In questo articolo confrontiamo i diversi approcci per ottenere visibilità sul footprint di BigQuery e vi presentiamo uno script Python personalizzato che garantisce la massima flessibilità.
Introduzione
Nel mondo in continua evoluzione della data analytics, Google BigQuery si distingue come un potente data warehouse serverless che permette di eseguire query SQL fulminee su dataset di enormi dimensioni. Che siate data scientist, data engineer o esperti di analytics, muoversi tra le innumerevoli funzionalità di BigQuery può spesso assomigliare a una caccia al tesoro. Man mano che la vostra organizzazione cresce, cresce con essa anche il footprint di BigQuery: una delle sfide più comuni è proprio quella di elencare in modo efficiente tabelle e dataset nei diversi ambiti.
Questo articolo vuole guidarvi tra i vari metodi per elencare tabelle e dataset in BigQuery, con l'obiettivo finale di censire questi asset nell'intera organizzazione, mettendo in luce strada facendo i limiti intrinseci di ciascun approccio.
Mentre approfondiremo le diverse tecniche, dalle interazioni di base via GUI alle query SQL e alle chiamate API più avanzate, scoprirete punti di forza e vincoli di ognuna. In chiusura presenteremo una soluzione che offre la massima flessibilità ma richiede un po' più di lavoro — anche se, in realtà, il grosso lo abbiamo già fatto noi per voi!
Esamineremo le seguenti opzioni:
- Web UI di Google Cloud Console
- BigQuery CLI
- Dataplex (Data Catalog)
- INFORMATION_SCHEMA
- Script personalizzato
E lungo il percorso terremo presenti alcune dimensioni di valutazione:
- Ambito dell'elenco
- Livello di dettaglio
- Flessibilità
- Costo
Web UI di Google Cloud Console
Un buon punto di partenza è la familiare Web UI di Google Cloud Console. Aprendo BigQuery Studio dalla pagina del prodotto BigQuery, trovate dataset e tabelle del progetto corrente (e di altri progetti che avete aggiunto) organizzati nel pannello Explorer. Vi consente inoltre di cercare risorse (dataset, tabelle o viste) per nome o etichetta, restituendo risultati che spaziano sia tra i progetti sia tra le organizzazioni a cui avete accesso.
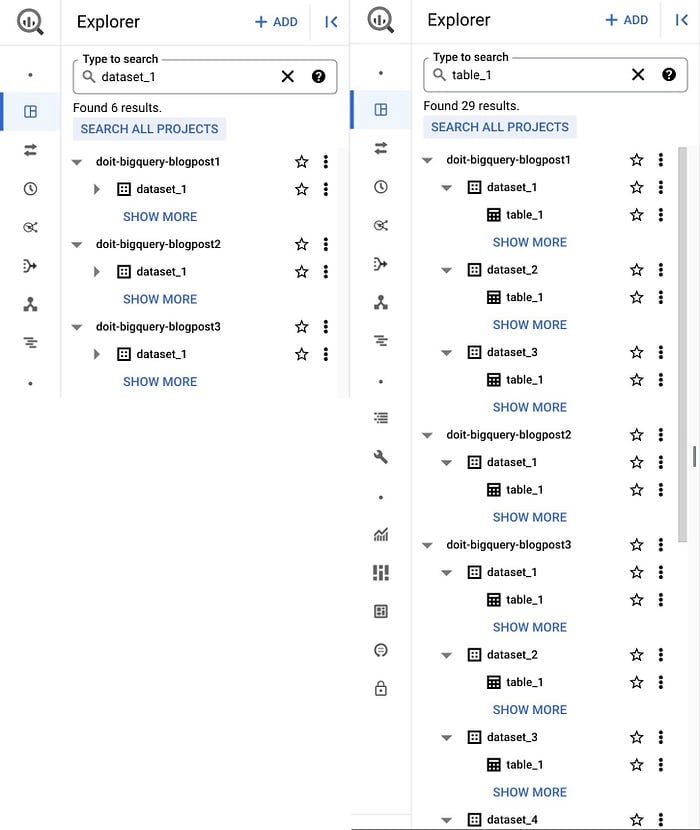
UI di BigQuery: Dataset (a sinistra) e Tabelle (a destra)
Pro:
- È facilmente accessibile da BigQuery Studio.
- Può effettuare ricerche su
progettieorganizzazioni, quindi non ha limiti di ambito. - L'approccio è gratuito.
Contro:
- Non fornisce un elenco esaustivo di tutti i dataset o le tabelle della vostra organizzazione né di quelli a cui avete accesso.
- Non restituisce altri metadati sulle tabelle.
BigQuery CLI
Se non amate particolarmente le UI e preferite lavorare da riga di comando, la BigQuery CLI fa al caso vostro.
