Cloud Intelligence™
Por dentro do Query Planner: analisando planos EXPLAIN no Amazon Neptune
Esta página também está disponível em English, Deutsch, Español, Français, Italiano e 日本語.









About Kate Gawron
Cloud database architect with 12+ years across operational and analytical platforms. AWS Ambassador. Speaker, webinar host, blogger, course creator.
Specialising in database modernisation, Aurora, RDS, Snowflake, and getting teams from raw data to production AI across EMEA.
Off the clock: strength training, cricket, and going sideways on a kart track.
My personal pageAjustar a performance no Amazon Neptune muitas vezes parece andar numa caverna escura sem lanterna. As consultas podem ficar lentas do nada, ou aquela travessia em Gremlin que rodava bem em um conjunto pequeno de dados de repente leva uma eternidade num grafo de produção. Felizmente, o Neptune oferece uma ferramenta para acender a luz: o comando EXPLAIN.
Neste post, vamos ver como usar planos EXPLAIN ou PROFILE nas três linguagens de consulta do Neptune (Gremlin, SPARQL e openCypher) para diagnosticar problemas de performance, entender como as consultas são executadas e otimizar seus workloads de grafo.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Por que EXPLAIN e PROFILE importam
Diferente dos bancos relacionais, as consultas em grafo costumam envolver travessias por muitas arestas, filtragem dinâmica e correspondência de padrões. Isso torna a performance mais difícil de prever, e as estratégias tradicionais de indexação nem sempre se aplicam. É aí que entra o query planner: ele mostra como o Neptune está interpretando sua consulta e onde pode estar perdendo tempo.
Como gerar planos EXPLAIN
Vamos ver como gerar planos EXPLAIN em cada linguagem suportada.
1\. Gremlin
No Gremlin, você gera um plano PROFILE pelo endpoint HTTP profile no Neptune Workbench ou em qualquer prompt compatível com Gremlin que aceite as extensões do Neptune. Usar PROFILE em vez de EXPLAIN executa a consulta em tempo real e devolve estatísticas mais ricas:
POST https://<your-neptune-endpoint>:<port>/gremlin/profile \
-d '{
"gremlin":"g.V().hasLabel(\"city\")
.has(\"name\", \"London\")
.emit()
.repeat(in().simplePath())
.times(2)
.limit(100)"
}'
Se você estiver rodando esse código em um Jupyter Notebook, dá para usar o magic cell command:
%%gremlin profile
Isso executa a consulta e devolve um relatório completo de profile, incluindo:
- Etapas de execução
- Durações e contagens
- Planos de consulta otimizados e físicos
- Métricas de travessia e repetição
Saída de exemplo (truncada para facilitar a leitura):
Query String
==================
g.V().hasLabel("city").has("name", "London").emit().repeat(in().simplePath()).times(2).limit(100)Original Traversal
==================
[GraphStep(vertex,[]), HasStep([...]), RepeatStep(...), RangeGlobalStep(0,100)]Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {...}\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {...}\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . SimplePathFilter(?1, ?3)) .], {...}\
}\
Emit { Filter(true) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(2)) }\
}\
}, finishers=[limit(100)]\
},\
NeptuneTraverserConverterStep\
]Physical Pipeline
=================
NeptuneGraphQueryStep
|-- JoinGroupOp
|-- DynamicJoinOp(...)
|-- RepeatOp
|-- BindingSetQueue (Iteration 1)...
|-- BindingSetQueue (Iteration 2)...
