Cloud Intelligence™
Dentro del Query Planner: cómo analizar planes EXPLAIN en Amazon Neptune
Esta página también está disponible en English, Deutsch, Français, Italiano, 日本語 y Português.









About Kate Gawron
Cloud database architect with 12+ years across operational and analytical platforms. AWS Ambassador. Speaker, webinar host, blogger, course creator.
Specialising in database modernisation, Aurora, RDS, Snowflake, and getting teams from raw data to production AI across EMEA.
Off the clock: strength training, cricket, and going sideways on a kart track.
My personal pageCuando trabajas con Amazon Neptune, ajustar el rendimiento puede sentirse como avanzar a ciegas dentro de una cueva oscura. Las consultas se vuelven lentas sin razón aparente, o esa traversal de Gremlin que funcionaba perfecto sobre un dataset pequeño tarda una eternidad en un grafo de producción. Por suerte, Neptune nos da una herramienta para encender la luz: el comando EXPLAIN.
En este post vamos a ver cómo usar planes EXPLAIN o PROFILE en los tres lenguajes de consulta que soporta Neptune (Gremlin, SPARQL y openCypher) para diagnosticar problemas de rendimiento, entender la ejecución de las consultas y optimizar tus workloads de grafos.
PerfectScale™ for Kubernetes
Ready to optimize?
Get your free Kubernetes savings analysis
Por qué importan EXPLAIN y PROFILE
A diferencia de las bases de datos relacionales, las consultas sobre grafos suelen implicar traversals por muchas aristas, filtrado dinámico y matching de patrones. Eso hace que el rendimiento sea más difícil de predecir, y las estrategias tradicionales de indexación no siempre aplican. Ahí entra el query planner: te muestra cómo Neptune está interpretando tu consulta y dónde podría estar perdiendo tiempo.
Cómo generar planes EXPLAIN
Veamos cómo se generan los planes EXPLAIN en cada uno de los lenguajes soportados.
1\. Gremlin
En Gremlin, el plan PROFILE se genera usando el endpoint HTTP profile en el Neptune Workbench o cualquier prompt compatible con Gremlin que soporte las extensiones de Neptune. Usar PROFILE en lugar de EXPLAIN ejecuta la consulta en tiempo real y entrega estadísticas mucho más útiles:
POST https://<your-neptune-endpoint>:<port>/gremlin/profile \
-d '{
"gremlin":"g.V().hasLabel(\"city\")
.has(\"name\", \"London\")
.emit()
.repeat(in().simplePath())
.times(2)
.limit(100)"
}'
Si corres este código en un Jupyter Notebook, también puedes usar el comando de magic cell:
%%gremlin profile
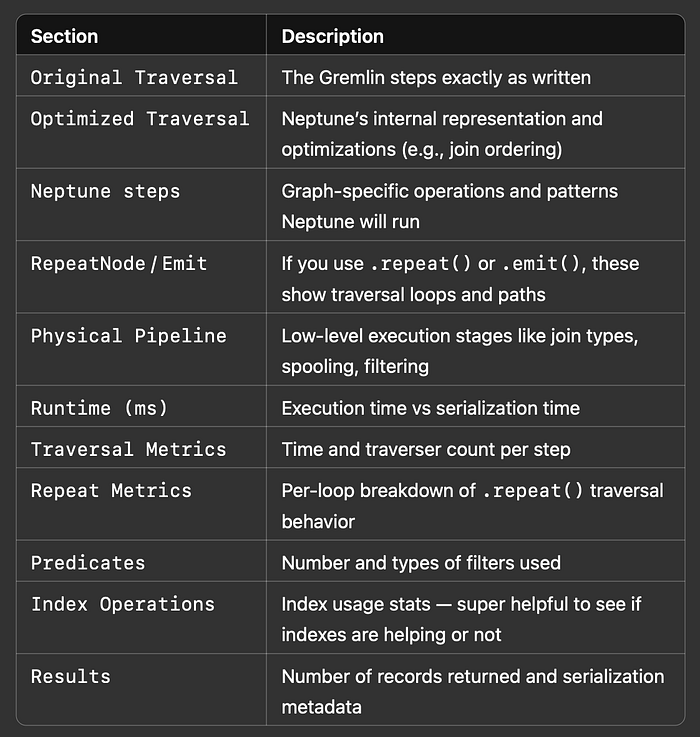
Esto ejecuta la consulta y devuelve un reporte de profile completo, que incluye:
- Pasos de ejecución
- Duraciones y conteos
- Planes de consulta optimizados y físicos
- Métricas de traversal y de repeat
Salida de ejemplo (truncada para mayor claridad):
Query String
==================
g.V().hasLabel("city").has("name", "London").emit().repeat(in().simplePath()).times(2).limit(100)Original Traversal
==================
[GraphStep(vertex,[]), HasStep([...]), RepeatStep(...), RangeGlobalStep(0,100)]Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {...}\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {...}\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . SimplePathFilter(?1, ?3)) .], {...}\
}\
Emit { Filter(true) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(2)) }\
}\
}, finishers=[limit(100)]\
},\
NeptuneTraverserConverterStep\
]Physical Pipeline
=================
NeptuneGraphQueryStep
|-- JoinGroupOp
|-- DynamicJoinOp(...)
