Cloud Intelligence™
Au cœur du planificateur de requêtes : analyser les plans EXPLAIN dans Amazon Neptune
Cette page est également disponible en English, Deutsch, Español, Italiano, 日本語 et Português.









About Kate Gawron
Cloud database architect with 12+ years across operational and analytical platforms. AWS Ambassador. Speaker, webinar host, blogger, course creator.
Specialising in database modernisation, Aurora, RDS, Snowflake, and getting teams from raw data to production AI across EMEA.
Off the clock: strength training, cricket, and going sideways on a kart track.
My personal pageAvec Amazon Neptune, optimiser les performances revient souvent à avancer à tâtons dans une grotte sans lampe torche. Vos requêtes peuvent ralentir sans prévenir, ou votre traversée Gremlin qui tournait parfaitement sur un petit jeu de données prend soudain une éternité sur un graphe en production. Heureusement, Neptune offre de quoi rallumer la lumière : la commande EXPLAIN.
Dans cet article, nous verrons comment exploiter les plans EXPLAIN ou PROFILE dans les trois langages de requête de Neptune (Gremlin, SPARQL et openCypher) pour diagnostiquer les problèmes de performance, comprendre l'exécution des requêtes et optimiser vos workloads sur graphes.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Pourquoi EXPLAIN et PROFILE comptent
Contrairement aux bases de données relationnelles, les requêtes sur graphes impliquent souvent des traversées sur de nombreuses arêtes, du filtrage dynamique et du pattern matching. Les performances sont donc plus difficiles à anticiper et les stratégies d'indexation classiques ne s'appliquent pas toujours. C'est là qu'intervient le planificateur de requêtes : il vous montre comment Neptune interprète votre requête et où il risque de perdre du temps.
Comment générer des plans EXPLAIN
Voyons comment générer des plans EXPLAIN dans chacun des langages pris en charge.
1\. Gremlin
En Gremlin, on génère un plan PROFILE via l'endpoint HTTP profile dans le Neptune Workbench ou n'importe quel prompt compatible Gremlin prenant en charge les extensions Neptune. Utiliser PROFILE plutôt qu'EXPLAIN exécute la requête en temps réel et fournit ainsi des statistiques bien plus exploitables :
POST https://<your-neptune-endpoint>:<port>/gremlin/profile \
-d '{
"gremlin":"g.V().hasLabel(\"city\")
.has(\"name\", \"London\")
.emit()
.repeat(in().simplePath())
.times(2)
.limit(100)"
}'
Si vous exécutez ce code dans un Jupyter Notebook, vous pouvez utiliser à la place la commande magic cell :
%%gremlin profile
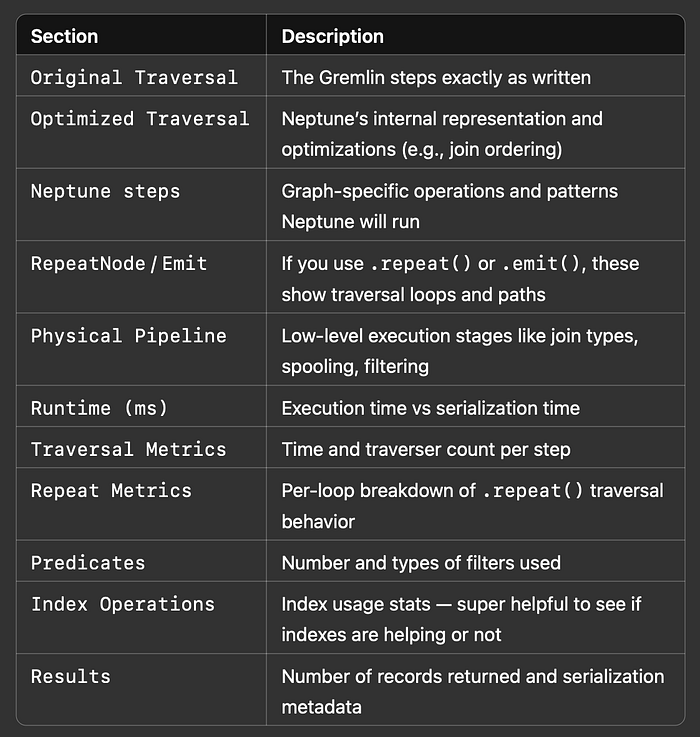
La requête s'exécute alors et renvoie un rapport de profilage complet incluant :
- Les étapes d'exécution
- Les durées et compteurs
- Les plans de requête optimisés et physiques
- Les métriques de traversée et de répétition
Exemple de sortie (tronquée pour plus de clarté) :
Query String
==================
g.V().hasLabel("city").has("name", "London").emit().repeat(in().simplePath()).times(2).limit(100)Original Traversal
==================
[GraphStep(vertex,[]), HasStep([...]), RepeatStep(...), RangeGlobalStep(0,100)]Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {...}\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {...}\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . SimplePathFilter(?1, ?3)) .], {...}\
}\
Emit { Filter(true) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(2)) }\
}\
}, finishers=[limit(100)]\
},\
NeptuneTraverserConverterStep\
]Physical Pipeline
=================
NeptuneGraphQueryStep
|-- JoinGroupOp
|-- DynamicJoinOp(...)