|-- LimitOp(100)Runtime (ms)
============
Query Execution: 392.686
Serialization: 2636.380Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
--------------------------------------------------------------
NeptuneGraphQueryStep(Vertex) 100 100 314.162 82.78
NeptuneTraverserConverterStep 100 100 65.333 17.22
TOTAL - - 379.495 -Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 1 1
1 61 61 0 61 61
2 38 38 38 0 0
------------------------------------------------------
100 100 38 62 62Results
=======
Count: 100
Response size (bytes): 23566
Vamos resumir cada seção para você entender o que cada uma está mostrando:
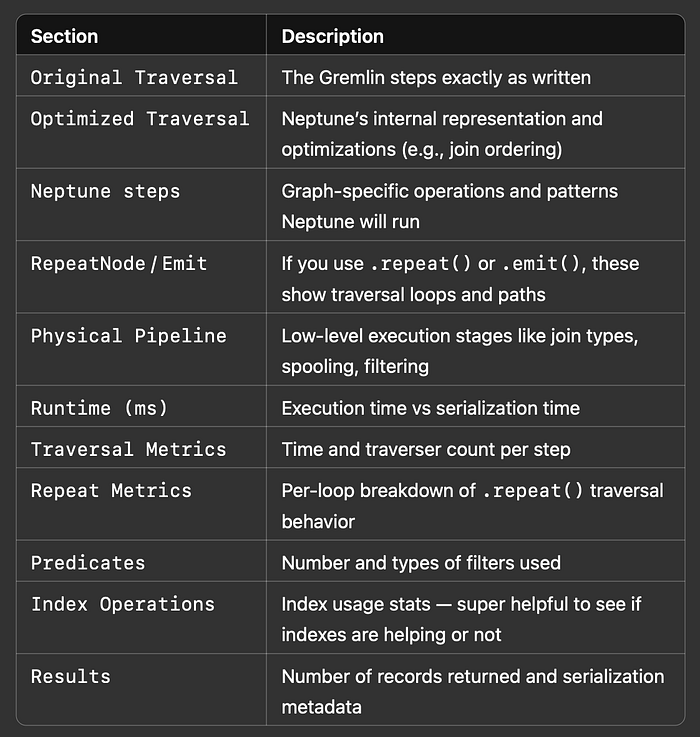
2\. SPARQL
No SPARQL, você usa o parâmetro explain=details junto com a consulta. Veja como obter um plano EXPLAIN detalhado com curl (também dá para usar os magic cell commands no Jupyter):
curl https://<your-neptune-endpoint>:<port>/sparql \
-d "query=PREFIX ex: <https://example.com/> \
SELECT ?person WHERE { ?person a ex:City ; ex:name \"London\" }" \
-d "explain=details"
Saída de exemplo:
╔════╤════════╤════════╤═══════════════════╤═══════════════════════════════════════════════════════╤══════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪═══════════════════════════════════════════════════════╪══════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ PipelineJoin │ pattern=distinct(?person, rdf:type, ex:City) │ - │ 1 │ 2 │ 2.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ 3 │ - │ PipelineJoin │ pattern=distinct(?person, ex:name, \"London\") │ - │ 2 │ 2 │ 1.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 3 │ 4 │ - │ Projection │ vars=[?person] │ retain │ 2 │ 2 │ 1.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 4 │ - │ - │ TermResolution │ vars=[?person] │ id2value │ 2 │ 2 │ 1.00 │ 1 ║
╚════╧════════╧════════╧═══════════════════╧═══════════════════════════════════════════════════════╧══════════╧══════════╧═══════════╧═══════╧═══════════╝
O explain=details oferece a visão mais completa de como as consultas SPARQL são planejadas e executadas internamente no Neptune.