|-- RepeatOp
|-- BindingSetQueue (Iteration 1)...
|-- BindingSetQueue (Iteration 2)...
|-- LimitOp(100)Runtime (ms)
============
Query Execution: 392.686
Serialization: 2636.380Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
--------------------------------------------------------------
NeptuneGraphQueryStep(Vertex) 100 100 314.162 82.78
NeptuneTraverserConverterStep 100 100 65.333 17.22
TOTAL - - 379.495 -Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 1 1
1 61 61 0 61 61
2 38 38 38 0 0
------------------------------------------------------
100 100 38 62 62Results
=======
Count: 100
Response size (bytes): 23566
Veamos en qué consiste cada sección para que sepas qué te está mostrando:
2\. SPARQL
En SPARQL se usa el parámetro explain=details junto con la consulta. Así obtienes un plan EXPLAIN detallado con curl (también puedes usar los comandos de magic cell si trabajas en Jupyter):
curl https://<your-neptune-endpoint>:<port>/sparql \
-d "query=PREFIX ex: <https://example.com/> \
SELECT ?person WHERE { ?person a ex:City ; ex:name \"London\" }" \
-d "explain=details"
Salida de ejemplo:
╔════╤════════╤════════╤═══════════════════╤═══════════════════════════════════════════════════════╤══════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪═══════════════════════════════════════════════════════╪══════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ PipelineJoin │ pattern=distinct(?person, rdf:type, ex:City) │ - │ 1 │ 2 │ 2.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ 3 │ - │ PipelineJoin │ pattern=distinct(?person, ex:name, \"London\") │ - │ 2 │ 2 │ 1.00 │ 1 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 3 │ 4 │ - │ Projection │ vars=[?person] │ retain │ 2 │ 2 │ 1.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼───────────────────────────────────────────────────────┼──────────┼──────────┼───────────┼───────┼───────────╢
║ 4 │ - │ - │ TermResolution │ vars=[?person] │ id2value │ 2 │ 2 │ 1.00 │ 1 ║
╚════╧════════╧════════╧═══════════════════╧═══════════════════════════════════════════════════════╧══════════╧══════════╧═══════════╧═══════╧═══════════╝
explain=details ofrece la vista más completa de cómo Neptune planifica y ejecuta internamente las consultas SPARQL.
Veamos en qué consiste cada sección para que sepas qué te está mostrando:

3\. openCypher
Para generar un plan EXPLAIN en openCypher, usa el parámetro explain=details (también puedes usar los comandos de magic cell si trabajas en Jupyter):
curl https://<your-neptune-endpoint>:<port>/openCypher \
-d "query=MATCH (c:City {name: 'London'}) RETURN c" \
-d "explain=details"
Salida de ejemplo:
Query:
MATCH (c:City {name: 'London'}) RETURN c
╔════╤════════╤════════╤═══════════════════╤════════════════════╤═════════════════════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═══════════════════╪════════════════════╪═════════════════════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ SolutionInjection │ solutions=[{}] │ - │ 0 │ 1 │ 0.00 │ 0 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFESubquery │ subQuery=subQuery1 │ - │ 0 │ 10 │ 0.00 │ 5.00 ║
╟────┼────────┼────────┼───────────────────┼────────────────────┼─────────────────────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ TermResolution │ vars=[?c] │ id2value_opencypher │ 10 │ 10 │ 1.00 │ 1.00 ║
╚════╧════════╧════════╧═══════════════════╧════════════════════╧═════════════════════╧══════════╧═══════════╧═══════╧═══════════╝subQuery1:
╔════╤════════╤════════╤═════════════════╤═══════════════════════════════════════════════════════════╤══════╤══════════╤═══════════╤═══════╤═══════════╗
║ ID │ Out #1 │ Out #2 │ Name │ Arguments │ Mode │ Units In │ Units Out │ Ratio │ Time (ms) ║
╠════╪════════╪════════╪═════════════════╪═══════════════════════════════════════════════════════════╪══════╪══════════╪═══════════╪═══════╪═══════════╣
║ 0 │ 1 │ - │ DFEPipelineScan │ pattern=Node((?anon_node)-[:?rel]->()) │ - │ 0 │ 1000 │ 0.00 │ 0.66 ║
║ │ │ │ │ inlineFilters=[(?label = :City), (?name = 'London')] │ │ │ │ │ ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 1 │ 2 │ - │ DFEProject │ columns=[?c] │ - │ 1000 │ 1000 │ 1.00 │ 0.14 ║
╟────┼────────┼────────┼─────────────────┼───────────────────────────────────────────────────────────┼──────┼──────────┼───────────┼───────┼───────────╢
║ 2 │ - │ - │ DFEDrain │ limit=10 │ - │ 1000 │ 0 │ 0.00 │ 0.11 ║
╚════╧════════╧════════╧═════════════════╧═══════════════════════════════════════════════════════════╧══════╧══════════╧═══════════╧═══════╧═══════════╝
explain=details en openCypher muestra etapas de ejecución, lógica de joins, límites y estimaciones de patrones en formato tabular, mucho más útil para análisis de rendimiento que la salida estándar.
