Setup
Gehen wir Schritt für Schritt durch, wie sich eine ganz einfache Dataflow-SQL-Pipeline aufsetzen lässt.
Für den Start brauchen wir Folgendes:
- Ein Benutzerkonto mit den passenden IAM-Berechtigungen
- Ein BigQuery-Dataset, in dem Tabellen angelegt werden
- Eine BigQuery-Tabelle zum Speichern der Daten
- Ein Google Cloud Pub/Sub-Topic für die Datenaufnahme
Dataset anlegen:
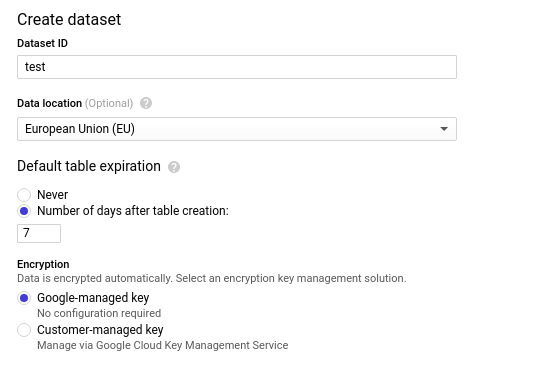
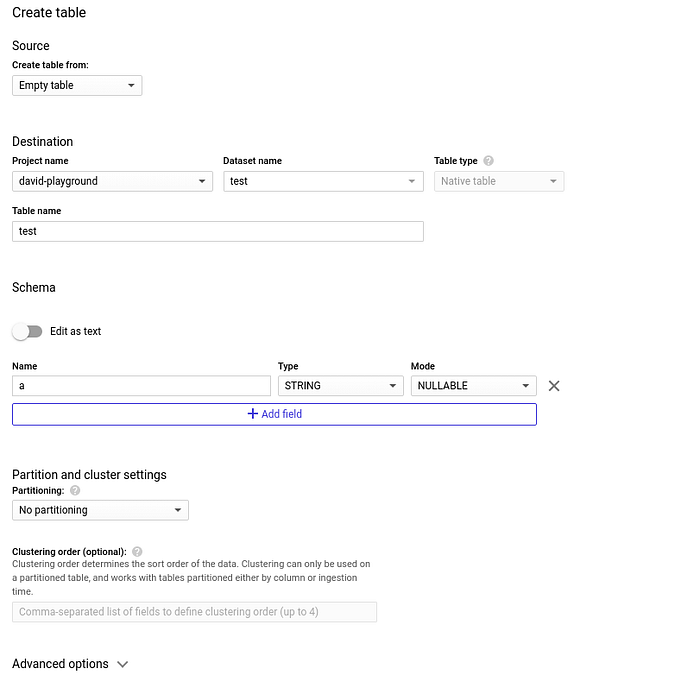
Tabelle in diesem Dataset anlegen:
Pub/Sub-Topic anlegen:
Jetzt, wo alles angelegt ist, wechseln wir zur neuen Dataflow-SQL-Engine.
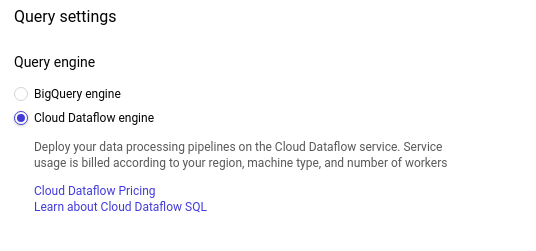
Dazu öffnen wir die Query settings:
Cloud Dataflow engine auswählen:
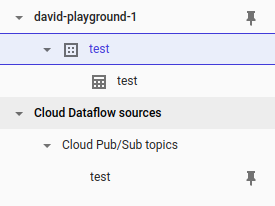
Sehen Sie sich die neu verfügbaren Ressourcen an:
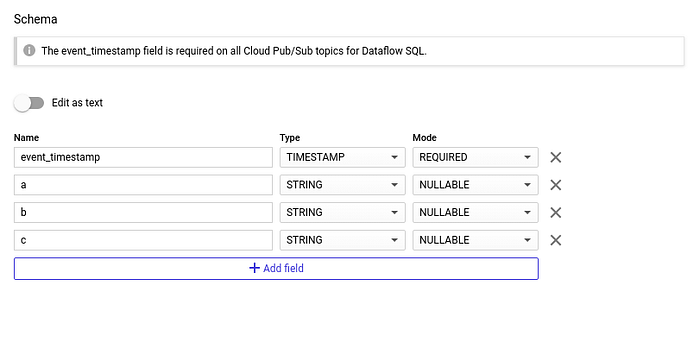
Damit wir das eben angelegte Google Cloud Pub/Sub-Topic abfragen können, müssen wir ihm ein Schema zuweisen. Das ist schnell erledigt: drei String-Felder plus der eingehende Zeitstempel, den Google Cloud Pub/Sub standardmäßig ergänzt.
