Configuração
Vamos seguir alguns passos para criar um pipeline bem simples no Dataflow SQL.
Para começar, precisamos criar alguns recursos:
- Uma conta de usuário com as permissões de IAM adequadas
- Um dataset no BigQuery para criar tabelas
- Uma tabela no BigQuery para armazenar os dados
- Um tópico do Google Cloud Pub/Sub para a ingestão de dados.
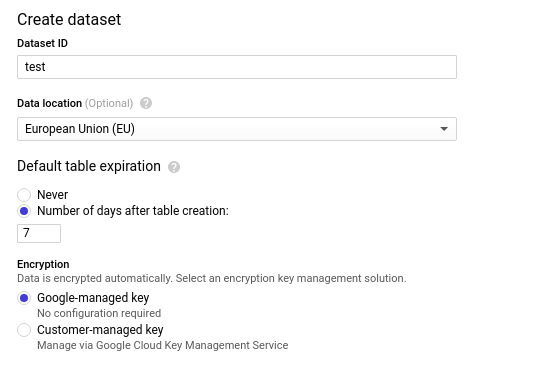
Crie um dataset:
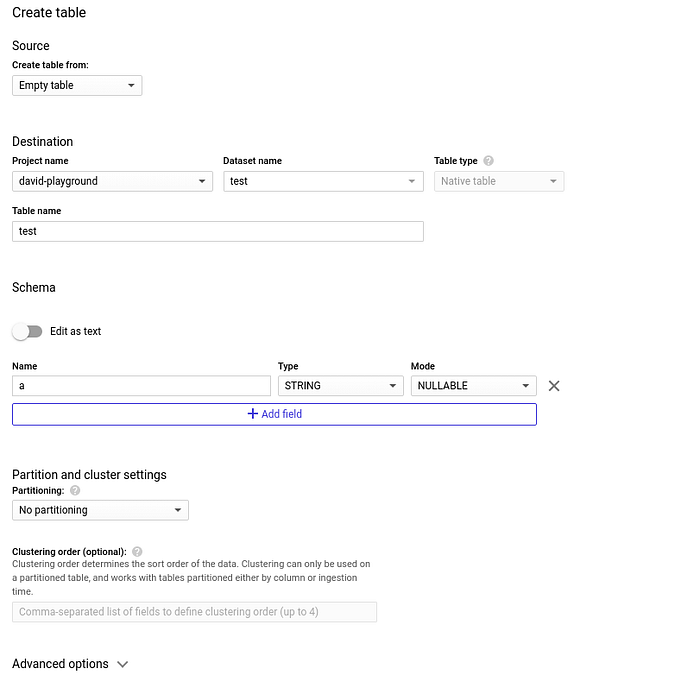
Crie uma tabela nesse dataset:
Crie um tópico no Pub/Sub:
Com tudo pronto, é hora de mudar para o novo mecanismo do Dataflow SQL.
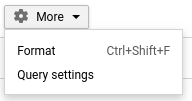
Para isso, acesse Query settings:
Selecione Cloud Dataflow engine:
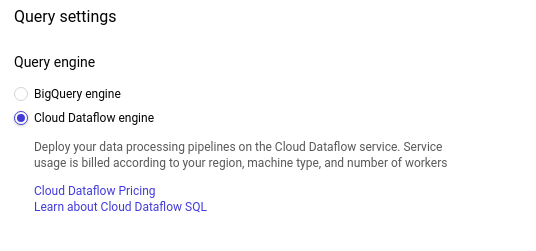
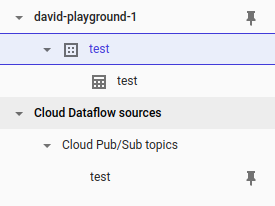
Repare nos novos recursos disponíveis:
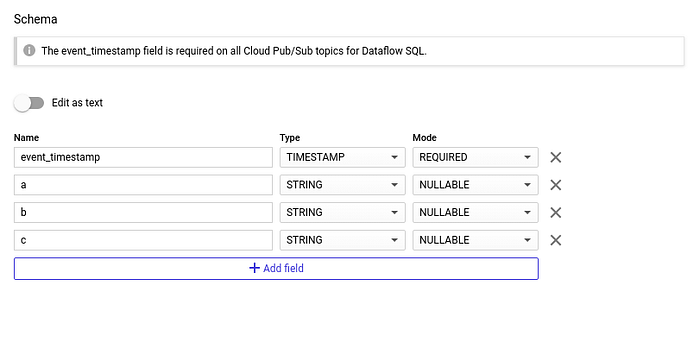
Para consultar o tópico do Google Cloud Pub/Sub que criamos, é preciso atribuir um schema a ele. Criar um é bem simples: três campos string e o timestamp de entrada que o próprio Google Cloud Pub/Sub adiciona por padrão.
Crie o schema do tópico:
Agora é hora de criar um job no Dataflow SQL.
Criação do job
Crie uma instrução SQL simples, que será executada como um job do Dataflow.