Veamos en qué consiste cada sección para que sepas qué te está mostrando:

Cómo interpretar la salida
La salida de PROFILE en Gremlin desglosa tanto las etapas de ejecución como su costo. Las Repeat Metrics resultan especialmente útiles para entender los loops de traversal, una trampa de rendimiento muy común en consultas de grafos. Permiten identificar segmentos costosos del traversal y ver cómo la lógica de filtros o de paths impacta la ejecución.
Para SPARQL y openCypher, el modo details convierte planes estáticos en un análisis detallado paso a paso, con datos como tipos de join, orden de proyección, filtros, costo de tiempo por operador y volúmenes de datos estimados vs. reales.
Caso práctico: optimización de Gremlin en acción
Analicemos un ejemplo simple de consulta en Gremlin. Esta consulta arranca en el nodo que representa la ciudad de Londres. Desde ahí, recorre hacia atrás todas las conexiones entrantes hasta tres pasos de distancia, sin pasar dos veces por el mismo nodo. Luego avanza un paso desde donde haya llegado para encontrar nodos conectados. Después, se queda solo con los eventos (es decir, los que tienen la propiedad type igual a "event"). Por último, devuelve hasta 50 resultados que coincidan. Así se ve la consulta en Gremlin:
g.V()
.has("name", "London")
.hasLabel("city")
.repeat(in().simplePath())
.times(3)
.out()
.has("type", "event")
.limit(50)
Plan EXPLAIN:
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().has("name", "London").hasLabel("city").repeat(in().simplePath()).times(3).out().has("type", "event").limit(50)
Original Traversal
==================
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75, joinTime=4, hashJoin=true, actualTotalOutput=2} [1]\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33, hashJoin=true, joinTime=0, actualTotalOutput=2} [1]\
RepeatNode {\
Repeat {\
PatternNode[(?3, ?5, ?1, ?6) . project ?1,?3 . IsEdgeIdFilter(?6) . SimplePathFilter(?1, ?3)) .], {estimatedCardinality=70000, hashJoin=true, indexTime=0, joinTime=5} [2]\
}\
Emit {\
Filter(false)\
}\
LoopsCondition {\
LoopsFilter([?1, ?3],eq(3))\
}\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
}, finishers=[filter(type=event), limit(50)], annotations={path=[Vertex(?1):GraphStep, Repeat[Vertex(?3):VertexStep], Vertex(?4):VertexStep], joinStats=true, optimizationTime=519, maxVarId=9, executionTime=483} [3]\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=2, indexTime=75}) [1]
|-- SpoolerOp(100)
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=10000, indexTime=33}) [1]
|-- RepeatOp
|-- <upstream input> (Iteration 0) [visited=2, output=2 (until=0, emit=0), next=2]
|-- BindingSetQueue (Iteration 1) [visited=250, output=250 (until=0, emit=0), next=250]
|-- DynamicJoinOp(PatternNode[(?3, ?5, ?1, ?6) . ...]) [2]
|-- BindingSetQueue (Iteration 2) [visited=950, output=950 (until=0, emit=0), next=950]
|-- BindingSetQueue (Iteration 3) [visited=19500, output=19500 (until=19500, emit=0), next=0]
|-- VertexStep(OUT)
|-- FilterStep(type = event) [3]
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 483.222
Serialization: 2798.304
Traversal Metrics
=================
Step Count Traversers Time (ms)
------------------------------------------------------------
NeptuneGraphQueryStep 50 50 403.187
NeptuneTraverserConverterStep 50 50 80.035
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 2 2 0 0 2
1 250 250 0 0 250
2 950 950 0 0 950
3 19500 19500 19500 0 0
------------------------------------------------------
20702 20702 19500 0 1202
Warnings:
⚠ reverse traversal with no edge label(s) [2]
