Cloud Intelligence™
Ein Blick in den Query Planner: EXPLAIN-Pläne in Amazon Neptune analysieren
Diese Seite ist auch in English, Español, Français, Italiano, 日本語 und Português verfügbar.









About Kate Gawron
Cloud database architect with 12+ years across operational and analytical platforms. AWS Ambassador. Speaker, webinar host, blogger, course creator.
Specialising in database modernisation, Aurora, RDS, Snowflake, and getting teams from raw data to production AI across EMEA.
Off the clock: strength training, cricket, and going sideways on a kart track.
My personal pageWer mit Amazon Neptune arbeitet, kennt das Gefühl: Performance-Tuning gerät leicht zur Höhlenwanderung ohne Taschenlampe. Queries werden ohne ersichtlichen Grund langsam, oder eine Gremlin-Traversierung, die mit kleinem Datensatz problemlos lief, braucht im Produktivgraphen plötzlich eine halbe Ewigkeit. Zum Glück liefert Neptune das passende Werkzeug, um Licht ins Dunkel zu bringen: den Befehl EXPLAIN.
In diesem Beitrag zeigen wir, wie Sie EXPLAIN- bzw. PROFILE-Pläne in den drei Abfragesprachen von Neptune (Gremlin, SPARQL und openCypher) nutzen, um Performance-Probleme zu diagnostizieren, die Query-Ausführung nachzuvollziehen und Ihre Graph-Workloads zu optimieren.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Warum EXPLAIN und PROFILE wichtig sind
Anders als bei relationalen Datenbanken durchlaufen Graph-Queries oft viele Kanten, beinhalten dynamische Filter und Pattern Matching. Das macht die Performance schwerer vorhersehbar, und klassische Indexierungsstrategien greifen nicht immer. Genau hier kommt der Query Planner ins Spiel: Er zeigt Ihnen, wie Neptune Ihre Abfrage interpretiert und an welchen Stellen unnötig Zeit verloren geht.
So erzeugen Sie EXPLAIN-Pläne
Sehen wir uns an, wie sich EXPLAIN-Pläne in den jeweils unterstützten Sprachen erzeugen lassen.
1\. Gremlin
In Gremlin erzeugen Sie einen PROFILE-Plan über den HTTP-Endpoint profile – im Neptune Workbench oder in jedem Gremlin-kompatiblen Prompt mit Neptune-Erweiterungen. PROFILE statt EXPLAIN führt die Abfrage in Echtzeit aus und liefert dadurch deutlich aussagekräftigere Statistiken:
POST https://<your-neptune-endpoint>:<port>/gremlin/profile \
-d '{
"gremlin":"g.V().hasLabel(\"city\")
.has(\"name\", \"London\")
.emit()
.repeat(in().simplePath())
.times(2)
.limit(100)"
}'
In einem Jupyter Notebook können Sie stattdessen den Magic-Cell-Befehl verwenden:
%%gremlin profile
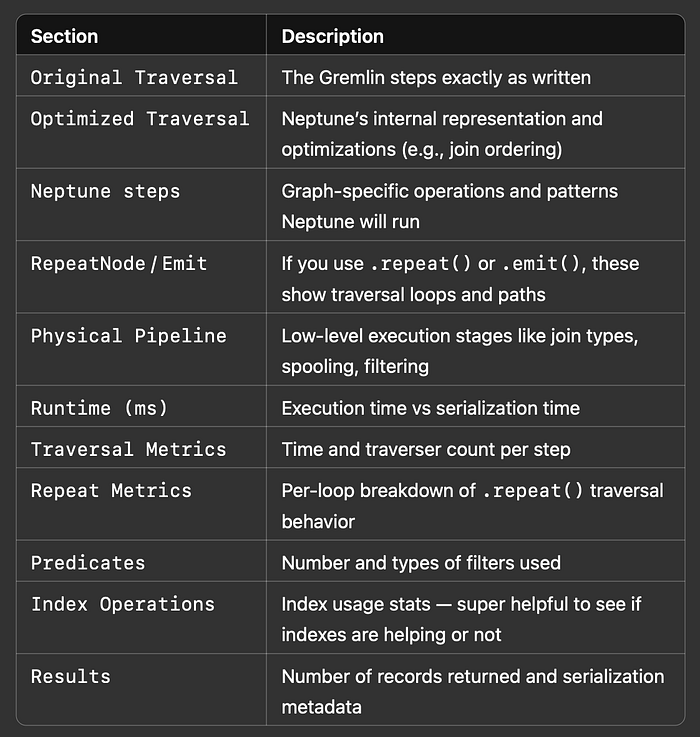
Damit wird die Abfrage ausgeführt und ein vollständiger Profile-Report zurückgegeben – einschließlich:
- Ausführungsschritten
- Laufzeiten und Counts
- optimierten und physischen Query-Plänen
- Traversal- und Repeat-Metriken
Beispielausgabe (zur besseren Übersicht gekürzt):
Query String
==================
g.V().hasLabel("city").has("name", "London").emit().repeat(in().simplePath()).times(2).limit(100)Original Traversal
==================
[GraphStep(vertex,[]), HasStep([...]), RepeatStep(...), RangeGlobalStep(0,100)]Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {...}\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {...}\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . SimplePathFilter(?1, ?3)) .], {...}\
}\
Emit { Filter(true) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(2)) }\
}\
}, finishers=[limit(100)]\
},\
NeptuneTraverserConverterStep\
]Physical Pipeline
=================
NeptuneGraphQueryStep
|-- JoinGroupOp
|-- DynamicJoinOp(...)
