Dans cet article, nous comparons plusieurs approches pour explorer votre empreinte BigQuery et nous vous présentons un script Python sur mesure pour une flexibilité totale.
Introduction
Dans l'univers en pleine effervescence de l'analytique, Google BigQuery se distingue comme un data warehouse serverless puissant, capable d'exécuter des requêtes SQL ultra-rapides sur d'immenses datasets. Que vous soyez data scientist, data engineer ou expert analytique, explorer l'étendue des fonctionnalités de BigQuery s'apparente souvent à une chasse au trésor. À mesure que votre organisation grandit, son empreinte BigQuery s'étend avec elle, et l'un des défis récurrents consiste à lister efficacement tables et datasets selon différents périmètres.
Cet article a pour but de vous guider à travers les différentes méthodes permettant de lister tables et datasets dans BigQuery, avec pour objectif final de répertorier ces ressources à l'échelle de toute l'organisation, tout en mettant en lumière les limites propres à chaque approche.
En passant en revue ces techniques, des interactions de base via l'interface graphique aux requêtes SQL et appels d'API plus avancés, vous découvrirez leurs forces et leurs contraintes. Pour finir, nous présenterons une solution offrant une flexibilité maximale, mais qui demande un peu plus de travail — sauf si nous l'avons déjà fait pour vous !
Voici les options que nous allons examiner :
- Interface web Google Cloud Console
- BigQuery CLI
- Dataplex (Data Catalog)
- INFORMATION_SCHEMA
- Script personnalisé
Nous évaluerons chacune d'elles selon plusieurs critères :
- Périmètre couvert
- Niveau de détail
- Flexibilité
- Coût
Interface web Google Cloud Console
Un bon point de départ : l'interface web Google Cloud Console, que vous connaissez déjà. Depuis BigQuery Studio, accessible via la page produit BigQuery, vous retrouvez les datasets et tables de votre projet courant (et d'autres projets si vous les avez ajoutés) dans le panneau Explorer. Vous pouvez aussi y rechercher des ressources (dataset, table ou vue) par nom ou par label, avec des résultats portant à la fois sur les projects et les organisations auxquels vous avez accès.
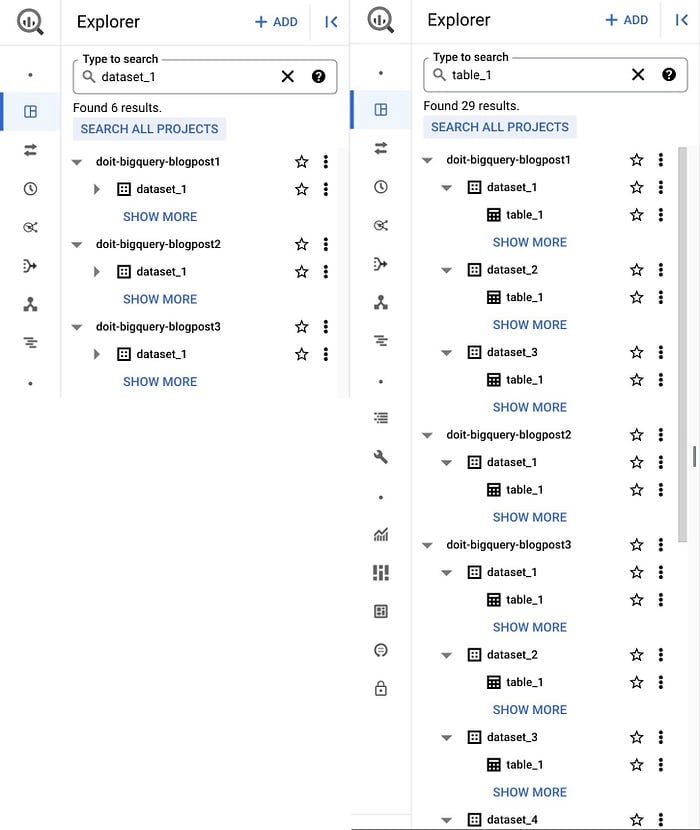
Datasets (à gauche) et tables (à droite) dans l'interface BigQuery
Avantages :
- Accès direct depuis BigQuery Studio.
- Recherche au sein des
projectset desorganisations, sans limite de périmètre. - Approche entièrement gratuite.
Inconvénients :
- Ne fournit pas la liste exhaustive des datasets ou tables de votre organisation, ni de ceux auxquels vous avez accès.
- N'expose aucune autre métadonnée sur vos tables.
BigQuery CLI
Si vous n'êtes pas adepte des interfaces graphiques et préférez la ligne de commande, BigQuery CLI sera sans doute plus à votre goût.