⚠ high fan-out detected in repeat [2]
⚠ filter applied late in traversal chain [3]
Lo que muestra el plan EXPLAIN
[x] indica dónde encontrar cada dato dentro del plan EXPLAIN anterior:
- [1] Inicio ineficiente: aunque la cardinalidad es baja, ambos filtros se podrían reordenar para podar mejor el dataset. A mayor cardinalidad, mayor el rango de valores posibles, lo que implica un dataset devuelto más pequeño porque coinciden menos valores. La idea es que primero se devuelva el dataset más pequeño. Por ejemplo, tienes dos filtros sobre potencialmente 10.000 nodos cada uno. Uno selecciona el 50 % de esos nodos y el otro el 10 %. Conviene procesar primero el filtro del 10 % para que solo 1.000 nodos pasen al siguiente filtro. Si lo haces al revés, pasas cinco veces más nodos al siguiente filtro, se procesan más datos y la consulta se vuelve más lenta.
- [2]
.in()no tiene edge label, por lo que escanea todas las aristas entrantes. El traversal del repeat explota en tamaño (de 2 a casi 20.000 nodos). - [3] Los filtros
.out()y.has("type", "event")se aplican después de esa expansión enorme, lo cual es ineficiente. - Conteo total del traversal: más de 20K; mucho esfuerzo desperdiciado.
Your cloud bill shouldn't be a mystery
Optimization, automation, expertise. In one platform.
Versión optimizada
g.V()
.hasLabel("city")
.has("name", "London")
.repeat(in("located_in").simplePath())
.times(3)
.out("hosts")
.has("type", "event")
.limit(50)
Mejoras aplicadas
- Se agregaron filtros de edge label tanto a
.in()como a.out() - Se movió
.has("type", "event")antes para reducir el costo aguas abajo - Se mantuvo
.simplePath()como protección contra ciclos, pero se dejó opcional para pruebas
Salida de PROFILE tras la optimización
*******************************************************
Neptune Gremlin Profile
*******************************************************
Query String
==================
g.V().hasLabel("city").has("name", "London")
.repeat(in("located_in").simplePath()).times(3)
.out("hosts").has("type", "event").limit(50)
Original Traversal
==================
[GraphStep(vertex,[]),\
HasStep([~label.eq(city)]),\
HasStep([name.eq(London)]),\
RepeatStep(emit(false), [VertexStep(IN,[located_in]), PathFilterStep(simple), RepeatEndStep], until(loops(3))),\
VertexStep(OUT,[hosts]),\
HasStep([type.eq(event)]),\
RangeGlobalStep(0,50)]
Optimized Traversal
===================
Neptune steps:
[\
NeptuneGraphQueryStep(Vertex) {\
JoinGroupNode {\
PatternNode[(?1, <~label>, ?2=<city>, <~>) . project ask .], {estimatedCardinality=3000, indexTime=21, actualTotalOutput=7}\
PatternNode[(?1, <name>, "London", ?) . project ?1 .], {estimatedCardinality=1, indexTime=62, actualTotalOutput=1}\
RepeatNode {\
Repeat {\
PatternNode[(?3, <located_in>, ?1, ?) . project ?1,?3 . SimplePathFilter(?1,?3)] {estimatedCardinality=4500, hashJoin=true}\
}\
Emit { Filter(false) }\
LoopsCondition { LoopsFilter([?1, ?3], eq(3)) }\
}, annotations={repeatMode=BFS, emitFirst=false, untilFirst=false, leftVar=?1, rightVar=?3}\
},\
JoinGroupNode {\
PatternNode[(?3, <hosts>, ?4, ?) . project ?4 .], {estimatedCardinality=500, hashJoin=true}\
PatternNode[(?4, <type>, "event", ?) . project ?4 .], {estimatedCardinality=150, hashJoin=true}\
},\
finishers=[limit(50)],\
annotations={executionTime=192, optimizationTime=87, path=[Vertex(?1)->Repeat(?3)->Vertex(?4)]}\
},\
NeptuneTraverserConverterStep\
]
Physical Pipeline
=================
NeptuneGraphQueryStep
|-- StartOp
|-- JoinGroupOp
|-- DynamicJoinOp(PatternNode[(?1, <~label>, ?2=<city>, <~>) ...])
