Cloud Intelligence™
Dentro il query planner: analizzare gli EXPLAIN plan in Amazon Neptune
Questa pagina è disponibile anche in English, Deutsch, Español, Français, 日本語 e Português.









About Kate Gawron
Cloud database architect with 12+ years across operational and analytical platforms. AWS Ambassador. Speaker, webinar host, blogger, course creator.
Specialising in database modernisation, Aurora, RDS, Snowflake, and getting teams from raw data to production AI across EMEA.
Off the clock: strength training, cricket, and going sideways on a kart track.
My personal pageQuando si lavora con Amazon Neptune, il tuning delle prestazioni può sembrare un percorso al buio in una grotta senza torcia. Le query rallentano senza preavviso, oppure quel traversal Gremlin che girava liscio su un piccolo dataset diventa improvvisamente interminabile su un grafo di produzione. Per fortuna, Neptune ci mette in mano un interruttore per accendere la luce: il comando EXPLAIN.
In questo articolo vediamo come usare i piani EXPLAIN o PROFILE nei tre linguaggi di query supportati da Neptune (Gremlin, SPARQL e openCypher) per diagnosticare i problemi di performance, capire come vengono eseguite le query e ottimizzare i workloads sui grafi.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Perché EXPLAIN e PROFILE contano
A differenza dei database relazionali, le query sui grafi spesso prevedono traversal su molti archi, filtri dinamici e pattern matching. Questo rende le prestazioni più difficili da prevedere e le tradizionali strategie di indicizzazione non sempre sono applicabili. È qui che entra in gioco il query planner: vi mostra come Neptune sta interpretando la query e dove rischia di sprecare tempo.
Come generare gli EXPLAIN plan
Vediamo come generare gli EXPLAIN plan in ciascuno dei linguaggi supportati.
1\. Gremlin
In Gremlin si genera un piano PROFILE tramite l'endpoint HTTP profile nel Neptune Workbench o in qualsiasi prompt compatibile con Gremlin che supporti le estensioni di Neptune. Usare PROFILE invece di EXPLAIN esegue la query in tempo reale, restituendo statistiche molto più utili:
POST https://<your-neptune-endpoint>:<port>/gremlin/profile \
-d '{
"gremlin":"g.V().hasLabel(\"city\")
.has(\"name\", \"London\")
.emit()
.repeat(in().simplePath())
.times(2)
.limit(100)"
}'
Se eseguite il codice in un Jupyter Notebook, potete usare il comando magic cell:
%%gremlin profile
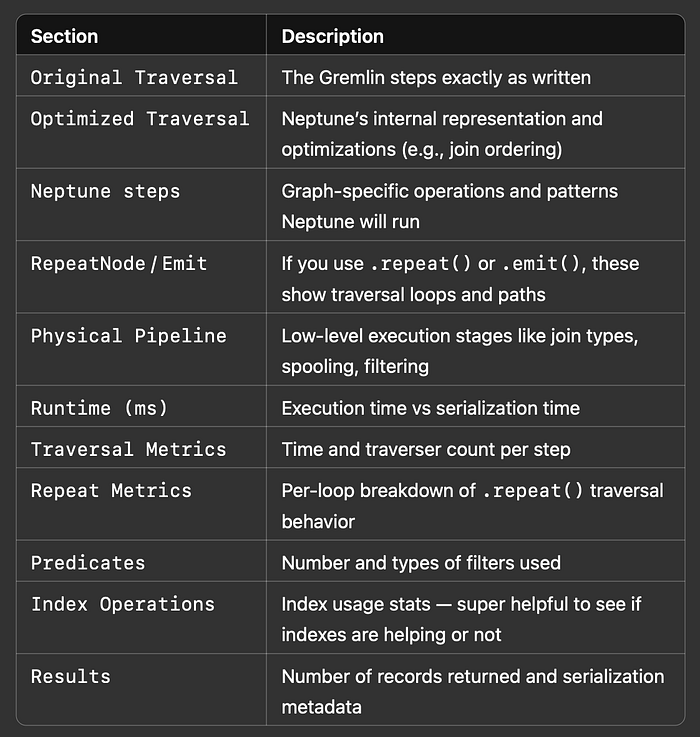
La query viene eseguita e restituisce un report di profile completo che include:
- Fasi di esecuzione
- Durate e conteggi
- Piani di query ottimizzati e fisici
- Metriche di traversal e di repeat
Esempio di output (troncato per chiarezza):
Query String
==================
g.V().hasLabel("city").has("name", "London").emit().repeat(in().simplePath()).times(2).limit(100)Original Traversal
==================
[GraphStep(vertex,[]), HasStep([...]), RepeatStep(...), RangeGlobalStep(0,100)]Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {...}\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {...}\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . SimplePathFilter(?1, ?3)) .], {...}\
}\
Emit { Filter(true) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(2)) }\
}\
}, finishers=[limit(100)]\
},\
NeptuneTraverserConverterStep\
]Physical Pipeline
=================
NeptuneGraphQueryStep
|-- JoinGroupOp
|-- DynamicJoinOp(...)