Pour un PROJECT_ID donné, listez tous les datasets du projet avec :
bq ls --project_id $PROJECT_ID

Datasets via BigQuery CLI
Et avec un PROJECT_ID et un DATASET_ID, listez toutes les tables du dataset :
bq ls --project_id $PROJECT_ID --dataset_id=$DATASET_ID

Tables via BigQuery CLI
Avantages :
- CLI simple à prendre en main.
- La sortie peut être traitée en aval avec des outils comme
jq, en particulier via le flag--format: <none|json|prettyjson|csv|sparse|pretty>. - Les opérations sur les métadonnées sont gratuites.
Inconvénients :
- Périmètre limité : un projet pour le niveau dataset, un dataset pour le niveau table.
- Les détails renvoyés restent eux aussi limités.
Dataplex (Data Catalog)
Quand on cherche à recenser toutes les données pertinentes d'une organisation, Data Catalog vient évidemment à l'esprit ! Auparavant produit autonome, il est devenu une fonctionnalité de Dataplex depuis mi-2022. Dataplex est la plateforme intelligente de gestion de données de Google Cloud : elle automatise l'organisation, la sécurisation et l'analyse des données à travers data lakes, data warehouses et bases de données, et accompagne votre organisation sur les volets découvrabilité, gouvernance et conformité. Data Catalog joue le rôle d'inventaire central des actifs de données de votre organisation.
Il permet de rechercher au travers des organisations et systèmes, de filtrer par type de données, par tags, etc. Pour notre cas d'usage, on peut récupérer tous les datasets et tables d'une organisation donnée en appliquant simplement le filtre adéquat dans l'UI :
Bonne nouvelle pour celles et ceux qui préfèrent la CLI à l'UI : on obtient le même résultat avec une commande gcloud.
Pour les datasets :
gcloud data-catalog search "type=dataset" --include-organization-ids=YOUR_ORG_ID
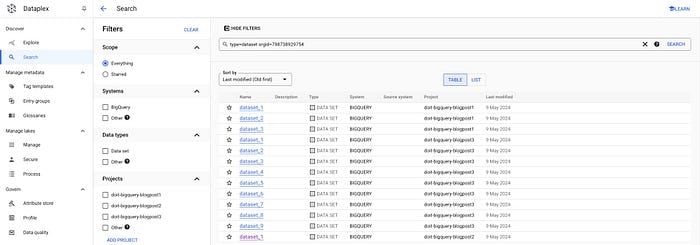
Datasets via Dataplex
Pour les tables :
gcloud data-catalog search "type=table" --include-organization-ids=YOUR_ORG_ID
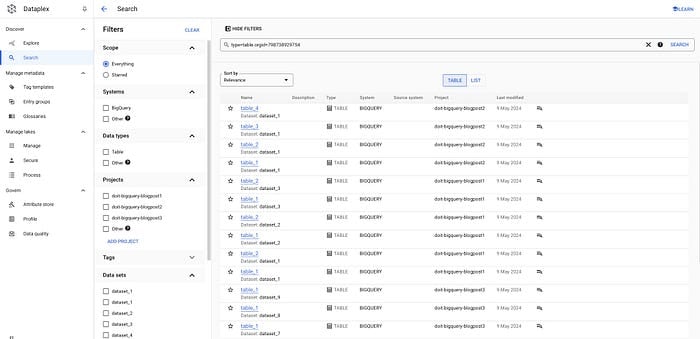
Tables via Dataplex
Avantages :
- Recherche à l'échelle de l'organisation, et bien au-delà du seul périmètre BigQuery.
Inconvénients :
- Data Catalog stocke différents types de métadonnées (métier comme techniques), mais omet certains détails comme la taille des tables ou le nombre total d'octets stockés.
- Ni Dataplex ni Data Catalog ne sont gratuits ; la facture reste toutefois raisonnable pour la plupart des cas d'usage. Voir la page de tarification pour plus de détails.
INFORMATION\_SCHEMA
Les aficionados de BigQuery connaissent forcément INFORMATION_SCHEMA. Ces vues sont des vues système en lecture seule qui exposent les métadonnées de vos objets BigQuery. Il en existe un grand nombre — la documentation en propose un panorama complet.
Pour notre cas d'usage, deux vues nous intéressent particulièrement : SCHEMATA et TABLES.