|-- RepeatOp
|-- BindingSetQueue (Iteration 1)...
|-- BindingSetQueue (Iteration 2)...
|-- LimitOp(100)Runtime (ms)
============
Query Execution: 392.686
Serialization: 2636.380Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
--------------------------------------------------------------
NeptuneGraphQueryStep(Vertex) 100 100 314.162 82.78
NeptuneTraverserConverterStep 100 100 65.333 17.22
TOTAL - - 379.495 -Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 1 1
1 61 61 0 61 61
2 38 38 38 0 0
------------------------------------------------------
100 100 38 62 62Results
=======
Count: 100
Response size (bytes): 23566
Im Folgenden fassen wir die einzelnen Abschnitte zusammen, damit klar wird, was die Ausgabe Ihnen zeigt:
2\. SPARQL
In SPARQL übergeben Sie zusammen mit Ihrer Abfrage den Parameter explain=details. Mit curl erhalten Sie so einen detaillierten EXPLAIN-Plan (in Jupyter funktionieren auch hier die Magic-Cell-Befehle):
curl https://<your-neptune-endpoint>:<port>/sparql \
-d "query=PREFIX ex: <https://example.com/> \
SELECT ?person WHERE { ?person a ex:City ; ex:name \"London\" }" \
-d "explain=details"
Beispielausgabe:
╔════╤════════╤════════╤═══════════════════╤═══════════════════════════════════════════════════════╤══════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪═══════════════════════════════════════════════════════╪══════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ PipelineJoin │ pattern=distinct(?person, rdf:type, ex:City) │ - │ 1 │ 2 │ 2.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ 3 │ - │ PipelineJoin │ pattern=distinct(?person, ex:name, \"London\") │ - │ 2 │ 2 │ 1.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 3 │ 4 │ - │ Projection │ vars=[?person] │ retain │ 2 │ 2 │ 1.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 4 │ - │ - │ TermResolution │ vars=[?person] │ id2value │ 2 │ 2 │ 1.00 │ 1 ║
╚════╧════════╧════════╧═══════════════════╧═══════════════════════════════════════════════════════╧══════════╧══════════╧═══════════╧═══════╧═══════════╝
explain=details liefert die umfassendste Sicht darauf, wie SPARQL-Queries intern in Neptune geplant und ausgeführt werden.