Dato un PROJECT_ID, potete elencare tutti i dataset di quel progetto con:
bq ls --project_id $PROJECT_ID

Dataset tramite BigQuery CLI
Oppure, indicando sia PROJECT_ID che DATASET_ID, potete elencare tutte le tabelle di quel dataset con:
bq ls --project_id $PROJECT_ID --dataset_id=$DATASET_ID

Tabelle tramite BigQuery CLI
Pro:
- CLI semplice da usare.
- L'output si presta a elaborazioni leggere a valle, ad esempio con
jq, soprattutto sfruttando il flag--format: <none|json|prettyjson|csv|sparse|pretty>. - Le operazioni sui metadati sono gratuite.
Contro:
- L'ambito dell'elenco è limitato: a livello di dataset si ferma al progetto, a livello di tabella al singolo dataset.
- Anche i dettagli restituiti nell'elenco sono limitati.
Dataplex (Data Catalog)
Quando si pensa a come trovare tutti i dati rilevanti della propria organizzazione, Data Catalog è la prima cosa che viene in mente! Un tempo era un prodotto a sé stante, ma dalla metà del 2022 è una funzionalità di Dataplex. Dataplex è la piattaforma intelligente di data management di Google Cloud che automatizza organizzazione, sicurezza e analisi dei dati su data lake, warehouse e database, supportando la vostra organizzazione su discoverability, governance e compliance. Data Catalog funge da inventario centrale degli asset di dati dell'organizzazione.
Permette di effettuare ricerche tra organizzazioni e sistemi e di filtrare per tipi di dato, tag e così via. Per il nostro caso d'uso, possiamo recuperare tutti i dataset e le tabelle di una specifica organizzazione semplicemente impostando il filtro adeguato nella UI:
L'aspetto interessante è che, per chi preferisce la CLI alla UI, è possibile ottenere lo stesso risultato con un comando gcloud:
Per i dataset:
gcloud data-catalog search "type=dataset" --include-organization-ids=YOUR_ORG_ID
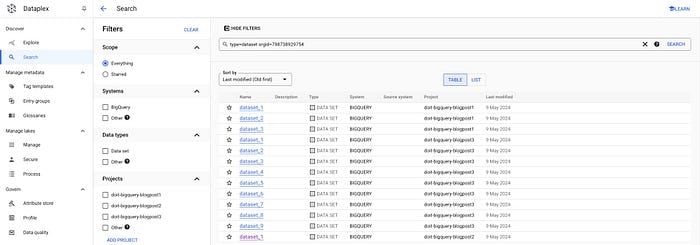
Dataset in Dataplex
Per le tabelle:
gcloud data-catalog search "type=table" --include-organization-ids=YOUR_ORG_ID
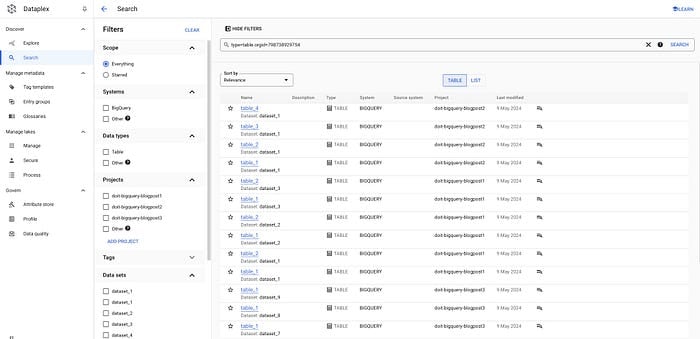
Tabelle in Dataplex
Pro:
- Effettua ricerche tra organizzazioni E va oltre la sola ricerca su BigQuery.
Contro:
- Data Catalog memorizza diversi tipi di metadati (sia di business sia tecnici), ma non include alcuni dettagli come la dimensione della tabella o il totale dei byte memorizzati.
- Né Dataplex né Data Catalog sono gratuiti, anche se i costi sono in genere contenuti per la maggior parte dei casi d'uso. Per i dettagli, consultate la pagina dei prezzi.
INFORMATION\_SCHEMA
Gli appassionati di BigQuery conosceranno sicuramente INFORMATION_SCHEMA. Le viste INFORMATION_SCHEMA di BigQuery sono viste di sola lettura, definite dal sistema, che forniscono metadati sugli oggetti BigQuery. Esiste un'ampia gamma di viste differenti: consultate la documentazione per una panoramica completa.