Schema für das Topic anlegen:
Damit ist alles bereit für den Dataflow-SQL-Job.
Job anlegen
Schreiben Sie ein einfaches SQL-Statement, das als Dataflow-Job ausgeführt wird.
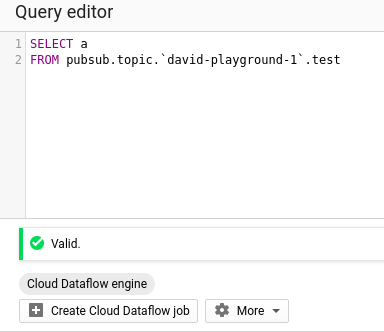
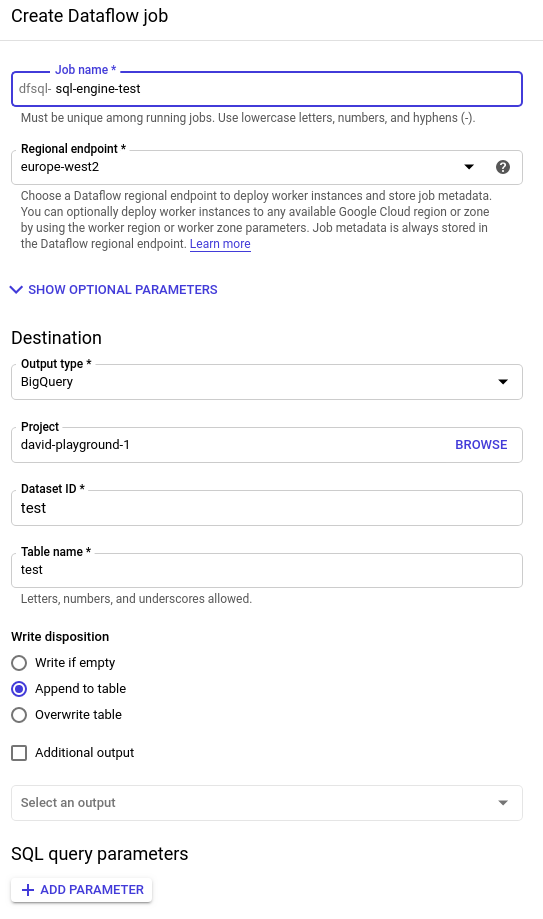
Klicken Sie auf "Create Cloud Dataflow". Jetzt lassen sich Ausgabeziele festlegen – ein ausgesprochen praktisches Feature, mit dem wir Ergebnisse direkt sichern und damit die volle Bandbreite eines ETL-Prozesses nutzen können.