Im Folgenden fassen wir die einzelnen Abschnitte zusammen, damit klar wird, was die Ausgabe Ihnen zeigt:

3\. openCypher
Um in openCypher einen EXPLAIN-Plan zu erzeugen, übergeben Sie den Parameter explain=details (in Jupyter funktionieren auch hier die Magic-Cell-Befehle):
curl https://<your-neptune-endpoint>:<port>/openCypher \
-d "query=MATCH (c:City {name: 'London'}) RETURN c" \
-d "explain=details"
Beispielausgabe:
Query:
MATCH (c:City {name: 'London'}) RETURN c
╔════╤════════╤════════╤═══════════════════╤════════════════════╤═════════════════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪════════════════════╪═════════════════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFESubquery │ subQuery=subQuery1 │ - │ 0 │ 10 │ 0.00 │ 5.00 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ TermResolution │ vars=[?c] │ id2value_opencypher │ 10 │ 10 │ 1.00 │ 1.00 ║
╚════╧════════╧════════╧═══════════════════╧════════════════════╧═════════════════════╧══════════╧═══════════╧═══════╧═══════════╝subQuery1:
╔════╤════════╤════════╤═════════════════╤═══════════════════════════════════════════════════════════╤══════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═════════════════╪═══════════════════════════════════════════════════════════╪══════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ DFEPipelineScan │ pattern=Node((?anon_node)-[:?rel]->()) │ - │ 0 │ 1000 │ 0.00 │ 0.66 ║
║ │ │ │ │ inlineFilters=[(?label = :City), (?name = 'London')] │ │ │ │ │ ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFEProject │ columns=[?c] │ - │ 1000 │ 1000 │ 1.00 │ 0.14 ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ DFEDrain │ limit=10 │ - │ 1000 │ 0 │ 0.00 │ 0.11 ║
╚════╧════════╧════════╧═════════════════╧═══════════════════════════════════════════════════════════╧══════╧══════════╧═══════════╧═══════╧═══════════╝
explain=details zeigt für openCypher Ausführungsphasen, Join-Logik, Limits und Pattern-Schätzungen in Tabellenform – für die Performance-Analyse weitaus nützlicher als die Standardausgabe.
Im Folgenden fassen wir die einzelnen Abschnitte zusammen, damit klar wird, was die Ausgabe Ihnen zeigt:

Die Ausgabe richtig interpretieren
Die PROFILE-Ausgabe von Gremlin schlüsselt Ausführungsphasen und ihre Kosten gleichermaßen auf. Besonders wertvoll sind die Repeat-Metriken: Sie helfen dabei, Traversal-Schleifen zu verstehen – einer der häufigsten Performance-Stolpersteine in Graph-Queries. So erkennen Sie kostenintensive Traversal-Abschnitte und sehen, wie sich Filter- und Pfadlogik auf die Ausführung auswirken.
Bei SPARQL und openCypher verwandelt der details-Modus statische Pläne in eine detaillierte Schritt-für-Schritt-Analyse – inklusive Join-Typen, Projektionsreihenfolge, Filtern, Zeitkosten pro Operator sowie geschätzten und tatsächlichen Datenmengen.
Fallstudie: Gremlin-Optimierung in der Praxis
Sehen wir uns eine einfache Gremlin-Beispielabfrage an. Sie startet beim Knoten, der die Stadt London repräsentiert. Von dort wird über alle eingehenden Verbindungen bis zu drei Schritte rückwärts traversiert, ohne dass ein Knoten zweimal besucht wird. Anschließend geht es vom jeweiligen Endpunkt einen Schritt vorwärts, um verbundene Knoten zu finden. Davon werden ausschließlich Events ausgewählt (also Knoten mit der Eigenschaft type = "event"). Zurückgegeben werden bis zu 50 passende Ergebnisse. So sieht die Abfrage in Gremlin aus:
g.V()
.has("name", "London")
.hasLabel("city")
.repeat(in().simplePath())
.times(3)
.out()
.has("type", "event")
.limit(50)
Explain-Plan:
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().has("name", "London").hasLabel("city").repeat(in().simplePath()).times(3).out().has("type", "event").limit(50)
Original Traversal
==================
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75, joinTime=4, hashJoin=true, actualTotalOutput=2} [1]\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33, hashJoin=true, joinTime=0, actualTotalOutput=2} [1]\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . SimplePathFilter(?1, ?3)) .], {estimatedCardinality=70000, hashJoin=true, indexTime=0, joinTime=5} [2]\
}\
Emit {\
Filter(false)\
}\
LoopsCondition {\
LoopsFilter([?1, ?3],eq(3))\
}\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
