セットアップ
シンプルなDataflow SQLパイプラインを作成する手順を見ていきましょう。
はじめに、以下を準備します。
- 適切なIAM権限を持つユーザーアカウント
- テーブルを作成するBigQueryデータセット
- データを格納するBigQueryテーブル
- データ取り込み用のGoogle Cloud Pub/Subトピック
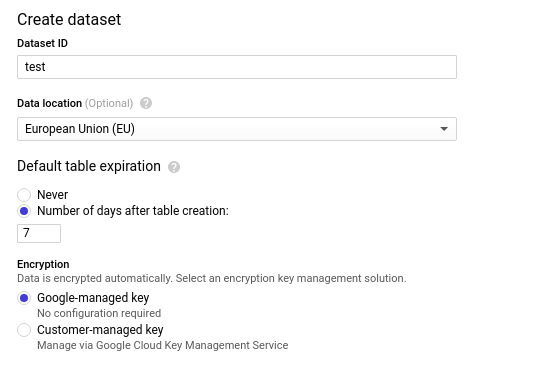
データセットを作成する:
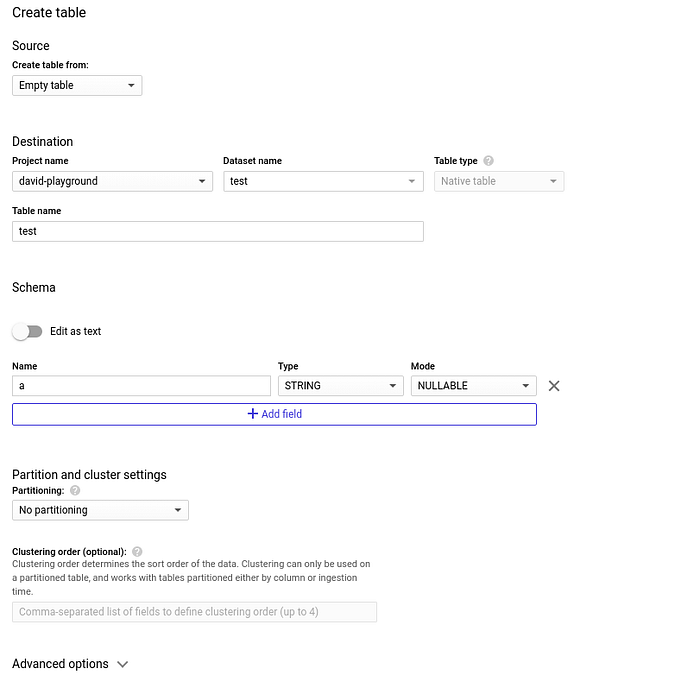
そのデータセット内にテーブルを作成する:
Pub/Subトピックを作成する:
準備が整ったら、新しいDataflow SQLエンジンに切り替えましょう。
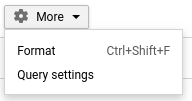
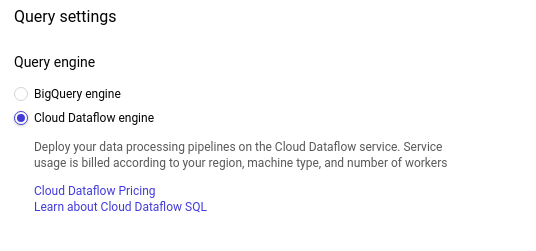
切り替えるには、クエリ設定を開きます:
Cloud Dataflowエンジンを選択します:
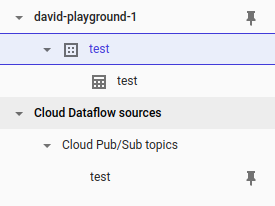
新しく利用可能になったリソースを確認します:
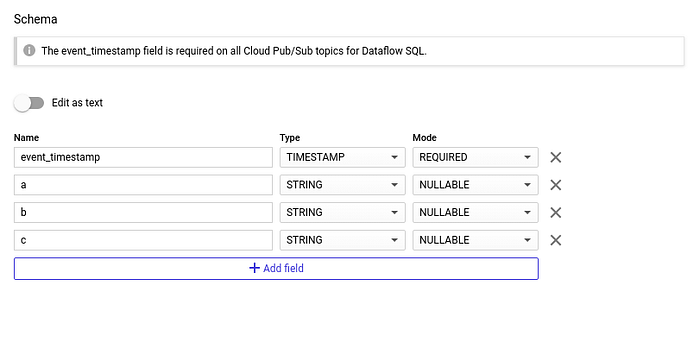
作成したGoogle Cloud Pub/Subトピックに対してクエリを実行するには、スキーマを割り当てる必要があります。作成はとても簡単で、3つの文字列フィールドと、Google Cloud Pub/Subがデフォルトで付与するタイムスタンプを定義するだけです。
トピックのスキーマを作成する:
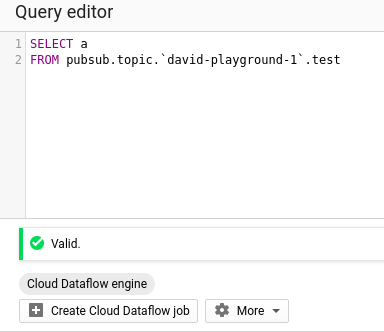
いよいよDataflow SQLジョブを作成します。
ジョブの作成
Dataflowジョブとして実行する、シンプルなSQL文を作成します。