|-- RepeatOp
|-- BindingSetQueue (Iteration 1)...
|-- BindingSetQueue (Iteration 2)...
|-- LimitOp(100)Runtime (ms)
============
Query Execution: 392.686
Serialization: 2636.380Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
--------------------------------------------------------------
NeptuneGraphQueryStep(Vertex) 100 100 314.162 82.78
NeptuneTraverserConverterStep 100 100 65.333 17.22
TOTAL - - 379.495 -Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 1 1
1 61 61 0 61 61
2 38 38 38 0 0
------------------------------------------------------
100 100 38 62 62Results
=======
Count: 100
Response size (bytes): 23566
Riepiloghiamo ogni sezione per capire cosa vi sta dicendo:
2\. SPARQL
In SPARQL si usa il parametro explain=details insieme alla query. Ecco come ottenere un EXPLAIN plan dettagliato con curl (in Jupyter potete anche ricorrere ai comandi magic cell):
curl https://<your-neptune-endpoint>:<port>/sparql \
-d "query=PREFIX ex: <https://example.com/> \
SELECT ?person WHERE { ?person a ex:City ; ex:name \"London\" }" \
-d "explain=details"
Esempio di output:
╔════╤════════╤════════╤═══════════════════╤═══════════════════════════════════════════════════════╤══════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪═══════════════════════════════════════════════════════╪══════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ PipelineJoin │ pattern=distinct(?person, rdf:type, ex:City) │ - │ 1 │ 2 │ 2.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ 3 │ - │ PipelineJoin │ pattern=distinct(?person, ex:name, \"London\") │ - │ 2 │ 2 │ 1.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 3 │ 4 │ - │ Projection │ vars=[?person] │ retain │ 2 │ 2 │ 1.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 4 │ - │ - │ TermResolution │ vars=[?person] │ id2value │ 2 │ 2 │ 1.00 │ 1 ║
╚════╧════════╧════════╧═══════════════════╧═══════════════════════════════════════════════════════╧══════════╧══════════╧═══════════╧═══════╧═══════════╝
explain=details offre la visione più completa di come le query SPARQL vengono pianificate ed eseguite internamente da Neptune.