|-- RepeatOp
|-- BindingSetQueue (Iteration 1)...
|-- BindingSetQueue (Iteration 2)...
|-- LimitOp(100)Runtime (ms)
============
Query Execution: 392.686
Serialization: 2636.380Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
--------------------------------------------------------------
NeptuneGraphQueryStep(Vertex) 100 100 314.162 82.78
NeptuneTraverserConverterStep 100 100 65.333 17.22
TOTAL - - 379.495 -Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 1 1
1 61 61 0 61 61
2 38 38 38 0 0
------------------------------------------------------
100 100 38 62 62Results
=======
Count: 100
Response size (bytes): 23566
Reprenons chaque section pour bien comprendre ce qu'elle vous indique :
2\. SPARQL
En SPARQL, on utilise le paramètre explain=details avec sa requête. Voici comment obtenir un plan EXPLAIN détaillé avec curl (les commandes magic cell fonctionnent aussi sous Jupyter) :
curl https://<your-neptune-endpoint>:<port>/sparql \
-d "query=PREFIX ex: <https://example.com/> \
SELECT ?person WHERE { ?person a ex:City ; ex:name \"London\" }" \
-d "explain=details"
Exemple de sortie :
╔════╤════════╤════════╤═══════════════════╤═══════════════════════════════════════════════════════╤══════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪═══════════════════════════════════════════════════════╪══════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ PipelineJoin │ pattern=distinct(?person, rdf:type, ex:City) │ - │ 1 │ 2 │ 2.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ 3 │ - │ PipelineJoin │ pattern=distinct(?person, ex:name, \"London\") │ - │ 2 │ 2 │ 1.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 3 │ 4 │ - │ Projection │ vars=[?person] │ retain │ 2 │ 2 │ 1.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 4 │ - │ - │ TermResolution │ vars=[?person] │ id2value │ 2 │ 2 │ 1.00 │ 1 ║
╚════╧════════╧════════╧═══════════════════╧═══════════════════════════════════════════════════════╧══════════╧══════════╧═══════════╧═══════╧═══════════╝
explain=details donne la vue la plus complète de la façon dont les requêtes SPARQL sont planifiées et exécutées en interne dans Neptune.
