Neste post, comparamos abordagens para extrair insights do seu footprint no BigQuery e apresentamos um script Python sob medida para total flexibilidade.
Introdução
No mundo em constante evolução da análise de dados, o Google BigQuery se destaca como um data warehouse serverless poderoso, capaz de rodar consultas SQL ultrarrápidas em grandes volumes de dados. Seja você cientista de dados, engenheiro de dados ou especialista em analytics, explorar tudo o que o BigQuery tem a oferecer pode parecer uma verdadeira caça ao tesouro. À medida que sua organização cresce, o footprint no BigQuery também cresce — e um dos desafios mais comuns é listar tabelas e datasets de forma eficiente em diferentes escopos.
O objetivo deste post é mostrar os vários métodos para listar tabelas e datasets no BigQuery, com a meta final de listar esses ativos em toda a sua organização, destacando as limitações de cada abordagem ao longo do caminho.
Conforme passamos pelas diferentes técnicas, das interações básicas pela GUI até consultas SQL e chamadas de API mais avançadas, você vai conhecer os pontos fortes e as limitações de cada uma. No fim, apresentamos uma solução definitiva, que oferece o máximo de flexibilidade — só que exige um pouco mais de trabalho. Ou exigiria, se a gente já não tivesse feito isso por você!
Vamos passar pelas seguintes opções:
- Web UI do Google Cloud Console
- BigQuery CLI
- Dataplex (Data Catalog)
- INFORMATION_SCHEMA
- Script personalizado
E vamos avaliar cada uma sob algumas dimensões:
- Escopo da listagem
- Nível de detalhe
- Flexibilidade
- Preço
Web UI do Google Cloud Console
Um bom ponto de partida é a já conhecida web UI do Google Cloud Console. Ao abrir o BigQuery Studio, dentro da página do produto BigQuery, você encontra os datasets e tabelas do projeto atual (e de outros projetos que tenha adicionado) organizados no painel Explorer. Dá pra buscar recursos (dataset, tabela ou view) por nome ou label, e os resultados abrangem tanto projects quanto organisations aos quais você tenha acesso.
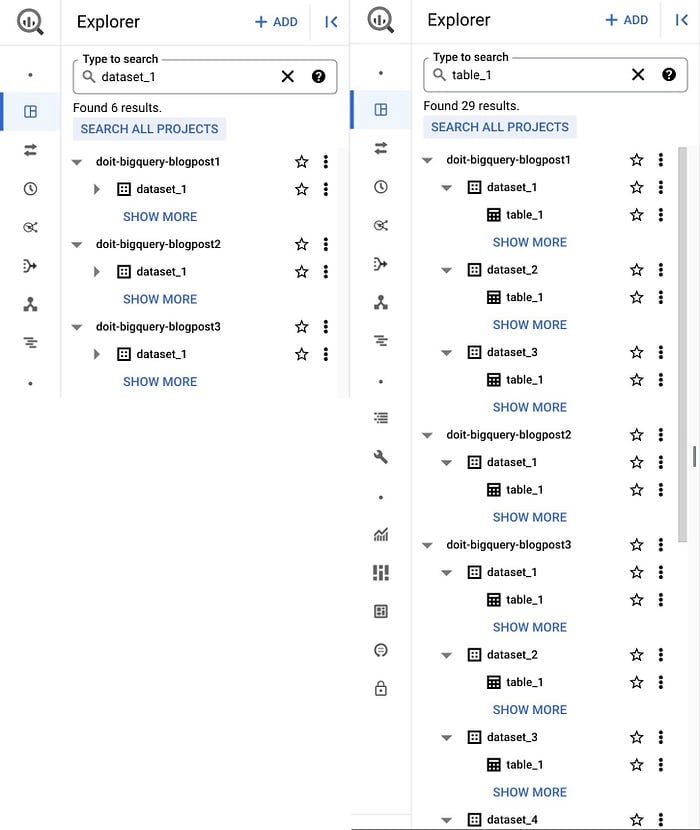
Datasets (esquerda) e Tabelas (direita) na UI do BigQuery
Prós:
- Fácil de acessar pelo BigQuery Studio.
- Faz buscas em
projectseorganisations, sem limitação de escopo. - É de graça.
Contras:
- Não traz uma lista exaustiva de todos os datasets ou tabelas da sua organização ou aos quais você tem acesso.
- Não traz outros metadados sobre as tabelas.
