントなデータ管理プラットフォームで、組織のデータの発見性、ガバナンス、コンプライアンスを支えます。Data Catalogは、組織のデータ資産を一元管理する中央インベントリとして機能します。
これにより、組織やシステムをまたいだ検索や、データタイプ・タグなどでのフィルタリングが可能になります。今回のユースケースでは、UI上で適切なフィルタを指定するだけで、特定の組織内のすべてのデータセットとテーブルを取得できます。
嬉しいのは、UIよりもCLI派という方のために、次のようにgcloudコマンドでも同じことが実現できる点です。
データセットの場合:
gcloud data-catalog search "type=dataset" --include-organization-ids=YOUR_ORG_ID
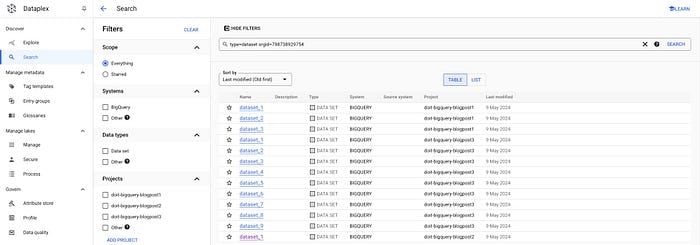
Dataplexのデータセット
テーブルの場合:
gcloud data-catalog search "type=table" --include-organization-ids=YOUR_ORG_ID
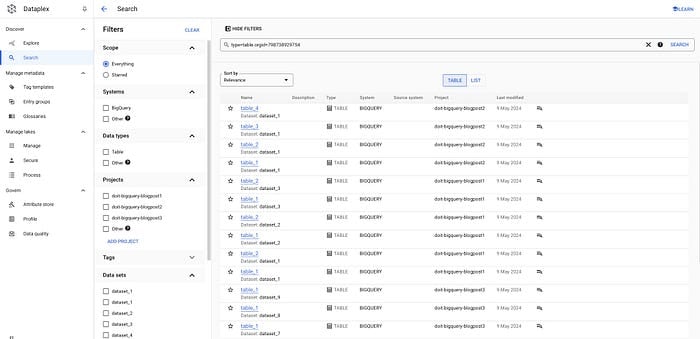
Dataplexのテーブル
メリット:
- 組織をまたいだ検索が可能で、対象もBigQueryに限定されない。
デメリット:
INFORMATION\_SCHEMA
BigQueryを使い込んでいる方なら、INFORMATION_SCHEMAはおなじみでしょう。BigQueryのINFORMATION_SCHEMAビューは読み取り専用のシステム定義ビューで、BigQueryオブジェクトに関するメタデータを提供します。種類は非常に豊富なので、全体像はドキュメントでご確認ください。
今回のユースケースで特に注目したいのは、SCHEMATAビューとTABLESビューです。
SCHEMATAビューを使えば、特定リージョン内のすべてのデータセットを一覧化できます。たとえばus-central1であれば次のとおりです。
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.SCHEMATA;
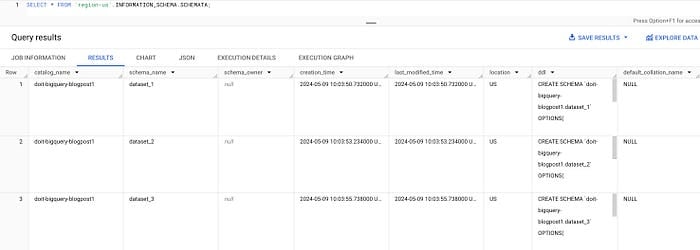
INFORMATION_SCHEMAのデータセット
あるいはTABLESビューを使えば、特定リージョン内のすべてのテーブルを一覧化できます。たとえばus-central1では次のとおりです。
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.TABLES;