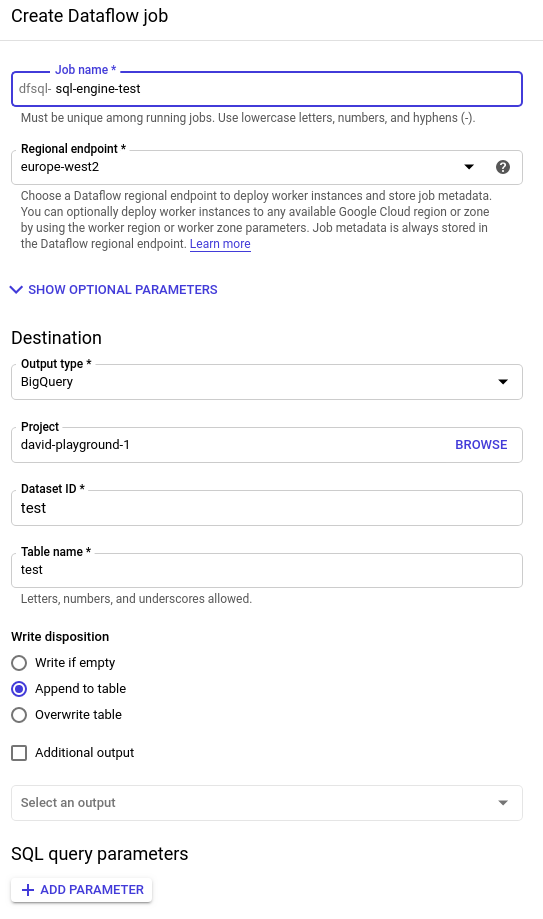
「Create Cloud Dataflow」ジョブをクリックします。ここで出力先を指定できます。実行結果を保存できる非常に便利な機能で、ETLプロセスをひととおり実現できます。
SQLから生成されたDataflowのDAGを見てみましょう。BigQueryのジョブ履歴を開きます:
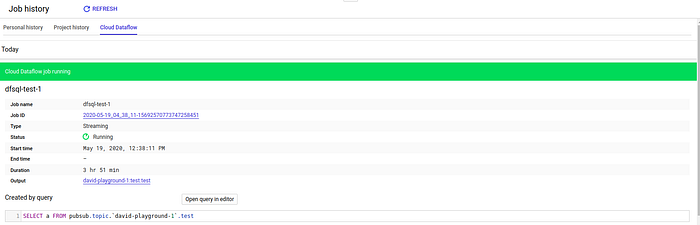
ジョブIDをクリックすると、DAGが表示されます:
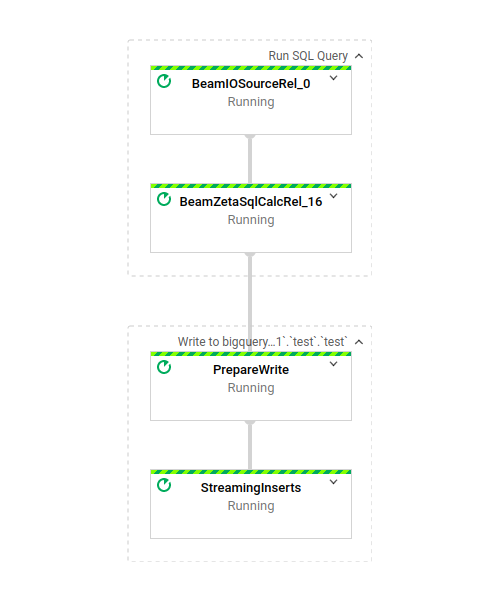
構成は非常にシンプルで、単一の変換を適用したあと、ストリーミングインサートでBigQueryテーブルに書き込むだけ。シンプルかつ強力で、Dataflowジョブの理想形と言えます。
ストリーミングパイプラインを試す
ここからは、作成したパイプラインをテストしてみましょう。ダミーのJSONデータをトピックに投入して、パイプラインの挙動を確認します。
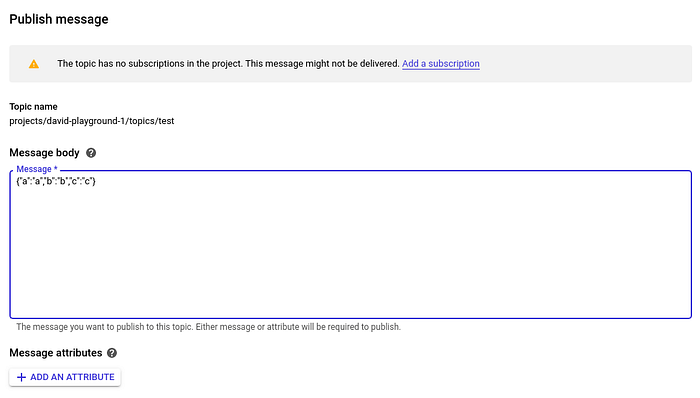
今回作成したパイプラインは、このJSONデータを受け取り、JSONフィールド「a」のみをtestテーブルに格納するはずです。
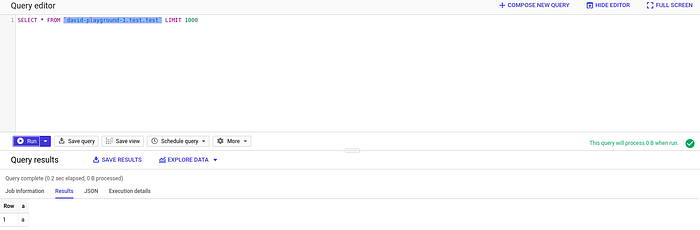
成功です!BigQueryから一歩も離れることなく、すべてSQLで記述するだけで、Google Cloud Pub/Subから流れ込むデータをフィルタリングしてBigQueryのテーブルに格納できました。
標準SQL構文を使えば、Dataflowパイプラインのセットアップとデプロイがいかに手軽にできるかがお分かりいただけたかと思います。今回はごくシンプルなクエリでしたが、より複雑なクエリも実行可能です。
本記事は、https://fluxengine.ltdに掲載された記事を基にしています。