Reprenons chaque section pour bien comprendre ce qu'elle vous indique :

3\. openCypher
Pour générer un plan EXPLAIN en openCypher, utilisez le paramètre explain=details (les commandes magic cell fonctionnent aussi sous Jupyter) :
curl https://<your-neptune-endpoint>:<port>/openCypher \
-d "query=MATCH (c:City {name: 'London'}) RETURN c" \
-d "explain=details"
Exemple de sortie :
Query:
MATCH (c:City {name: 'London'}) RETURN c
╔════╤════════╤════════╤═══════════════════╤════════════════════╤═════════════════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪════════════════════╪═════════════════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFESubquery │ subQuery=subQuery1 │ - │ 0 │ 10 │ 0.00 │ 5.00 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ TermResolution │ vars=[?c] │ id2value_opencypher │ 10 │ 10 │ 1.00 │ 1.00 ║
╚════╧════════╧════════╧═══════════════════╧════════════════════╧═════════════════════╧══════════╧═══════════╧═══════╧═══════════╝subQuery1:
╔════╤════════╤════════╤═════════════════╤═══════════════════════════════════════════════════════════╤══════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═════════════════╪═══════════════════════════════════════════════════════════╪══════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ DFEPipelineScan │ pattern=Node((?anon_node)-[:?rel]->()) │ - │ 0 │ 1000 │ 0.00 │ 0.66 ║
║ │ │ │ │ inlineFilters=[(?label = :City), (?name = 'London')] │ │ │ │ │ ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFEProject │ columns=[?c] │ - │ 1000 │ 1000 │ 1.00 │ 0.14 ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ DFEDrain │ limit=10 │ - │ 1000 │ 0 │ 0.00 │ 0.11 ║
╚════╧════════╧════════╧═════════════════╧═══════════════════════════════════════════════════════════╧══════╧══════════╧═══════════╧═══════╧═══════════╝
En openCypher, explain=details affiche les étapes d'exécution, la logique des jointures, les limites et les estimations de patterns sous forme de tableau, bien plus utile pour l'analyse de performance que la sortie standard.
Reprenons chaque section pour bien comprendre ce qu'elle vous indique :

Interpréter la sortie
La sortie PROFILE de Gremlin détaille à la fois les étapes d'exécution et leur coût. Les Repeat Metrics sont particulièrement utiles pour comprendre les boucles de traversée, un piège classique de performance dans les requêtes sur graphes. Vous pouvez ainsi repérer les segments coûteux et observer l'impact des filtres ou de la logique de chemin sur l'exécution.
Pour SPARQL et openCypher, le mode details transforme des plans statiques en une analyse pas à pas, avec le détail des types de jointures, l'ordre de projection, les filtres, le coût en temps par opérateur et la comparaison entre volumes de données estimés et réels.
Étude de cas : optimisation Gremlin en pratique
Décortiquons un exemple simple de requête Gremlin. Elle démarre au nœud représentant la ville de Londres. À partir de là, elle remonte toutes les connexions entrantes jusqu'à trois niveaux de profondeur, sans jamais repasser deux fois par le même nœud. Puis elle avance d'un pas depuis chaque point d'arrivée pour repérer les nœuds connectés. Elle ne retient ensuite que les événements (autrement dit, ceux dont la propriété type vaut event). Enfin, elle renvoie jusqu'à 50 résultats correspondants. Voici la requête écrite en Gremlin :
g.V()
.has("name", "London")
.hasLabel("city")
.repeat(in().simplePath())
.times(3)
.out()
.has("type", "event")
.limit(50)
Plan EXPLAIN :
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().has("name", "London").hasLabel("city").repeat(in().simplePath()).times(3).out().has("type", "event").limit(50)
Original Traversal
==================
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75, joinTime=4, hashJoin=true, actualTotalOutput=2} [1]\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33, hashJoin=true, joinTime=0, actualTotalOutput=2} [1]\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . SimplePathFilter(?1, ?3)) .], {estimatedCardinality=70000, hashJoin=true, indexTime=0, joinTime=5} [2]\
}\
Emit {\
Filter(false)\
}\
LoopsCondition {\
LoopsFilter([?1, ?3],eq(3))\
}\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
}, finishers=[filter(type=event), limit(50)], annotations={path=[Vertex(?1):GraphStep, Repeat[Vertex(?3):VertexStep], Vertex(?4):VertexStep], joinStats=true, optimizationTime=519, maxVarId=9, executionTime=483} [3]\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75}) [1]