Vamos resumir cada seção para você entender o que cada uma está mostrando:

3\. openCypher
Para gerar um plano EXPLAIN no openCypher, use o parâmetro explain=details (também dá para usar os magic cell commands no Jupyter):
curl https://<your-neptune-endpoint>:<port>/openCypher \
-d "query=MATCH (c:City {name: 'London'}) RETURN c" \
-d "explain=details"
Saída de exemplo:
Query:
MATCH (c:City {name: 'London'}) RETURN c
╔════╤════════╤════════╤═══════════════════╤════════════════════╤═════════════════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪════════════════════╪═════════════════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFESubquery │ subQuery=subQuery1 │ - │ 0 │ 10 │ 0.00 │ 5.00 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ TermResolution │ vars=[?c] │ id2value_opencypher │ 10 │ 10 │ 1.00 │ 1.00 ║
╚════╧════════╧════════╧═══════════════════╧════════════════════╧═════════════════════╧══════════╧═══════════╧═══════╧═══════════╝subQuery1:
╔════╤════════╤════════╤═════════════════╤═══════════════════════════════════════════════════════════╤══════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═════════════════╪═══════════════════════════════════════════════════════════╪══════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ DFEPipelineScan │ pattern=Node((?anon_node)-[:?rel]->()) │ - │ 0 │ 1000 │ 0.00 │ 0.66 ║
║ │ │ │ │ inlineFilters=[(?label = :City), (?name = 'London')] │ │ │ │ │ ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFEProject │ columns=[?c] │ - │ 1000 │ 1000 │ 1.00 │ 0.14 ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ DFEDrain │ limit=10 │ - │ 1000 │ 0 │ 0.00 │ 0.11 ║
╚════╧════════╧════════╧═════════════════╧═══════════════════════════════════════════════════════════╧══════╧══════════╧═══════════╧═══════╧═══════════╝
No openCypher, o explain=details mostra os estágios de execução, a lógica dos joins, os limites e as estimativas de padrão em formato tabular — bem mais útil para análise de performance do que a saída padrão.
Vamos resumir cada seção para você entender o que cada uma está mostrando:

Interpretando a saída
A saída do PROFILE no Gremlin detalha tanto os estágios de execução quanto o custo de cada um. As Repeat Metrics são especialmente úteis para entender loops de travessia, que costumam ser armadilhas clássicas de performance em consultas a grafos. Você consegue identificar trechos de travessia caros e ver como a lógica de filtros ou de caminhos está afetando a execução.
Para SPARQL e openCypher, o modo details transforma planos estáticos em uma análise detalhada passo a passo, com informações como tipos de join, ordem de projeção, filtros, custo de tempo por operador e volumes de dados estimados versus reais.
Estudo de caso: otimização de Gremlin na prática
Vamos analisar uma consulta simples em Gremlin. Ela começa no nó que representa a cidade de Londres. A partir dali, percorre para trás todas as conexões de entrada por até três passos, sem revisitar nenhum nó. Em seguida, avança um passo a partir de onde chegou para encontrar nós conectados. Pega só os eventos desses nós (ou seja, aqueles com a propriedade type definida como "event"). Por fim, retorna até 50 resultados correspondentes. A consulta em Gremlin fica assim:
g.V()
.has("name", "London")
.hasLabel("city")
.repeat(in().simplePath())
.times(3)
.out()
.has("type", "event")
.limit(50)
Plano de execução:
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().has("name", "London").hasLabel("city").repeat(in().simplePath()).times(3).out().has("type", "event").limit(50)
Original Traversal
==================
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75, joinTime=4, hashJoin=true, actualTotalOutput=2} [1]\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33, hashJoin=true, joinTime=0, actualTotalOutput=2} [1]\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . SimplePathFilter(?1, ?3)) .], {estimatedCardinality=70000, hashJoin=true, indexTime=0, joinTime=5} [2]\
}\
Emit {\
Filter(false)\
}\
LoopsCondition {\
LoopsFilter([?1, ?3],eq(3))\
}\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
}, finishers=[filter(type=event), limit(50)], annotations={path=[Vertex(?1):GraphStep, Repeat[Vertex(?3):VertexStep], Vertex(?4):VertexStep], joinStats=true, optimizationTime=519, maxVarId=9, executionTime=483} [3]\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75}) [1]