Riepiloghiamo ogni sezione per capire cosa vi sta dicendo:

3\. openCypher
Per generare un EXPLAIN plan in openCypher si usa il parametro explain=details (in Jupyter potete anche ricorrere ai comandi magic cell):
curl https://<your-neptune-endpoint>:<port>/openCypher \
-d "query=MATCH (c:City {name: 'London'}) RETURN c" \
-d "explain=details"
Esempio di output:
Query:
MATCH (c:City {name: 'London'}) RETURN c
╔════╤════════╤════════╤═══════════════════╤════════════════════╤═════════════════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪════════════════════╪═════════════════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFESubquery │ subQuery=subQuery1 │ - │ 0 │ 10 │ 0.00 │ 5.00 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ TermResolution │ vars=[?c] │ id2value_opencypher │ 10 │ 10 │ 1.00 │ 1.00 ║
╚════╧════════╧════════╧═══════════════════╧════════════════════╧═════════════════════╧══════════╧═══════════╧═══════╧═══════════╝subQuery1:
╔════╤════════╤════════╤═════════════════╤═══════════════════════════════════════════════════════════╤══════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═════════════════╪═══════════════════════════════════════════════════════════╪══════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ DFEPipelineScan │ pattern=Node((?anon_node)-[:?rel]->()) │ - │ 0 │ 1000 │ 0.00 │ 0.66 ║
║ │ │ │ │ inlineFilters=[(?label = :City), (?name = 'London')] │ │ │ │ │ ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFEProject │ columns=[?c] │ - │ 1000 │ 1000 │ 1.00 │ 0.14 ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ DFEDrain │ limit=10 │ - │ 1000 │ 0 │ 0.00 │ 0.11 ║
╚════╧════════╧════════╧═════════════════╧═══════════════════════════════════════════════════════════╧══════╧══════════╧═══════════╧═══════╧═══════════╝
explain=details in openCypher mostra le fasi di esecuzione, la logica di join, i limiti e le stime sui pattern in formato tabellare: molto più utile per l'analisi delle prestazioni rispetto all'output standard.
Riepiloghiamo ogni sezione per capire cosa vi sta dicendo:

Come interpretare l'output
L'output di PROFILE in Gremlin scompone sia le fasi di esecuzione sia il loro costo. Le Repeat Metrics sono particolarmente utili per analizzare i loop di traversal, una delle trappole di performance più comuni nelle query sui grafi. Permettono di individuare i segmenti di traversal più costosi e di capire come la logica di filtri e percorsi influisce sull'esecuzione.
Per SPARQL e openCypher, la modalità details trasforma piani statici in un'analisi puntuale, passo per passo, con informazioni come tipi di join, ordine di proiezione, filtri, costo temporale per operatore e volumi di dati stimati a confronto con quelli effettivi.
Caso di studio: ottimizzazione Gremlin in azione
Analizziamo una semplice query Gremlin di esempio. La query parte dal nodo che rappresenta la città di Londra. Da lì risale all'indietro lungo tutte le connessioni in entrata fino a tre passi di distanza, evitando di ripassare due volte sullo stesso nodo. Poi avanza di un passo dai nodi raggiunti per individuare quelli connessi. Da questi seleziona solo gli eventi (cioè quelli con la proprietà type impostata su "event"). Infine restituisce fino a 50 risultati corrispondenti. Ecco la query in Gremlin:
g.V()
.has("name", "London")
.hasLabel("city")
.repeat(in().simplePath())
.times(3)
.out()
.has("type", "event")
.limit(50)
Explain Plan:
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().has("name", "London").hasLabel("city").repeat(in().simplePath()).times(3).out().has("type", "event").limit(50)
Original Traversal
==================
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75, joinTime=4, hashJoin=true, actualTotalOutput=2} [1]\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33, hashJoin=true, joinTime=0, actualTotalOutput=2} [1]\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . SimplePathFilter(?1, ?3)) .], {estimatedCardinality=70000, hashJoin=true, indexTime=0, joinTime=5} [2]\
}\
Emit {\
Filter(false)\
}\
LoopsCondition {\
LoopsFilter([?1, ?3],eq(3))\
}\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
}, finishers=[filter(type=event), limit(50)], annotations={path=[Vertex(?1):GraphStep, Repeat[Vertex(?3):VertexStep], Vertex(?4):VertexStep], joinStats=true, optimizationTime=519, maxVarId=9, executionTime=483} [3]\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75}) [1]
