インターネットは広大で、今もなお拡大を続けています。2025年半ば時点で12.5億を超えるWebサイトがホストされ、年間およそ149ゼタバイトのデータが生成されています。トラフィックの過半は今やボットによるもので、その多くは悪意あるものです。こうした状況下で、組織のデジタルフットプリントを守ることの重要性はかつてなく高まっています。
DoiTでは、Attack Surface Management(ASM)を専門とするお客様と協業し、最新のAIによってこのプロセスの一部を自動化・スケールさせる方法を模索しました。目指したのは、Webを巡回してクライアントの公開資産を分析し、潜在的な脆弱性を洗い出すエージェントを、すべてAWS上で動かすことです。

ソリューションの設計
Amazon BedrockとStrands Agentsを基盤に、推論モデル、ブラウザ自動化、検索拡張生成(RAG)、本番運用レベルの可観測性を組み合わせたシステムを設計しました。
主要なAWSコンポーネントは次のとおりです。
| コンポーネント | サービス | 役割 |
| -------------------------- | ------------------------------------ | ---------------------------------------------------------- |
| **基盤モデル** | Amazon Bedrock(Claude実行) | 統一APIで最先端LLMにサーバーレスでアクセス |
| **エージェントフレームワーク** | Strands Agents | エージェントの構築とオーケストレーション用SDK |
| **ツーリング層** | Model Context Protocol(MCP) | エージェントと外部ツールをつなぐインターフェース |
| **検索** | Bedrock Knowledge Bases + OpenSearch | グラウンディングとRAG用のベクトルストア |
| **ランタイム** | AWS Fargate & Bedrock AgentCore | フルマネージドな実行環境 |
| **可観測性** | CloudWatch & LangFuse | トレース、ロギング、メトリクス |
| **Infrastructure as Code** | AWS CDK | デプロイ自動化 |
これらを組み合わせた全体像は次の図のとおりです。
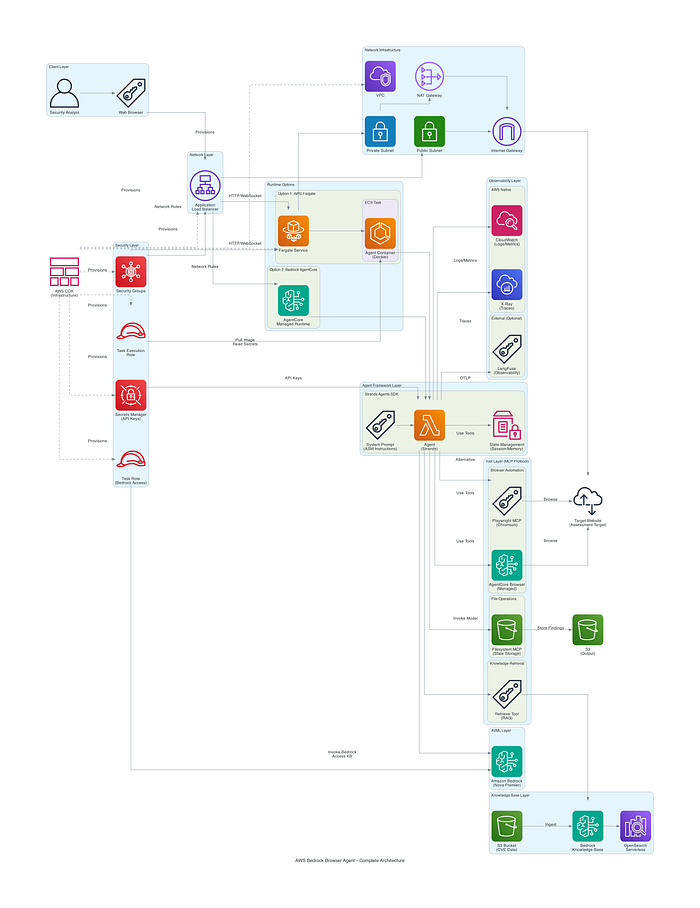
次のセクションから、それぞれを詳しく見ていきます。
推論モデルとエージェントフレームワーク
まずは基盤、つまりエージェントが「どう考えるか」から見ていきましょう。AWS Bedrockでは、AmazonのNovaファミリー、AnthropicのClaude、Mistral・DeepSeek・Llamaといったオープンソースモデルなど、高度な推論モデルに手軽にアクセスできます。これらのモデルはchain-of-thought型の推論をサポートしており、結論を出して行動に移す前に、中間的な「思考」ステップを生成できます。各ブラウジング操作と観察結果が前のステップの上に積み重なっていくため、この推論能力は欠かせません。
オーケストレーションにはStrands Agentsを採用しました。推論・ツール利用・応答生成というエージェントループのサイクルを、洗練された形で抽象化してくれます。Bedrockモデルとシームレスに統合でき、セッション状態管理、マルチエージェント連携、コンテキスト管理など、本番運用に耐えるプリミティブが揃っています。
Strandsを使えばエージェント開発がいかにシンプルになるか、コードサンプルでお見せします。
all_tools = [retrieve]
with playwright_mcp_client, filesystem_mcp_client:
playwright_tools = playwright_mcp_client.list_tools_sync()
filesystem_tools = filesystem_mcp_client.list_tools_sync()
all_tools.extend(playwright_tools + filesystem_tools)
agent = Agent(
model=bedrock_model,
system_prompt=system_prompt,
tools=all_tools,
)
このループによって、エージェントは自律的にWebを巡回し、得られた情報を推論し、ステップ間で状態を保持できます。
ツールとMCPによるアクション実行
とはいえ、推論だけでは不十分です。エージェントは外部世界とやり取りできなければなりません。
ツーリングはModel Context Protocol (MCP)で実現しました。これはLLMを外部システムに接続するためのオープン標準です。各MCPサーバーは、明確な定義とスキーマを備えた「ツール」のカタログを公開し、エージェントは実行時にそれらを動的に呼び出せます。
今回のユースケースでは、3つのツールソースを組み合わせました。
retrieve:脆弱性データベースのセマンティック検索用。- Playwright MCP:Webブラウジングおよびサイト操作用。
- Filesystem MCP:シンプルな永続ストレージとロギング用。
開発を進めていた2025年8月、AWSはAgentCoreを発表しました。専用のBrowser Toolが同梱されており、自前のPlaywrightインフラを管理する必要がなくなりました。IAM統合とCloudTrailによる可観測性を備えたフルマネージドかつ隔離されたブラウザ環境を提供してくれ、既存コードへもすんなり収まりました。
from strands_tools.browser.agent_core_browser import AgentCoreBrowser
all_tools = [retrieve, AgentCoreBrowser().browser]
Strandsのモジュール性のおかげで、自前ホスト型のブラウザツーリングから、より安全でスケーラブルなマネージドサービスへの切り替えはごく簡単に行えました。
Bedrock Knowledge Basesによるグラウンディング
エージェントが現実のデータに基づいて推論できるよう、既知の脆弱性のリポジトリであるCVE™ Programデータベースでグラウンディングを行いました。
Amazon Bedrock Knowledge BasesでCVEデータセットをアップロードすると、AWSが自動的にチャンク化・埋め込み生成・OpenSearch Serverlessへのインデックス化までを行い、すぐにクエリ可能な状態にしてくれます。
あとはretrieveツールから実行時にこのベクトルストアを照会することで、エージェントは対象となる各クライアント資産に関連する最新の脆弱性情報を取得できます。Bedrock Knowledge Basesのマネージドな取り込み・検索パイプラインのおかげで、独自RAGフローをゼロから構築する場合に比べてエンジニアリング工数を大幅に削減できました。
AWSへのエージェントのデプロイ
ローカルでプロトタイプを検証したのち、2つのマネージドランタイムを使って本番環境へ展開しました。
1. AWS Fargate
Dockerでパッケージ化し、AWS CDKでオーケストレーションするコンテナデプロイです。スケーリングとネットワークを完全にコントロールでき、より細かな制御が必要な場合や、MCPサーバーのような特殊な依存関係がある場合に最適です。
2. Amazon Bedrock AgentCore
AgentCoreはさらに高レベルの抽象化を提供します。エージェントとその設定を定義すれば、あとはAWSが代わりに実行してくれます。