La vue SCHEMATA permet de lister tous les datasets d'une région, par exemple us-central1 :
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.SCHEMATA;
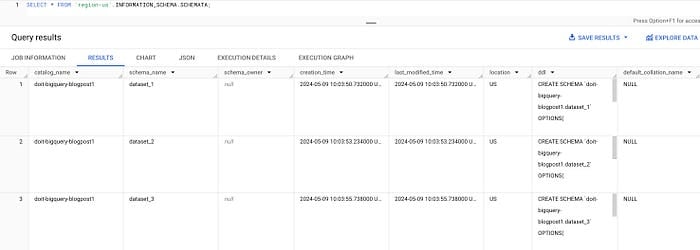
Datasets via INFORMATION_SCHEMA
La vue TABLES permet quant à elle de lister toutes les tables d'une région, par exemple us-central1 :
SELECT * FROM `region-us-central1`.INFORMATION_SCHEMA.TABLES;
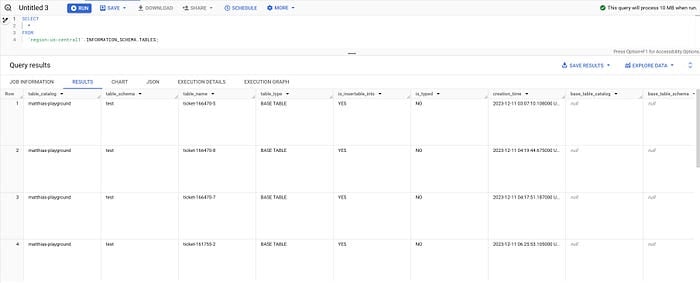
Tables via INFORMATION_SCHEMA
Avantages :
- Accès programmatique simple en SQL, directement dans BigQuery.
- Informations très détaillées : la vue
TABLESinclutcreation_timeetddl, et la vueTABLE_STORAGEdonne letotal_rowsainsi que la taille de la table (stockages physique et logique).
Inconvénients :
- Informations limitées au mieux à une région (y compris pour la vue au niveau de l'organisation). La liste des régions étant déjà longue et susceptible d'évoluer, l'industrialiser via un script n'est pas idéal.
- Payant, même si la facture reste maîtrisable pour la plupart des cas d'usage.
Une liberté totale grâce à un script personnalisé
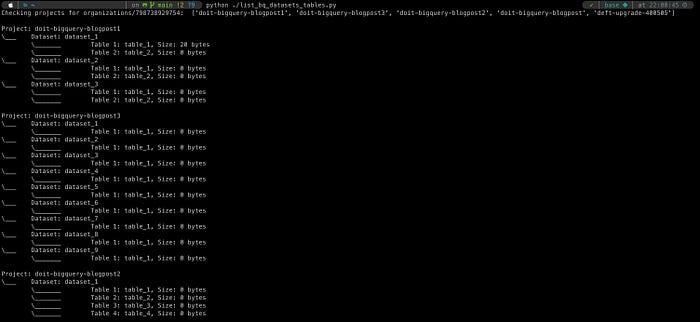
Comme à leur habitude, nos clients pointus sur le plan technique nous ont mis au défi : obtenir une visibilité sur l'ensemble de l'organisation tout en récupérant des détails substantiels sur les tables, tous projets confondus.
Nous avons fini par écrire un petit script qui fait exactement cela, disponible sur notre GitHub. Il suffit de renseigner quelques variables d'environnement : un compte de service est alors provisionné au niveau de l'organisation, puis le script parcourt l'ensemble des projets et datasets de cette organisation pour récupérer les tables qu'ils contiennent ainsi que les détails pertinents (ici, la taille des tables). Quelques notions de Python et une certaine familiarité avec l'API BigQuery sont nécessaires, mais cette approche offre une flexibilité maximale (vous pouvez récupérer d'autres attributs de table en consultant la doc de l'API), et les données peuvent être écrites dans le format de votre choix pour une exploitation en aval.
Avantages :
- Flexibilité maximale :
- Extrayez toutes les données voulues depuis l'API.
- Mettez en forme les résultats comme bon vous semble.
- Ajoutez des filtres ou étendez le script à votre guise.
- Gratuit, offert par DoiT.
Inconvénients :
- Du temps et des efforts supplémentaires pour écrire le script — mais nous avons déjà fait le gros du travail pour vous !
BigQuery peut être complexe à appréhender, et chaque méthode présente des atouts adaptés à des besoins différents. Là où les outils standards misent sur la simplicité et l'accessibilité, le scripting sur mesure ouvre la voie à une flexibilité et à un niveau de détail incomparables, au prix d'un effort initial.
Avez-vous déjà adopté une autre approche ? Partagez votre méthode préférée, ou adaptez le script de base à vos propres besoins !