Per il nostro caso d'uso ci interessano in particolare la vista SCHEMATA e la vista TABLES:
Possiamo usare la vista SCHEMATA per elencare tutti i dataset di una regione, ad esempio us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.SCHEMATA;
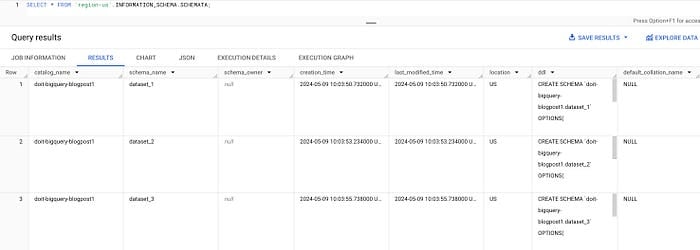
Dataset tramite INFORMATION_SCHEMA
Oppure possiamo usare la vista TABLES per elencare tutte le tabelle di una regione, ad esempio us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.TABLES;
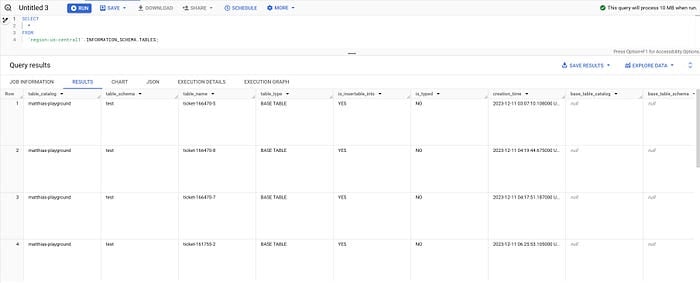
Tabelle tramite INFORMATION_SCHEMA
Pro:
- Accesso semplice e programmatico tramite SQL direttamente in BigQuery.
- Informazioni molto dettagliate; ad esempio la vista
TABLESincludecreation_timeeddl, mentre la vistaTABLE_STORAGEcontiene informazioni sutotal_rowse sulla dimensione della tabella (sia storage fisico sia logico).
Contro:
- L'ambito massimo delle informazioni è la singola regione (anche per la vista a livello di organizzazione). Considerato che l'elenco delle regioni è già piuttosto lungo e può cambiare nel tempo, costruirci attorno uno script non è la soluzione ideale.
- Non è gratuito, anche se i costi sono in genere contenuti per la maggior parte dei casi d'uso.
Massima libertà con uno script personalizzato
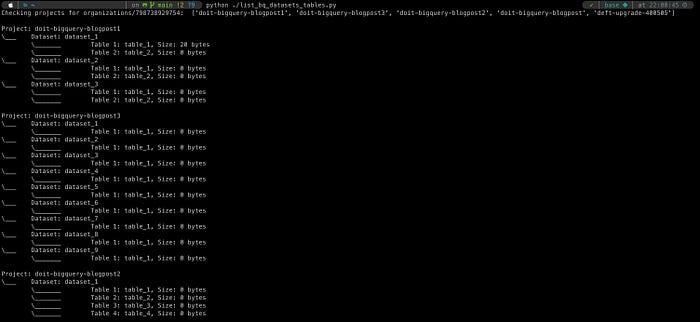
Come spesso accade, i nostri clienti più tecnicamente smaliziati ci hanno sfidato chiedendoci visibilità sull'intera organizzazione, oltre al recupero di dettagli significativi sulle tabelle distribuite tra i progetti.
Abbiamo quindi scritto un piccolo script che fa esattamente questo, e che potete trovare anche sul nostro GitHub. Prevede l'impostazione di alcune variabili d'ambiente che provisionano un service account a livello di organizzazione, per poi iterare su tutti i progetti e i dataset di quell'organizzazione, recuperando le tabelle al loro interno insieme ai dettagli rilevanti (in questo caso: la dimensione della tabella). Sono richieste conoscenze di base di Python e una certa familiarità con la BigQuery API, ma in cambio si ottiene la massima flessibilità (consultando la documentazione API è possibile recuperare altre caratteristiche delle tabelle) e i dati possono essere scritti in qualsiasi formato, pronti per il consumo a valle.
Pro:
- Massima flessibilità:
- Estraete dall'API tutti i dati che vi servono.
- I risultati in output possono essere prodotti come preferite.
- Aggiungete filtri o estendete lo script a vostro piacimento.
- Gratuito, da DoiT a voi.
Contro:
- Richiede tempo e impegno aggiuntivi per scrivere lo script — ma gran parte del lavoro l'abbiamo già fatto noi per voi!
Muoversi all'interno di BigQuery può essere complesso e ogni metodo offre vantaggi specifici, pensati per esigenze organizzative differenti. Se gli strumenti standard garantiscono semplicità e accessibilità, lo scripting personalizzato sblocca un livello di flessibilità e dettaglio impareggiabile, sebbene richieda un po' di lavoro iniziale.
In passato avete adottato un approccio diverso? Condividete il vostro metodo preferito, oppure estendete lo script di base in base alle vostre esigenze!