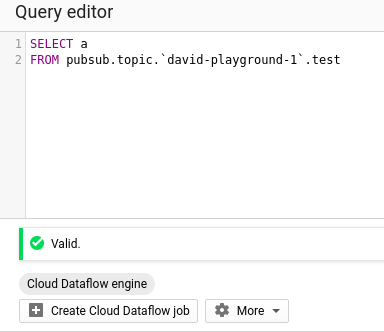
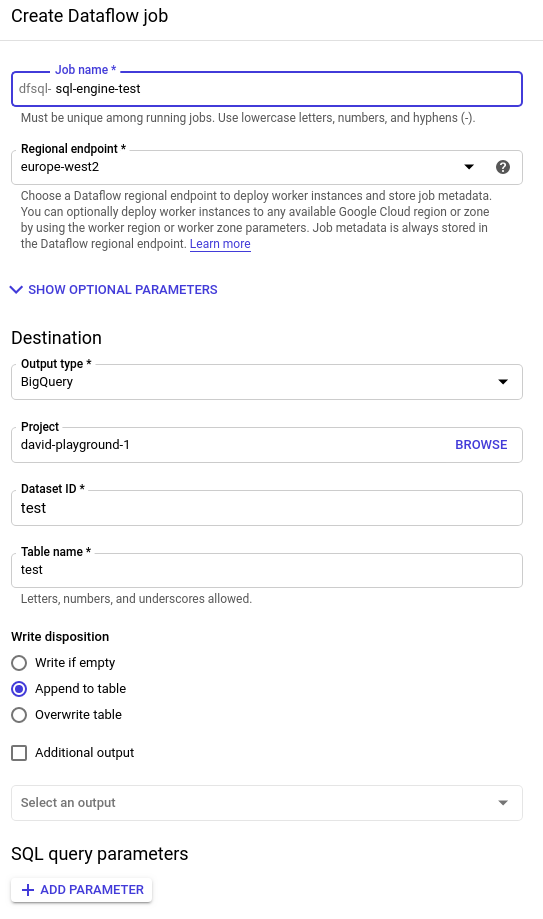
Clique em "Create Cloud Dataflow job". A partir daí, dá para definir alguns destinos de saída. Esse recurso é muito útil: ele salva os resultados ao final e entrega todo o poder de um processo de ETL.
Vamos dar uma olhada no DAG do Dataflow que criamos a partir do SQL. Acesse o histórico de jobs no BigQuery:
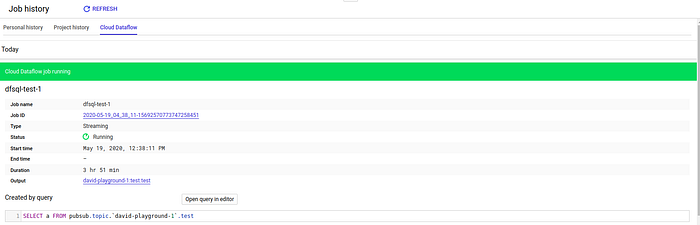
Clique no Job ID para visualizar o DAG:
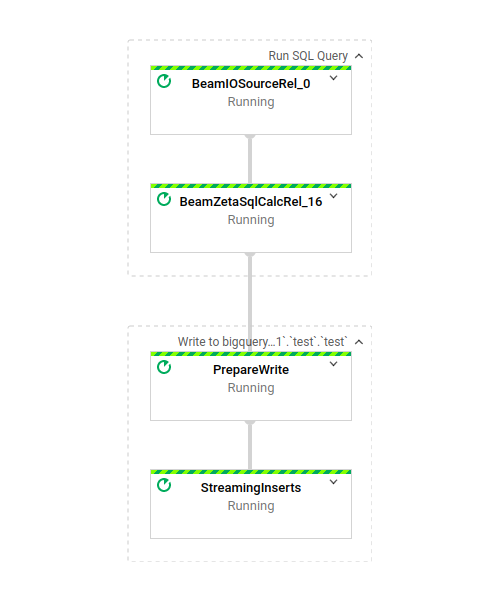
Ele é bem simples: aplica uma única transformação e grava o resultado em uma tabela do BigQuery via streaming inserts. Simples e poderoso — um job do Dataflow ideal.
Testando o pipeline de streaming
Daqui em diante, podemos testar o pipeline que acabamos de criar. Vamos enviar alguns dados JSON fictícios para o nosso tópico e ver como o pipeline reage.
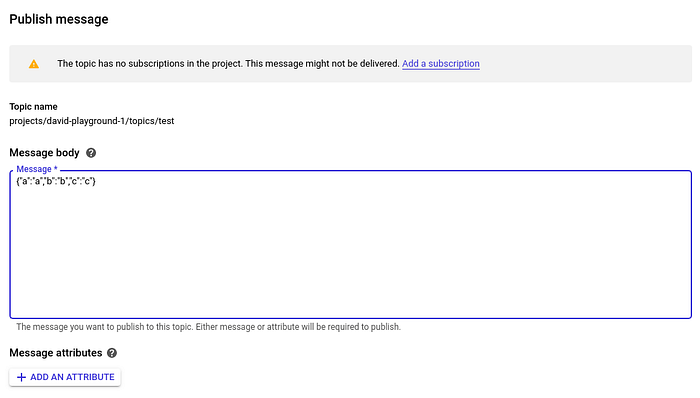
O pipeline que criamos deve receber esse JSON e gravar apenas o campo "a" na nossa tabela test.
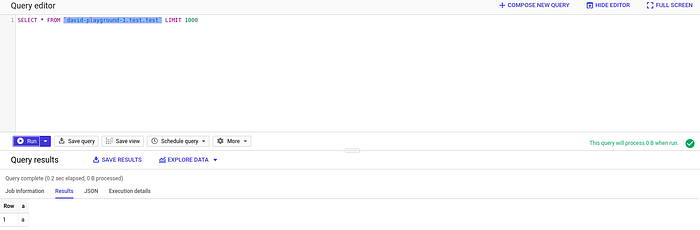
Deu certo! Filtramos os dados recebidos do Google Cloud Pub/Sub para uma tabela no BigQuery sem nunca sair do BigQuery — e tudo isso escrito em SQL.
Isso mostra como é fácil configurar e implantar pipelines do Dataflow usando a sintaxe Standard SQL. Fizemos apenas uma consulta bem simples, mas consultas mais complexas também são possíveis.
Publicado originalmente em https://fluxengine.ltd.