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33}) [1]
|-- RepeatOp
|-- <upstream input> (Iteration 0) [visited=2, output=2 (until=0, emit=0), next=2]
|-- BindingSetQueue (Iteration 1) [visited=250, output=250 (until=0, emit=0), next=250]
|-- DynamicJoinOp(PatternNode[(?3, ?5, ?1, ?6) . ...]) [2]
|-- BindingSetQueue (Iteration 2) [visited=950, output=950 (until=0, emit=0), next=950]
|-- BindingSetQueue (Iteration 3) [visited=19500, output=19500 (until=19500, emit=0), next=0]
|-- VertexStep(OUT)
|-- FilterStep(type = event) [3]
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 483.222
Serialization: 2798.304
Traversal Metrics
=================
Step Count Traversers Time (ms)
------------------------------------------------------------
NeptuneGraphQueryStep 50 50 403.187
NeptuneTraverserConverterStep 50 50 80.035
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 2 2 0 0 2
1 250 250 0 0 250
2 950 950 0 0 950
3 19500 19500 19500 0 0
------------------------------------------------------
20702 20702 19500 0 1202
Warnings:
⚠ reverse traversal with no edge label(s) [2]
⚠ high fan-out detected in repeat [2]
⚠ filter applied late in traversal chain [3]
Cosa rivela l'EXPLAIN plan
[x] indica dove trovare ciascuna informazione nel piano qui sopra:
- [1] Avvio inefficiente: anche se la cardinalità è bassa, entrambi i filtri potrebbero essere riordinati per ottenere un pruning migliore. Più alta è la cardinalità, più ampio è l'intervallo di valori possibili nel dataset, il che si traduce in un dataset restituito più piccolo perché meno valori soddisfano la condizione. L'obiettivo è far restituire per primo il dataset più piccolo. Immaginate, ad esempio, di avere due filtri su 10.000 nodi ciascuno: uno seleziona il 50% dei nodi, l'altro il 10%. Conviene applicare prima il filtro al 10%, in modo da passare al filtro successivo solo 1.000 nodi. Procedendo nell'ordine inverso si passerebbero cinque volte tanti nodi alla condizione successiva, con più dati da elaborare e tempi di query più lunghi.
- [2]
.in()non ha un'edge label, quindi vengono scansionati tutti gli archi in entrata. Il traversal di repeat esplode (da 2 a quasi 20K nodi). - [3] I filtri
.out()e.has("type", "event")vengono applicati dopo questa enorme espansione, ed è inefficiente. - Conteggio totale del traversal: oltre 20K; un'enorme quantità di lavoro sprecato.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Versione ottimizzata
g.V()
.hasLabel("city")
.has("name", "London")
.repeat(in("located_in").simplePath())
.times(3)
.out("hosts")
.has("type", "event")
.limit(50)
Miglioramenti apportati
- Aggiunti i filtri sulle edge label sia su
.in()sia su.out() - Spostato
.has("type", "event")più a monte per ridurre il costo a valle - Mantenuto
.simplePath()per la protezione dai cicli, ma reso opzionale per i test
Output PROFILE dopo l'ottimizzazione
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().hasLabel("city").has("name", "London")
.repeat(in("located_in").simplePath()).times(3)
.out("hosts").has("type", "event").limit(50)
Original Traversal
==================
[GraphStep(vertex,[]),\
HasStep([~label.eq(city)]),\
HasStep([name.eq(London)]),\
RepeatStep(emit(false), [VertexStep(IN,[located_in]), PathFilterStep(simple), RepeatEndStep], until(loops(3))),\
VertexStep(OUT,[hosts]),\
HasStep([type.eq(event)]),\
RangeGlobalStep(0,50)]
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=3000, indexTime=21, actualTotalOutput=7}\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=1, indexTime=62, actualTotalOutput=1}\
RepeatNode {\
Repeat {\
PatternNode[(?3, <located_in>, ?1, ?) . project ?1,?3 . SimplePathFilter(?1,?3)] {estimatedCardinality=4500, hashJoin=true}\
}\
Emit { Filter(false) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(3)) }\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
},\
JoinGroupNode {\
PatternNode[(?3, <hosts>, ?4, ?) . project ?4 .], {estimatedCardinality=500, hashJoin=true}\
PatternNode[(?4, <type>, "event", ?) . project ?4 .], {estimatedCardinality=150, hashJoin=true}\
},\
finishers=[limit(50)],\
annotations={executionTime=192, optimizationTime=87, path=[Vertex(?1)->Repeat(?3)->Vertex(?4)]}\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) ...])