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33}) [1]
|-- RepeatOp
|-- <upstream input> (Iteration 0) [visited=2, output=2 (until=0, emit=0), next=2]
|-- BindingSetQueue (Iteration 1) [visited=250, output=250 (until=0, emit=0), next=250]
|-- DynamicJoinOp(PatternNode[(?3, ?5, ?1, ?6) . ...]) [2]
|-- BindingSetQueue (Iteration 2) [visited=950, output=950 (until=0, emit=0), next=950]
|-- BindingSetQueue (Iteration 3) [visited=19500, output=19500 (until=19500, emit=0), next=0]
|-- VertexStep(OUT)
|-- FilterStep(type = event) [3]
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 483.222
Serialization: 2798.304
Traversal Metrics
=================
Step Count Traversers Time (ms)
------------------------------------------------------------
NeptuneGraphQueryStep 50 50 403.187
NeptuneTraverserConverterStep 50 50 80.035
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 2 2 0 0 2
1 250 250 0 0 250
2 950 950 0 0 950
3 19500 19500 19500 0 0
------------------------------------------------------
20702 20702 19500 0 1202
Warnings:
⚠ reverse traversal with no edge label(s) [2]
⚠ high fan-out detected in repeat [2]
⚠ filter applied late in traversal chain [3]
Ce que révèle le plan EXPLAIN
[x] indique où trouver l'information dans le plan ci-dessus :
- [1] Démarrage inefficace : la cardinalité a beau être faible, les deux filtres gagneraient à être réordonnés pour mieux élaguer. Plus la cardinalité est élevée, plus l'éventail des valeurs possibles dans le jeu de données est large, ce qui se traduit par un jeu de résultats plus restreint puisque moins de valeurs correspondent. L'objectif : renvoyer d'abord le plus petit jeu de données. Imaginez deux filtres potentiellement appliqués sur 10 000 nœuds chacun. L'un sélectionne 50 % de ces nœuds, l'autre 10 %. Vous voulez que le filtre à 10 % passe en premier afin de ne transmettre que 1 000 nœuds au filtre suivant. Dans le sens inverse, ce sont cinq fois plus de nœuds qui sont transmis à la condition suivante : davantage de données traitées et donc des requêtes plus lentes.
- [2]
.in()n'a pas de label d'arête, ce qui entraîne le balayage de toutes les arêtes entrantes. La traversée répétée explose en taille (de 2 à près de 20 000 nœuds). - [3] Les filtres
.out()et.has("type", "event")sont appliqués après cette importante expansion : peu efficace. - Nombre total de traversées : 20K+, soit énormément d'efforts gaspillés.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Version optimisée
g.V()
.hasLabel("city")
.has("name", "London")
.repeat(in("located_in").simplePath())
.times(3)
.out("hosts")
.has("type", "event")
.limit(50)
Améliorations apportées
- Ajout de filtres de label d'arête sur
.in()comme sur.out() - Déplacement de
.has("type", "event")plus en amont pour réduire le coût en aval - Conservation de
.simplePath()pour la protection contre les cycles, mais rendu optionnel pour les tests
Sortie PROFILE après optimisation
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().hasLabel("city").has("name", "London")
.repeat(in("located_in").simplePath()).times(3)
.out("hosts").has("type", "event").limit(50)
Original Traversal
==================
[GraphStep(vertex,[]),\
HasStep([~label.eq(city)]),\
HasStep([name.eq(London)]),\
RepeatStep(emit(false), [VertexStep(IN,[located_in]), PathFilterStep(simple), RepeatEndStep], until(loops(3))),\
VertexStep(OUT,[hosts]),\
HasStep([type.eq(event)]),\
RangeGlobalStep(0,50)]
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=3000, indexTime=21, actualTotalOutput=7}\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=1, indexTime=62, actualTotalOutput=1}\
RepeatNode {\
Repeat {\
PatternNode[(?3, <located_in>, ?1, ?) . project ?1,?3 . SimplePathFilter(?1,?3)] {estimatedCardinality=4500, hashJoin=true}\
}\
Emit { Filter(false) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(3)) }\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
},\
JoinGroupNode {\
PatternNode[(?3, <hosts>, ?4, ?) . project ?4 .], {estimatedCardinality=500, hashJoin=true}\
PatternNode[(?4, <type>, "event", ?) . project ?4 .], {estimatedCardinality=150, hashJoin=true}\
},\
finishers=[limit(50)],\
annotations={executionTime=192, optimizationTime=87, path=[Vertex(?1)->Repeat(?3)->Vertex(?4)]}\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) ...])