Werfen wir einen Blick auf den Dataflow-DAG, der aus dem SQL entstanden ist. Öffnen Sie dazu den Job-Verlauf in BigQuery:
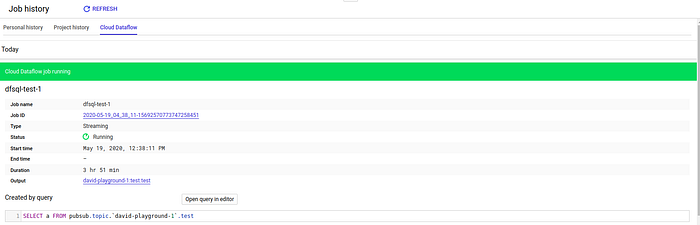
Ein Klick auf die Job-ID zeigt den DAG:
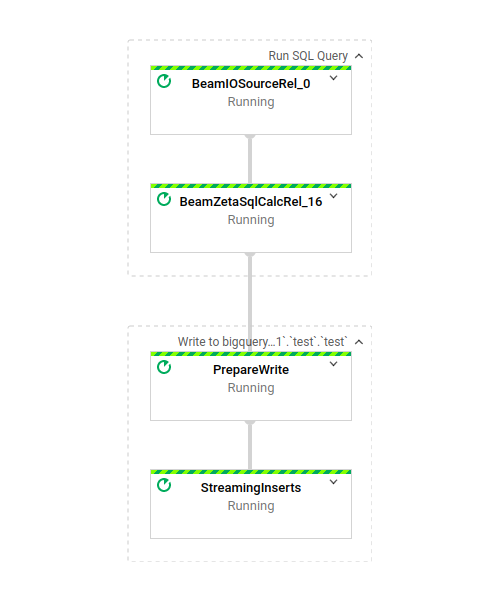
Er ist denkbar schlicht: Eine einzige Transformation wird angewendet und das Ergebnis anschließend per Streaming-Insert in eine BigQuery-Tabelle geschrieben. Einfach und trotzdem leistungsstark – ein idealer Dataflow-Job.
Streaming-Pipeline ausprobieren
Damit können wir die Pipeline testen. Schicken wir ein paar JSON-Dummy-Daten in unser Topic und schauen, was passiert.
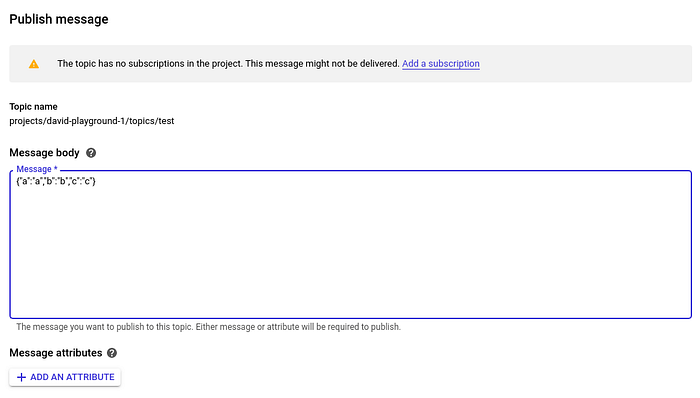
Die Pipeline soll diese JSON-Daten verarbeiten und ausschließlich das JSON-Feld "a" in unsere Tabelle test schreiben.
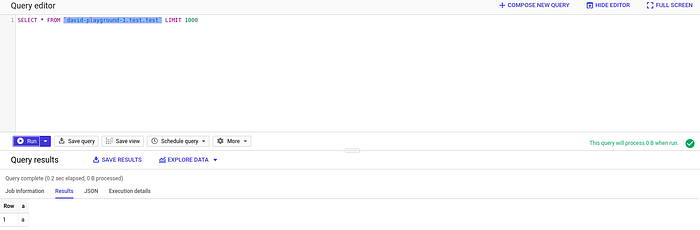
Geschafft! Eingehende Daten aus Google Cloud Pub/Sub landen gefiltert in einer BigQuery-Tabelle – ohne dass wir BigQuery je verlassen haben und komplett in SQL geschrieben.
Das zeigt, wie unkompliziert sich Dataflow-Pipelines mit Standard-SQL-Syntax aufsetzen und bereitstellen lassen. Unser Beispiel war bewusst einfach gehalten, doch deutlich komplexere Abfragen sind ebenfalls möglich.
Ursprünglich veröffentlicht auf https://fluxengine.ltd.