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33}) [1]
|-- RepeatOp
|-- <upstream input> (Iteration 0) [visited=2, output=2 (until=0, emit=0), next=2]
|-- BindingSetQueue (Iteration 1) [visited=250, output=250 (until=0, emit=0), next=250]
|-- DynamicJoinOp(PatternNode[(?3, ?5, ?1, ?6) . ...]) [2]
|-- BindingSetQueue (Iteration 2) [visited=950, output=950 (until=0, emit=0), next=950]
|-- BindingSetQueue (Iteration 3) [visited=19500, output=19500 (until=19500, emit=0), next=0]
|-- VertexStep(OUT)
|-- FilterStep(type = event) [3]
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 483.222
Serialization: 2798.304
Traversal Metrics
=================
Step Count Traversers Time (ms)
------------------------------------------------------------
NeptuneGraphQueryStep 50 50 403.187
NeptuneTraverserConverterStep 50 50 80.035
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 2 2 0 0 2
1 250 250 0 0 250
2 950 950 0 0 950
3 19500 19500 19500 0 0
------------------------------------------------------
20702 20702 19500 0 1202
Warnings:
⚠ reverse traversal with no edge label(s) [2]
⚠ high fan-out detected in repeat [2]
⚠ filter applied late in traversal chain [3]
O que o plano EXPLAIN mostra
[x] indica onde cada informação aparece no plano acima:
- [1] Início ineficiente: mesmo com cardinalidade baixa, os dois filtros poderiam ser reordenados para uma poda melhor. Quanto maior a cardinalidade, maior a variedade de valores possíveis no conjunto de dados, o que tende a resultar em um conjunto retornado menor, já que menos valores correspondem ao filtro. A ideia é que o menor conjunto de dados seja retornado primeiro. Por exemplo: imagine dois filtros sobre 10.000 nós em potencial cada. Um filtro seleciona 50% desses nós, e o outro seleciona 10%. Você quer que o filtro de 10% seja processado primeiro, para que apenas 1.000 nós passem para o filtro seguinte. Se a ordem for invertida, você passa cinco vezes mais nós para a próxima condição, ou seja, mais dados processados e consultas mais lentas.
- [2] O
.in()não tem edge label, o que leva a varrer todas as arestas de entrada. A travessia repeat explode em tamanho (de 2 para quase 20 mil nós). - [3] Os filtros
.out()e.has("type", "event")são aplicados depois dessa expansão enorme, o que é ineficiente. - Total de travessias: mais de 20 mil; muito esforço desperdiçado.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Versão otimizada
g.V()
.hasLabel("city")
.has("name", "London")
.repeat(in("located_in").simplePath())
.times(3)
.out("hosts")
.has("type", "event")
.limit(50)
Melhorias aplicadas
- Adição de filtros de edge label tanto em
.in()quanto em.out() .has("type", "event")foi antecipado para reduzir o custo nas etapas seguintes.simplePath()mantido para proteção contra ciclos, mas marcado como opcional para testes
Saída do PROFILE após a otimização
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().hasLabel("city").has("name", "London")
.repeat(in("located_in").simplePath()).times(3)
.out("hosts").has("type", "event").limit(50)
Original Traversal
==================
[GraphStep(vertex,[]),\
HasStep([~label.eq(city)]),\
HasStep([name.eq(London)]),\
RepeatStep(emit(false), [VertexStep(IN,[located_in]), PathFilterStep(simple), RepeatEndStep], until(loops(3))),\
VertexStep(OUT,[hosts]),\
HasStep([type.eq(event)]),\
RangeGlobalStep(0,50)]
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=3000, indexTime=21, actualTotalOutput=7}\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=1, indexTime=62, actualTotalOutput=1}\
RepeatNode {\
Repeat {\
PatternNode[(?3, <located_in>, ?1, ?) . project ?1,?3 . SimplePathFilter(?1,?3)] {estimatedCardinality=4500, hashJoin=true}\
}\
Emit { Filter(false) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(3)) }\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
},\
JoinGroupNode {\
PatternNode[(?3, <hosts>, ?4, ?) . project ?4 .], {estimatedCardinality=500, hashJoin=true}\
PatternNode[(?4, <type>, "event", ?) . project ?4 .], {estimatedCardinality=150, hashJoin=true}\
},\
finishers=[limit(50)],\
annotations={executionTime=192, optimizationTime=87, path=[Vertex(?1)->Repeat(?3)->Vertex(?4)]}\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) ...])