|-- DynamicJoinOp(PatternNode[(?1, <name>, "London", ?) ...])
|-- RepeatOp
|-- Iteration 0: visited=1, output=1, next=1
|-- Iteration 1: visited=35, output=35, next=35
|-- Iteration 2: visited=85, output=85, next=85
|-- Iteration 3: visited=120, output=120, next=0
|-- DynamicJoinOp(PatternNode[(?3, <hosts>, ?4, ?) ...])
|-- DynamicJoinOp(PatternNode[(?4, <type>, "event", ?) ...])
|-- LimitOp(50)
Runtime (ms)
============
Query Execution: 172.329
Serialization: 817.502
Traversal Metrics
=================
Step Count Traversers Time (ms) % Dur
---------------------------------------------------------------------
NeptuneGraphQueryStep 50 50 139.438 80.9
NeptuneTraverserConverterStep 50 50 32.891 19.1
TOTAL 172.329
Repeat Metrics
==============
Iteration Visited Output Until Emit Next
------------------------------------------------------
0 1 1 0 0 1
1 35 35 0 0 35
2 85 85 0 0 85
3 120 120 0 0 0
------------------------------------------------------
241 241 0 0 121
Predicates
==========
# of predicates: 10
Results
=======
Count: 50
Output: [v[302], v[417], v[501], v[519], v[520], v[622], v[635], v[780], v[801], ...]
Response serializer: GRYO_V3D0
Response size (bytes): 18310
Index Operations
================
Query execution:
# of statement index ops: 4
# of unique statement index ops: 4
Duplication ratio: 1.00
# of terms materialized: 0
Serialization:
# of statement index ops: 100
# of unique statement index ops: 88
Duplication ratio: 1.14
# of terms materialized: 145
Resultado:
- Total de nodos recorridos: ~886 vs ~20.702
- Tiempo de consulta reducido en más del 60 %
- Menos presión de memoria y menor riesgo de timeout
TL;DR — Qué buscar en EXPLAIN/PROFILE
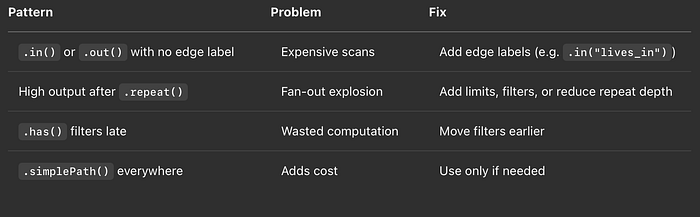
Tabla con las áreas clave que aparecen en el plan EXPLAIN
Tips y trucos
- Adelanta los filtros: aplícalos lo antes posible dentro de la consulta.
- Elige bien la dirección: invierte el traversal si así llegas a puntos de partida más selectivos.
- Cuidado con OPTIONAL (SPARQL): puede disparar la complejidad del plan.
- Considera la cardinalidad de los labels: los labels de alta cardinalidad rinden mejor como raíces de la consulta.
- No olvides el diseño del modelo: muchas veces los problemas de rendimiento son síntomas de una estructura de grafo deficiente.
Cómo visualizar los planes de consulta
Para planes grandes, conviene escribir un script en Python que parsee la salida JSON y la renderice como un árbol con Graphviz o D3.js. Es una forma excelente de hacer la estructura más fácil de leer y compartir con tu equipo.
El comando EXPLAIN de Neptune es una de las herramientas más subutilizadas en la caja de quien desarrolla con grafos. Una vez que empiezas a usarlo, te preguntarás cómo trabajaste tanto tiempo sin él. Entender cómo razona el query planner te permite moldear tus consultas, y el grafo en sí, para obtener resultados mejores y más rápidos.
Ahora sí, a depurar esos planes de consulta como un profesional. 🕵️♀️
PD: Si te interesa un follow-up con un deep dive sobre cómo visualizar planes EXPLAIN o hacer benchmarking de rendimiento, avísame — siempre estoy listo para un poco de nerdería de grafos.
En DoiT International, nuestro equipo está formado exclusivamente por talento senior de Engineering. Nos especializamos en consultoría avanzada en la nube, diseño de arquitecturas y servicios de debugging. Ya sea que estés dando tus primeros pasos con bases de datos de grafos, optimizando un sistema existente o resolviendo problemas complejos, te ofrecemos asesoría experta y a medida.