Configuration
Voyons ensemble les étapes pour créer un pipeline Dataflow SQL très simple.
Pour démarrer, il nous faut créer plusieurs éléments :
- Un compte utilisateur disposant des autorisations IAM appropriées
- Un dataset BigQuery dans lequel créer les tables
- Une table BigQuery pour stocker les données
- Un topic Google Cloud Pub/Sub pour l'ingestion des données.
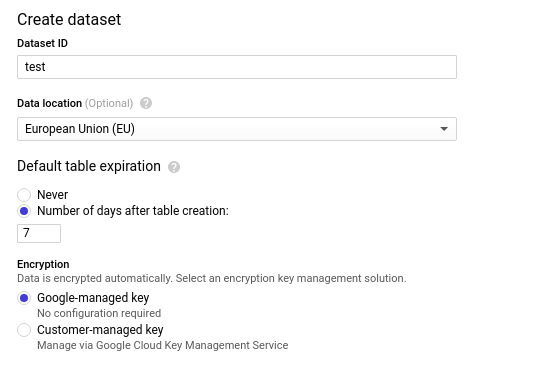
Créer un dataset :
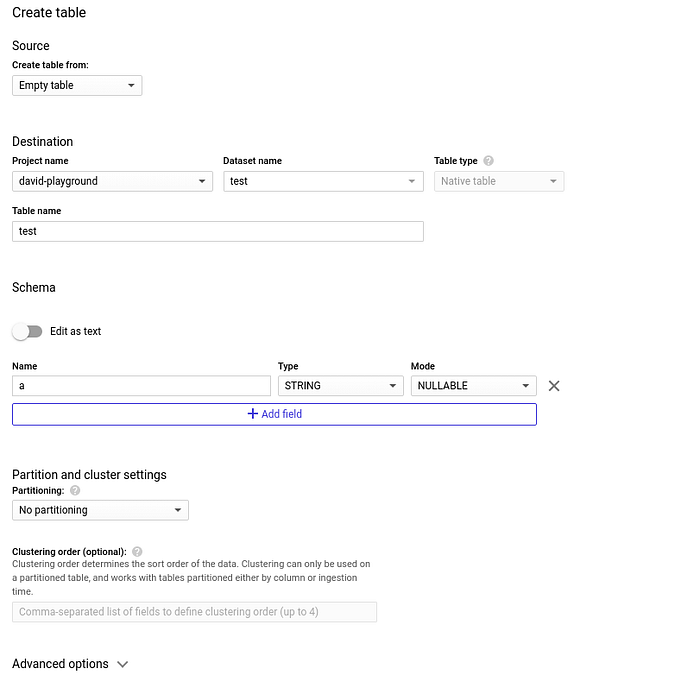
Créer une table dans ce dataset :
Créer un topic Pub/Sub :
Maintenant que tout est en place, basculons vers le nouveau moteur Dataflow SQL.
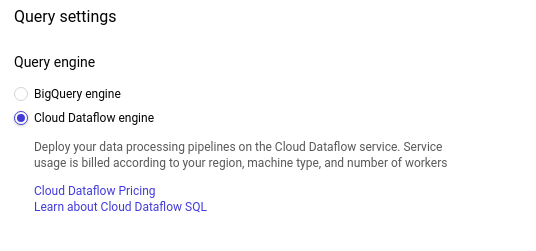
Pour cela, rendez-vous dans les paramètres de requête :
Sélectionnez le moteur Cloud Dataflow :
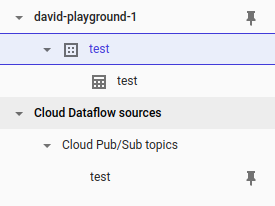
Observez les nouvelles ressources disponibles :
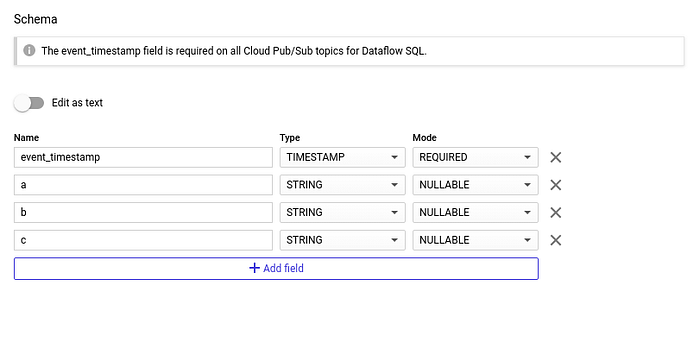
Pour interroger le topic Google Cloud Pub/Sub que nous venons de créer, il faut lui assigner un schéma. Rien de plus simple : trois champs de type string, plus l'horodatage entrant que Google Cloud Pub/Sub ajoute par défaut.
Créer le schéma du topic :
Place maintenant à la création d'un job Dataflow SQL.
Création du job
Créez une instruction SQL simple, qui s'exécutera comme un job Dataflow.