BigQuery CLI
Se você não curte muito UIs e prefere viver na linha de comando, talvez se interesse mais pelo BigQuery CLI.
Com um PROJECT_ID, dá pra listar todos os datasets do projeto com o comando:
bq ls --project_id $PROJECT_ID

Datasets no BigQuery CLI
Ou, com PROJECT_ID e DATASET_ID, dá pra listar todas as tabelas do dataset:
bq ls --project_id $PROJECT_ID --dataset_id=$DATASET_ID

Tabelas no BigQuery CLI
Prós:
- CLI fácil de usar.
- A saída pode ser usada em processamentos leves downstream com
jq, por exemplo, principalmente com a flag--format: <none|json|prettyjson|csv|sparse|pretty>. - Operações de metadados são gratuitas.
Contras:
- O escopo da listagem é limitado: um projeto para o nível de dataset e um dataset para o nível de tabela.
- Os detalhes retornados também são limitados.
Dataplex (Data Catalog)
Quando o assunto é encontrar todos os dados relevantes da organização, o Data Catalog vem logo à cabeça! O Data Catalog era um produto à parte, mas virou um recurso do Dataplex em meados de 2022. O Dataplex é a plataforma inteligente de gestão de dados do Google Cloud, que automatiza a organização, segurança e análise de dados em data lakes, warehouses e bancos de dados, ajudando sua organização com descoberta, governança e compliance. O Data Catalog funciona como o inventário central dos ativos de dados da sua organização.
Ele permite buscar entre organizações e sistemas, filtrar por tipos de dados, tags etc. Para o nosso caso específico, dá pra recuperar todos os datasets e tabelas dentro de uma organização específica usando o filtro adequado na UI:
O legal é que, para quem prefere CLI no lugar da UI, dá pra fazer a mesma coisa com um comando gcloud:
Para datasets:
gcloud data-catalog search "type=dataset" --include-organization-ids=YOUR_ORG_ID
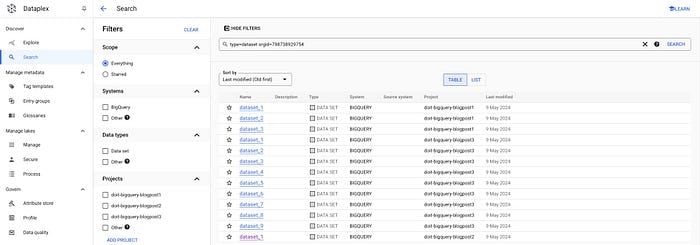
Datasets no Dataplex
Para tabelas:
gcloud data-catalog search "type=table" --include-organization-ids=YOUR_ORG_ID
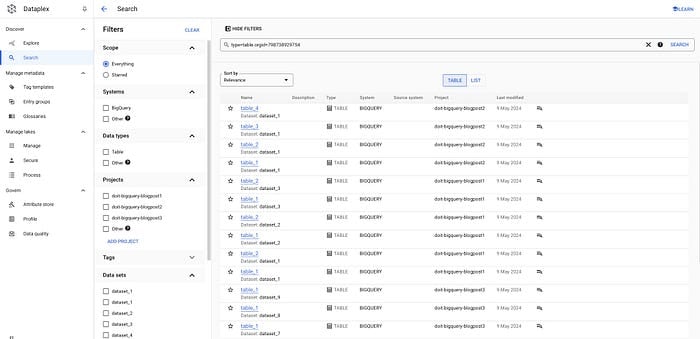
Tabelas no Dataplex
Prós:
- Busca entre organizações E vai além do BigQuery.
Contras:
- O Data Catalog armazena diferentes tipos de metadados (de negócio e técnicos), mas deixa de fora alguns detalhes, como tamanho da tabela ou total de bytes armazenados.
- Nem o Dataplex nem o Data Catalog são gratuitos, embora o preço costume caber bem na maioria dos casos. Veja a página de preços para mais detalhes.
INFORMATION\_SCHEMA
Quem é fã de BigQuery com certeza já conhece o INFORMATION_SCHEMA. As views INFORMATION_SCHEMA do BigQuery são views somente leitura, definidas pelo sistema, que fornecem metadados sobre seus objetos do BigQuery. São muitas views diferentes; consulte a documentação para uma visão completa.