}, finishers=[filter(type=event), limit(50)], annotations={path=[Vertex(?1):GraphStep, Repeat[Vertex(?3):VertexStep], Vertex(?4):VertexStep], joinStats=true, optimizationTime=519, maxVarId=9, executionTime=483} [3]\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75}) [1]
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33}) [1]
|-- RepeatOp
|-- <upstream input> (Iteration 0) [visited=2, output=2 (until=0, emit=0), next=2]
|-- BindingSetQueue (Iteration 1) [visited=250, output=250 (until=0, emit=0), next=250]
|-- DynamicJoinOp(PatternNode[(?3, ?5, ?1, ?6) . ...]) [2]
|-- BindingSetQueue (Iteration 2) [visited=950, output=950 (until=0, emit=0), next=950]
|-- BindingSetQueue (Iteration 3) [visited=19500, output=19500 (until=19500, emit=0), next=0]
|-- VertexStep(OUT)
|-- FilterStep(type = event) [3]
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 483.222
Serialization: 2798.304
Traversal Metrics
=================
Step Count Traversers Time (ms)
------------------------------------------------------------
NeptuneGraphQueryStep 50 50 403.187
NeptuneTraverserConverterStep 50 50 80.035
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 2 2 0 0 2
1 250 250 0 0 250
2 950 950 0 0 950
3 19500 19500 19500 0 0
------------------------------------------------------
20702 20702 19500 0 1202
Warnings:
⚠ reverse traversal with no edge label(s) [2]
⚠ high fan-out detected in repeat [2]
⚠ filter applied late in traversal chain [3]
Was der EXPLAIN-Plan zeigt
[x] markiert die jeweilige Stelle im obigen Explain-Plan:
- [1] Ineffizienter Einstieg: Trotz niedriger Kardinalität ließen sich beide Filter so umsortieren, dass früher stärker gefiltert wird. Je höher die Kardinalität, desto größer der Wertebereich im Datensatz – und desto kleiner das Ergebnis, weil weniger Werte matchen. Ziel ist es, möglichst früh den kleinstmöglichen Datensatz zurückzubekommen. Beispiel: Sie haben zwei Filter auf jeweils potenziell 10.000 Knoten. Der eine selektiert 50 % dieser Knoten, der andere 10 %. Idealerweise läuft der 10-%-Filter zuerst, sodass nur 1.000 Knoten an den nächsten Filter weitergereicht werden. Andersherum würden Sie fünfmal so viele Knoten weitergeben – mehr Datenverarbeitung, langsamere Queries.
- [2]
.in()hat kein Edge-Label, weshalb alle eingehenden Kanten gescannt werden. Die Repeat-Traversierung explodiert von 2 auf fast 20.000 Knoten. - [3] Die Filter
.out()und.has("type", "event")greifen erst nach dieser massiven Expansion – sehr ineffizient. - Gesamtzahl der Traversierungen: 20K+; eine Menge verschwendeter Aufwand.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Optimierte Version
g.V()
.hasLabel("city")
.has("name", "London")
.repeat(in("located_in").simplePath())
.times(3)
.out("hosts")
.has("type", "event")
.limit(50)
Was wurde verbessert
- Edge-Label-Filter sowohl bei
.in()als auch bei.out()ergänzt .has("type", "event")nach vorne gezogen, um nachgelagerte Kosten zu reduzieren.simplePath()zum Schutz vor Zyklen beibehalten, zu Testzwecken aber optional gehalten
PROFILE-Ausgabe nach der Optimierung
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().hasLabel("city").has("name", "London")
.repeat(in("located_in").simplePath()).times(3)
.out("hosts").has("type", "event").limit(50)
Original Traversal
==================
[GraphStep(vertex,[]),\
HasStep([~label.eq(city)]),\
HasStep([name.eq(London)]),\
RepeatStep(emit(false), [VertexStep(IN,[located_in]), PathFilterStep(simple), RepeatEndStep], until(loops(3))),\
VertexStep(OUT,[hosts]),\
HasStep([type.eq(event)]),\
RangeGlobalStep(0,50)]
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=3000, indexTime=21, actualTotalOutput=7}\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=1, indexTime=62, actualTotalOutput=1}\
RepeatNode {\
Repeat {\
PatternNode[(?3, <located_in>, ?1, ?) . project ?1,?3 . SimplePathFilter(?1,?3)] {estimatedCardinality=4500, hashJoin=true}\
}\
Emit { Filter(false) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(3)) }\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
},\
JoinGroupNode {\
PatternNode[(?3, <hosts>, ?4, ?) . project ?4 .], {estimatedCardinality=500, hashJoin=true}\
PatternNode[(?4, <type>, "event", ?) . project ?4 .], {estimatedCardinality=150, hashJoin=true}\
},\
finishers=[limit(50)],\
annotations={executionTime=192, optimizationTime=87, path=[Vertex(?1)->Repeat(?3)->Vertex(?4)]}\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) ...])