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) ...])
|-- RepeatOp
|-- Iteration 0: visited=1, output=1, next=1
|-- Iteration 1: visited=35, output=35, next=35
|-- Iteration 2: visited=85, output=85, next=85
|-- Iteration 3: visited=120, output=120, next=0
|-- DynamicJoinOp(PatternNode[(?3, <hosts>, ?4, ?) ...])
|-- DynamicJoinOp(PatternNode[(?4, <type>, "event", ?) ...])
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 172.329
Serialization: 817.502
Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
---------------------------------------------------------------------
NeptuneGraphQueryStep 50 50 139.438 80.9
NeptuneTraverserConverterStep 50 50 32.891 19.1
TOTAL 172.329
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 0 1
1 35 35 0 0 35
2 85 85 0 0 85
3 120 120 0 0 0
------------------------------------------------------
241 241 0 0 121
Predicates
==========
# of predicates: 10
Results
=======
Count: 50
Output: [v[302], v[417], v[501], v[519], v[520], v[622], v[635], v[780], v[801], ...]
Response serializer: GRYO_V3D0
Response size (bytes): 18310
Index Operations
================
Query execution:
# of statement index ops: 4
# of unique statement index ops: 4
Duplication ratio: 1.00
# of terms materialized: 0
Serialization:
# of statement index ops: 100
# of unique statement index ops: 88
Duplication ratio: 1.14
# of terms materialized: 145
Resultado:
- Total de nós percorridos: ~886 vs. ~20.702
- Tempo de consulta reduzido em mais de 60%
- Menos pressão sobre a memória e menor risco de timeout
TL;DR — O que olhar no EXPLAIN/PROFILE
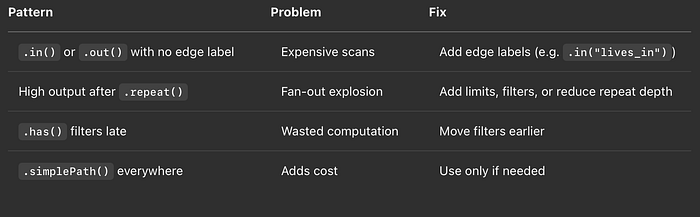
Tabela com as principais áreas encontradas no plano de execução
Dicas e truques
- Antecipe os filtros: aplique-os o mais cedo possível na consulta.
- Use a direção certa: inverta a travessia se isso levar a pontos de partida mais seletivos.
- Cuidado com OPTIONAL (SPARQL): ele pode aumentar muito a complexidade do plano.
- Considere a cardinalidade dos labels: labels de alta cardinalidade funcionam melhor como raízes da consulta.
- Não esqueça do design do modelo: às vezes, problemas de performance são sintomas de uma estrutura de grafo mal pensada.
Visualizando planos de consulta
Para planos grandes, vale a pena escrever um script em Python que faça o parsing da saída JSON e a renderize como árvore com Graphviz ou D3.js. É uma ótima forma de tornar a estrutura mais fácil de absorver e compartilhar com o time.
O comando EXPLAIN do Neptune é uma das ferramentas mais subutilizadas no kit de quem desenvolve com grafos. Depois que você começa a usá-lo, fica difícil imaginar como trabalhava sem ele. Entender como o query planner raciocina permite moldar suas consultas — e o próprio grafo — para resultados melhores e mais rápidos.
Agora vá em frente e debugue esses planos de consulta como um profissional. 🕵️♀️
PS: se você quiser um deep dive de continuação sobre como visualizar planos EXPLAIN ou fazer benchmarks de performance de consultas, me avise — estou sempre a fim de uma boa nerdice em grafos.
Na DoiT International, nosso time é formado exclusivamente por talentos sêniores de engenharia. Somos especialistas em consultoria avançada em nuvem, design de arquitetura e serviços de debugging. Seja para dar os primeiros passos com bancos de dados em grafo, otimizar um sistema existente ou resolver problemas complexos, oferecemos orientação sob medida e especializada para cada necessidade.