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) ...])
|-- RepeatOp
|-- Iteration 0: visited=1, output=1, next=1
|-- Iteration 1: visited=35, output=35, next=35
|-- Iteration 2: visited=85, output=85, next=85
|-- Iteration 3: visited=120, output=120, next=0
|-- DynamicJoinOp(PatternNode[(?3, <hosts>, ?4, ?) ...])
|-- DynamicJoinOp(PatternNode[(?4, <type>, "event", ?) ...])
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 172.329
Serialization: 817.502
Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
---------------------------------------------------------------------
NeptuneGraphQueryStep 50 50 139.438 80.9
NeptuneTraverserConverterStep 50 50 32.891 19.1
TOTAL 172.329
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 0 1
1 35 35 0 0 35
2 85 85 0 0 85
3 120 120 0 0 0
------------------------------------------------------
241 241 0 0 121
Predicates
==========
# of predicates: 10
Results
=======
Count: 50
Output: [v[302], v[417], v[501], v[519], v[520], v[622], v[635], v[780], v[801], ...]
Response serializer: GRYO_V3D0
Response size (bytes): 18310
Index Operations
================
Query execution:
# of statement index ops: 4
# of unique statement index ops: 4
Duplication ratio: 1.00
# of terms materialized: 0
Serialization:
# of statement index ops: 100
# of unique statement index ops: 88
Duplication ratio: 1.14
# of terms materialized: 145
Risultato:
- Nodi totali attraversati: ~886 contro ~20.702
- Tempo di query ridotto di oltre il 60%
- Minore pressione sulla memoria e minor rischio di timeout
TL;DR — Cosa cercare in EXPLAIN/PROFILE
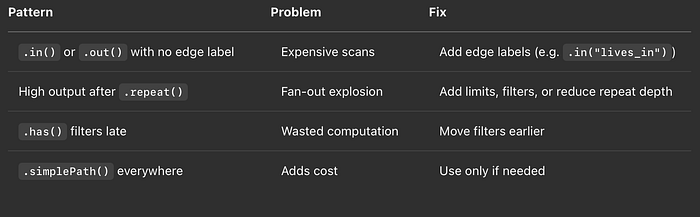
Tabella riassuntiva delle aree chiave individuate nell'EXPLAIN plan
Consigli e accorgimenti
- Anticipate i filtri: applicateli il prima possibile nella query.
- Scegliete la direzione giusta: invertite il traversal se conduce a punti di partenza più selettivi.
- Attenzione a OPTIONAL (SPARQL): può aumentare drasticamente la complessità del piano.
- Valutate la cardinalità delle label: le label ad alta cardinalità funzionano meglio come radici della query.
- Non trascurate il design del modello: a volte i problemi di performance sono il sintomo di una struttura del grafo poco efficace.
Visualizzare i query plan
Per i piani di grandi dimensioni, vale la pena scrivere uno script Python che faccia il parsing dell'output JSON e lo renda come un albero con Graphviz o D3.js. È un ottimo modo per rendere la struttura più leggibile e condivisibile con il team.
Il comando EXPLAIN di Neptune è uno degli strumenti più sottoutilizzati nella cassetta degli attrezzi di chi sviluppa con i grafi. Una volta iniziato a usarlo, vi chiederete come avete fatto a farne a meno fino a ieri. Capire come ragiona il query planner vi permette di plasmare le query, e il grafo stesso, per ottenere risultati migliori e più rapidi.
E ora andate a fare debug di quei query plan da veri professionisti. 🕵️♀️
P.S.: se vi interessa un approfondimento sulla visualizzazione degli EXPLAIN plan o sul benchmarking delle prestazioni delle query, fatemelo sapere — sono sempre pronta a un po' di sano nerdismo sui grafi.
In DoiT International il nostro team è composto esclusivamente da Engineers senior. Siamo specializzati in consulenza cloud avanzata, progettazione architetturale e servizi di debugging. Che stiate muovendo i primi passi con i database a grafo, ottimizzando un sistema esistente o risolvendo problemi complessi, vi offriamo una consulenza esperta e su misura per le vostre esigenze.