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) ...])
|-- RepeatOp
|-- Iteration 0: visited=1, output=1, next=1
|-- Iteration 1: visited=35, output=35, next=35
|-- Iteration 2: visited=85, output=85, next=85
|-- Iteration 3: visited=120, output=120, next=0
|-- DynamicJoinOp(PatternNode[(?3, <hosts>, ?4, ?) ...])
|-- DynamicJoinOp(PatternNode[(?4, <type>, "event", ?) ...])
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 172.329
Serialization: 817.502
Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
---------------------------------------------------------------------
NeptuneGraphQueryStep 50 50 139.438 80.9
NeptuneTraverserConverterStep 50 50 32.891 19.1
TOTAL 172.329
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 0 1
1 35 35 0 0 35
2 85 85 0 0 85
3 120 120 0 0 0
------------------------------------------------------
241 241 0 0 121
Predicates
==========
# of predicates: 10
Results
=======
Count: 50
Output: [v[302], v[417], v[501], v[519], v[520], v[622], v[635], v[780], v[801], ...]
Response serializer: GRYO_V3D0
Response size (bytes): 18310
Index Operations
================
Query execution:
# of statement index ops: 4
# of unique statement index ops: 4
Duplication ratio: 1.00
# of terms materialized: 0
Serialization:
# of statement index ops: 100
# of unique statement index ops: 88
Duplication ratio: 1.14
# of terms materialized: 145
Ergebnis:
- Insgesamt traversierte Knoten: ~886 statt ~20.702
- Query-Laufzeit um über 60 % reduziert
- Geringere Speicherlast und kleineres Timeout-Risiko
TL;DR – Worauf Sie in EXPLAIN/PROFILE achten sollten
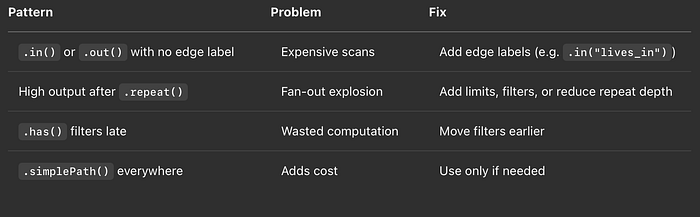
Tabelle mit den wichtigsten Bereichen, die Sie im Explain-Plan finden
Tipps & Tricks
- Filter so weit wie möglich nach vorne ziehen: Wenden Sie Filter so früh wie möglich in Ihrer Abfrage an.
- Die richtige Richtung wählen: Drehen Sie die Traversierung um, wenn Sie so zu selektiveren Startpunkten kommen.
- Vorsicht mit OPTIONAL (SPARQL): Solche Konstrukte können die Plan-Komplexität drastisch erhöhen.
- Label-Kardinalität berücksichtigen: Labels mit hoher Kardinalität eignen sich besser als Query-Einstiegspunkte.
- Modell-Design nicht vergessen: Performance-Probleme sind oft nur das Symptom einer schlecht modellierten Graph-Struktur.
Query-Pläne visualisieren
Bei umfangreichen Plänen lohnt sich ein Python-Skript, das die JSON-Ausgabe parst und mit Graphviz oder D3.js als Baum darstellt. Eine ausgezeichnete Möglichkeit, die Struktur leichter zu erfassen und im Team zu teilen.
Der EXPLAIN-Befehl von Neptune gehört zu den am stärksten unterschätzten Werkzeugen im Toolkit von Graph-Entwicklern. Wer einmal damit gearbeitet hat, fragt sich, wie er je darauf verzichten konnte. Wenn Sie verstehen, wie der Query Planner denkt, lassen sich Ihre Abfragen – und Ihr Graph selbst – gezielt auf bessere und schnellere Ergebnisse hin gestalten.
Jetzt heißt es: ran an die Query-Pläne und debuggen wie ein Profi. 🕵️♀️
PS: Wenn Sie Lust auf einen Folgebeitrag haben – etwa zur Visualisierung von EXPLAIN-Plänen oder zum Benchmarking von Query-Performance – sagen Sie Bescheid. Für ein bisschen Graph-Nerderei bin ich immer zu haben.
Bei DoiT International arbeiten ausschließlich Senior Engineers. Wir sind spezialisiert auf anspruchsvolle Cloud-Beratung, Architektur-Design und Debugging-Services. Ob Sie Ihre ersten Schritte mit Graphdatenbanken planen, ein bestehendes System optimieren oder komplexe Probleme lösen wollen – wir liefern Ihnen passgenaue Expertenberatung.