Para o nosso caso, o que mais interessa são as views SCHEMATA e TABLES:
Dá pra usar a view SCHEMATA para listar todos os datasets de uma região. Por exemplo, para us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.SCHEMATA;
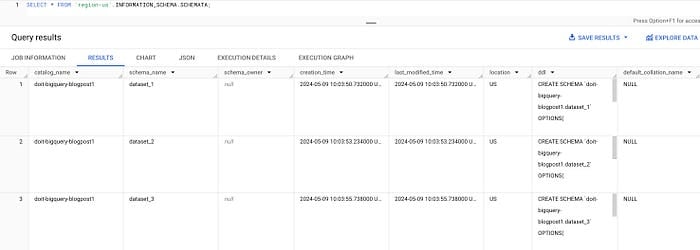
Datasets no INFORMATION_SCHEMA
Ou usar a view TABLES para listar todas as tabelas de uma região. Por exemplo, para us-central1:
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.TABLES;
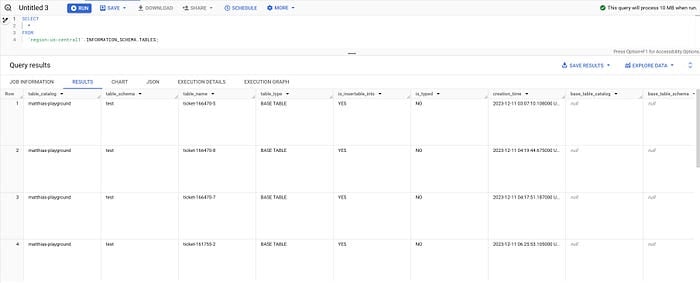
Tabelas no INFORMATION_SCHEMA
Prós:
- Acesso fácil e programático com SQL direto no BigQuery.
- Informações bem detalhadas. Por exemplo, a view
TABLESincluicreation_timeeddl, e a viewTABLE_STORAGEtraz informações sobretotal_rows, além do tamanho da tabela (armazenamento físico e lógico).
Contras:
- Informações limitadas, no máximo, ao escopo de uma região (mesmo na view de nível organizacional). Como a lista de regiões já é bem extensa e pode mudar dinamicamente, fazer scripts para lidar com isso pode não ser o ideal.
- Não é gratuito, embora o preço costume caber bem na maioria dos casos.
Total liberdade com scripting personalizado
Como sempre, nossos clientes mais técnicos nos desafiaram com a demanda de ter visibilidade em toda a organização e, ao mesmo tempo, obter detalhes relevantes sobre as tabelas em todos os projetos.
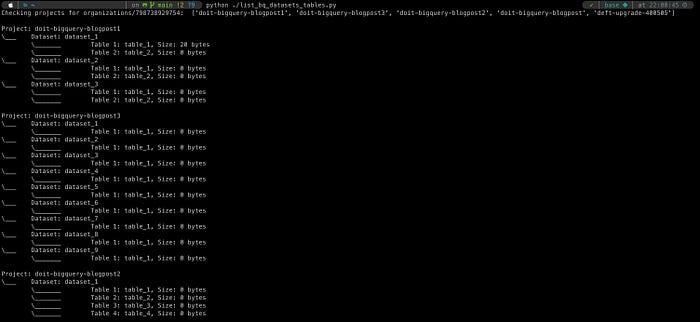
Acabamos escrevendo um pequeno script que faz exatamente isso, e que você também encontra no nosso GitHub. Basta definir algumas variáveis de ambiente, que provisionam uma service account no nível da organização, e o script percorre todos os projetos e datasets dessa organização, recuperando as tabelas dentro de cada dataset com os detalhes relevantes (neste caso, o tamanho da tabela). Mesmo que você precise de um conhecimento básico de Python e alguma familiaridade com a API do BigQuery, essa abordagem é a mais flexível (dá pra recuperar outras características da tabela consultando os docs da API), e os dados podem ser gravados no formato que você quiser para uso downstream.
Prós:
- Flexibilidade máxima:
- Extraia da API todos os dados que quiser.
- Exporte os resultados do jeito que preferir.
- Adicione filtros ou estenda o script à vontade.
- Gratuito, da DoiT para você.
Contras:
- Dá um trabalho a mais escrever o script — mas a gente já adiantou boa parte por você!
Navegar pelo BigQuery pode ser complexo, e cada método tem vantagens próprias para diferentes necessidades organizacionais. Enquanto as ferramentas padrão entregam simplicidade e acessibilidade, o scripting personalizado libera um nível de flexibilidade e detalhe sem igual — em troca de algum esforço inicial.
Você já adotou outra abordagem? Compartilhe sua forma preferida ou estenda o script básico para atender às suas necessidades!