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) ...])
|-- RepeatOp
|-- Iteration 0: visited=1, output=1, next=1
|-- Iteration 1: visited=35, output=35, next=35
|-- Iteration 2: visited=85, output=85, next=85
|-- Iteration 3: visited=120, output=120, next=0
|-- DynamicJoinOp(PatternNode[(?3, <hosts>, ?4, ?) ...])
|-- DynamicJoinOp(PatternNode[(?4, <type>, "event", ?) ...])
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 172.329
Serialization: 817.502
Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
---------------------------------------------------------------------
NeptuneGraphQueryStep 50 50 139.438 80.9
NeptuneTraverserConverterStep 50 50 32.891 19.1
TOTAL 172.329
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 0 1
1 35 35 0 0 35
2 85 85 0 0 85
3 120 120 0 0 0
------------------------------------------------------
241 241 0 0 121
Predicates
==========
# of predicates: 10
Results
=======
Count: 50
Output: [v[302], v[417], v[501], v[519], v[520], v[622], v[635], v[780], v[801], ...]
Response serializer: GRYO_V3D0
Response size (bytes): 18310
Index Operations
================
Query execution:
# of statement index ops: 4
# of unique statement index ops: 4
Duplication ratio: 1.00
# of terms materialized: 0
Serialization:
# of statement index ops: 100
# of unique statement index ops: 88
Duplication ratio: 1.14
# of terms materialized: 145
Résultat
- Nombre total de nœuds traversés : ~886 contre ~20 702
- Temps de requête réduit de plus de 60 %
- Pression mémoire et risque de timeout réduits
TL;DR — Ce qu'il faut chercher dans EXPLAIN/PROFILE
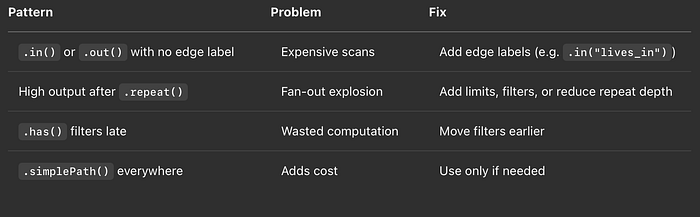
Tableau présentant les zones clés du plan EXPLAIN
Astuces et bonnes pratiques
- Faites descendre les filtres : appliquez-les le plus tôt possible dans votre requête.
- Choisissez le bon sens : inversez la traversée si elle conduit à des points de départ plus sélectifs.
- Méfiez-vous d'OPTIONAL (SPARQL) : il peut considérablement alourdir le plan.
- Tenez compte de la cardinalité des labels : les labels à forte cardinalité font de meilleures racines de requête.
- N'oubliez pas la modélisation : un problème de performance trahit parfois une structure de graphe mal pensée.
Visualiser les plans de requête
Pour les plans volumineux, pensez à écrire un script Python qui parse la sortie JSON et la restitue sous forme d'arbre avec Graphviz ou D3.js. Excellent moyen de rendre la structure plus digeste et plus facile à partager avec vos collègues.
La commande EXPLAIN de Neptune est l'un des outils les plus sous-exploités de la boîte à outils du développeur de graphes. Une fois adoptée, vous vous demanderez comment vous avez pu vous en passer. Comprendre le raisonnement du planificateur de requêtes vous permet de modeler vos requêtes — et votre graphe lui-même — pour des résultats meilleurs et plus rapides.
À vous de jouer : déboguez ces plans de requête comme un pro. 🕵️♀️
PS : si un approfondissement sur la visualisation des plans EXPLAIN ou le benchmarking des performances de requête vous intéresse, faites-le-moi savoir — je suis toujours partante pour un peu de geekerie autour des graphes.
Chez DoiT International, notre équipe est exclusivement composée de talents senior en ingénierie. Nous sommes spécialisés dans le conseil cloud avancé, la conception architecturale et les services de débogage. Que vous prépariez vos premiers pas avec les bases de données de graphes, que vous optimisiez un système existant ou que vous résolviez des problèmes complexes, nous vous apportons des conseils experts et sur mesure pour répondre à vos besoins.