わずかなコード調整、主にファイルシステムストレージからStrandsの状態管理システムへの切り替えだけで、同じエージェントがフルマネージドで動作しました。CDKやVPCの構成は不要で、AgentCoreスターターキットのagentcore configureとagentcore launchを実行するだけです。素早い反復開発と運用負荷の最小化を求めるなら、このアプローチに勝るものはありません。
可観測性と評価
エージェントの設計と同じくらい、その振る舞いを監視することも重要です。
外部の分析基盤を使いたいチームには、LangFuseがOpenTelemetry経由で手軽に組み込めます。ループ・モデル呼び出し・ツール起動の詳細なタイムラインを把握でき、エージェントが何を「考え」、どのツールを選んでいるのかをステップ単位で可視化できます。デバッグや継続的改善には欠かせない情報です。
AgentCoreのローンチ後にはAgentCore Observabilityも利用可能になりました。CloudWatchとシームレスに統合され、現在はGenAI Observabilityダッシュボードも備わっており、すべての呼び出しのトレース・メトリクス・ログをキャプチャします。開発者はトークン使用量やエラー率を可視化し、セッションを掘り下げて確認することもでき、LLMの推論というブラックボックスを測定可能なデータへと変えられます。
DoiT Cloud Intelligenceでエージェントのコストを把握
可観測性と表裏一体のテーマとして、本番デプロイ前にコストインパクトを把握しておくことも常に意識しておきたいポイントです。
DoiTでは、DoiT Cloud Intelligence™プラットフォームの一部としてGenAI Lensを提供しており、生成AI workloadsの支出パターンを分析できます。
Amazon Bedrockに加え、AnthropicやOpenAIとも直接統合し、どのモデル・どのworkloadsがコストを押し上げているのかを可視化します。
さらに踏み込んだ分析には、DataHubを使えばデータ取り込みをアプリケーションに直接組み込めます。ラベリングとカスタムダッシュボードを活用すれば、ドメイン別・顧客別のコスト追跡はもちろん、検出された脆弱性あたりのコストまで算出でき、セキュリティのインサイトを測定可能なROIへと変えられます。
今後の展望
データ取り込みから推論、可観測性まで、AWSエコシステムはこの自律型ASMエージェントを実現するための構成要素をすべて提供してくれました。安全に、スケーラブルに、そしてインフラ管理を最小限に抑えながら。AgentCoreがGAになった今、その傾向はさらに加速しています。
testphp.vulnweb.comで実施したテストでは、本システムがSQLインジェクション、反射型および格納型XSS、認証バイパス、さらにはサイトの能動的侵害シナリオまで検出できることを確認しました。これらの結果から、エージェントが自律的にWebフローを巡回し、ペイロードを入力し、実行結果を解釈し、CVEデータベースと突き合わせる一連の処理を、人手による監視を最小限に抑えて遂行できることが裏付けられました。技術的な精度にとどまらず、自律的な推論をリアルタイム検索や可観測性と組み合わせる価値、すなわち生の脆弱性スキャンを構造化された説明可能なインテリジェンスへと変える可能性も実証できました。
レポート機能の強化、既知のベンチマークでの性能評価、追加の脆弱性データベースの統合など、伸びしろはまだまだあります。しかし現状でも、このプロジェクトはAWS Bedrock + Strands Agentsが、生成AIの可能性をサイバーセキュリティの運用価値へと結実させ得ることを示しています。
すべてのソースコードと実装の詳細はGitHubで公開しており、より詳細な記事はこちらからご覧いただけます。
—
FinOpsの取り組みをよりスムーズに。doit.com/servicesからお気軽にご相談ください!