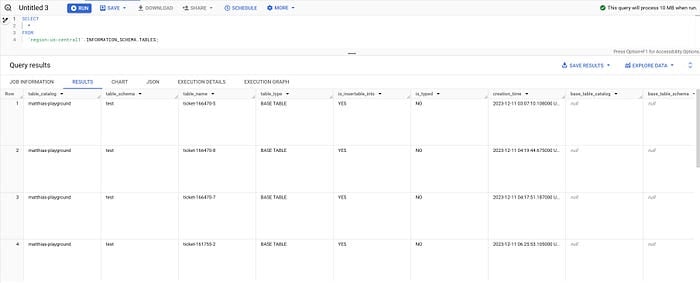
INFORMATION_SCHEMAのテーブル
メリット:
- BigQuery上でSQLからプログラム的に手軽にアクセスできる。
- 取得できる情報がきわめて詳細。たとえば
TABLESビューにはcreation_timeやddlが含まれ、TABLE_STORAGEビューにはtotal_rowsやテーブルサイズ(物理ストレージ・論理ストレージの両方)の情報が含まれる。
デメリット:
- 情報のスコープがリージョン単位までに制限される(組織レベルのビューでも同様)。リージョンのリストは既にかなり長く、動的に変化することもあるため、これをスクリプトで網羅するのは現実的とはいえない。
- 無料ではないが、ほとんどのユースケースでは料金は十分許容範囲に収まる。
カスタムスクリプトで完全な自由度を手に入れる
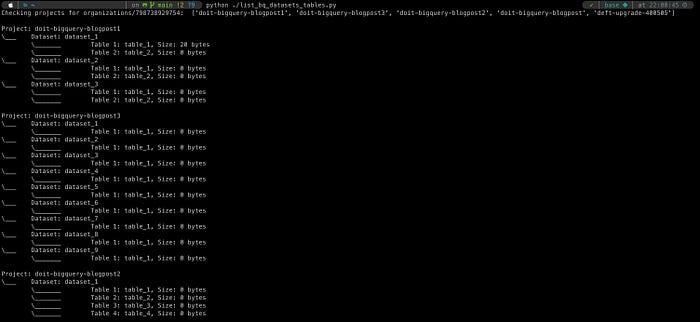
技術志向のお客様らしく、私たちのクライアントから「組織全体を見渡せる可視性」と「プロジェクトをまたいだテーブルの詳細情報の取得」という難題が投げかけられました。
そこで私たちは、まさにそのためのちょっとしたスクリプトを書き上げました。GitHubで公開しています。いくつかの環境変数を設定すると、組織レベルでサービスアカウントをプロビジョニングし、その組織内のすべてのプロジェクトとデータセットをループ処理し、データセット内のテーブルと関連する詳細情報(今回の場合はテーブルサイズ)を取得します。基本的なPythonの知識とBigQuery APIへの理解は必要ですが、このアプローチなら最大限の柔軟性が得られます(APIドキュメントを参照すれば、その他のテーブル属性も取得可能)。さらに、後続処理で扱いやすい任意のフォーマットでデータを書き出すこともできます。
メリット:
- 最大限の柔軟性:
- APIから必要なデータをすべて抽出できる。
- 出力結果も自由なフォーマットで生成できる。
- フィルタの追加やスクリプトの拡張も思いのまま。
- 無料、DoiTからあなたへ。
デメリット:
- スクリプトを書くために多少の時間と労力がかかる。とはいえ、その大部分はすでに私たちが済ませています!
BigQueryを使いこなすのは一筋縄ではいきませんが、各手法にはそれぞれ組織のニーズに応じた強みがあります。標準ツールはシンプルさと手軽さが魅力で、カスタムスクリプトは多少の初期工数と引き換えに、他にはない柔軟性と詳細度を手に入れられます。
これまでに別のアプローチを試されたことはありますか?お気に入りの方法をぜひシェアしてください。あるいは、基本のスクリプトをご自身のニーズに合わせて拡張してみてはいかがでしょうか。