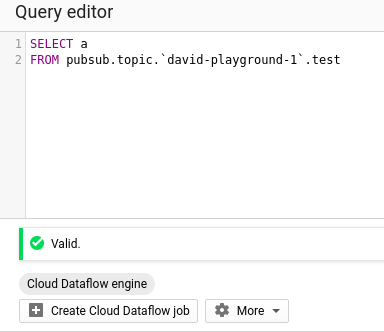
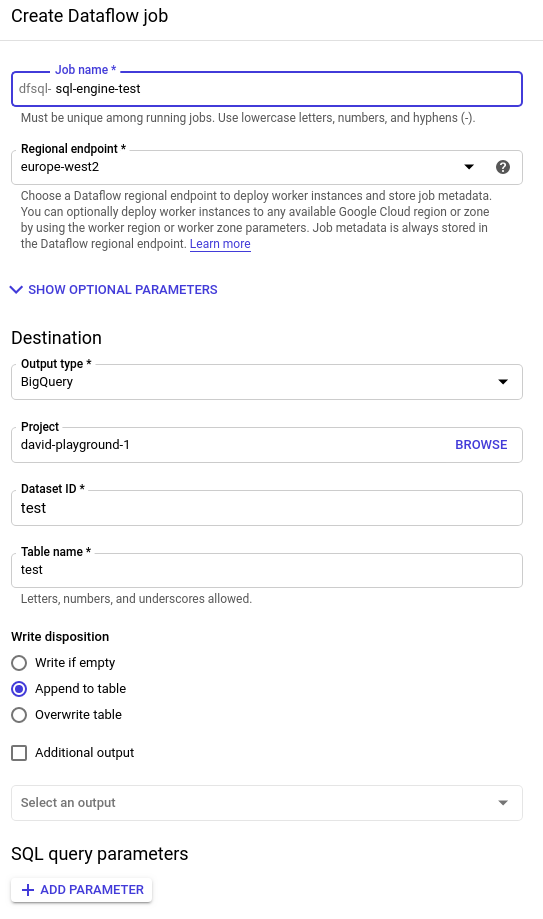
Cliquez sur Create Cloud Dataflow job. Nous pouvons désormais préciser des emplacements de sortie. Cette fonctionnalité particulièrement utile permet de sauvegarder les résultats une fois le traitement terminé, avec toute la puissance d'un processus ETL.
Examinons le DAG Dataflow généré à partir du SQL. Rendez-vous dans l'historique des jobs de BigQuery :
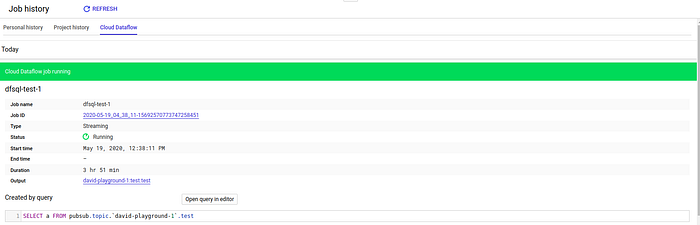
Cliquez sur l'ID du job pour visualiser le DAG :
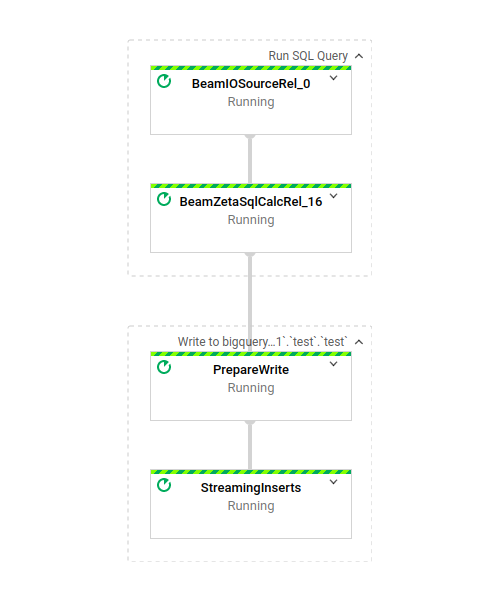
Très simple : il applique une seule transformation, puis injecte le résultat dans une table BigQuery via des streaming inserts. Simple mais puissant, un job Dataflow idéal.
Testons notre pipeline de streaming
Nous pouvons à présent tester notre pipeline. Injectons quelques données JSON fictives dans le topic et observons son comportement.
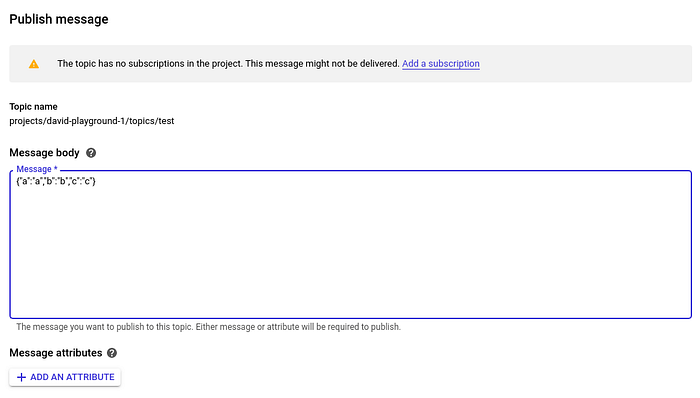
Le pipeline que nous avons créé doit prendre ces données JSON et insérer uniquement le champ JSON a dans notre table test.
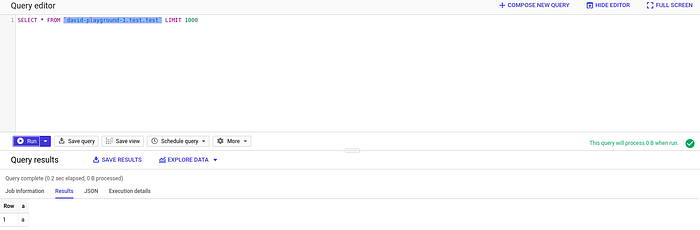
Mission accomplie ! Nous avons filtré les données entrantes de Google Cloud Pub/Sub vers une table BigQuery sans jamais quitter BigQuery — le tout en SQL.
Cela montre à quel point il est facile de configurer et de déployer des pipelines Dataflow avec la syntaxe Standard SQL. Nous nous sommes limités à une requête très simple, mais des cas bien plus complexes sont possibles.
Publié initialement sur https://fluxengine.ltd.