Foto von Reza Rostampisheh auf Unsplash
Wenn es um Parser geht, sind solche, die einen Abstract Syntax Tree (AST) aus dem Eingabetext erzeugen, in puncto Analyseleistung und Funktionsumfang das Maß der Dinge. Der größte Vorteil eines AST: Sie bekommen einen JSON-String, der die geparsten Informationen sauber klassifiziert. Genau darauf lassen sich hervorragend eigene Services aufbauen – und bei einem SQL-Statement als Eingabe gilt das umso mehr.
Jeder ernstzunehmende SQL-Editor setzt auf einen Parser. superQuery verwendet den Parser pegJs, ein JavaScript-basiertes System, das vom Team – inzwischen von DoiT International übernommen – so erweitert wurde, dass es auch den Großteil der BigQuery-Syntax effizient verarbeitet.
Über zetaSQL
Anfang 2019 hat Google den AST-basierten Parser zetaSQL als Open Source veröffentlicht, der produktiv zum Parsen und Formatieren von Abfragen in Google BigQuery und Cloud Spanner zum Einsatz kommt. Das Repository finden Sie hier. zetaSQL lässt sich mit bazel kompilieren und besteht überwiegend aus C++-Code; eine Java-Implementierung ist ebenfalls verfügbar.
Ein Blick in den Code zeigt: Der Parser bringt eine ganze Reihe an Funktionen mit, darunter:
- Formatieren eines SQL-Statements (sql_formatter.h)
- Analysieren eines SQL-Statements (analyzer.h)
- Auffinden von Syntaxfehlern und Rückgabe von Fehler, Zeile und Spalte (parse_helpers.h)
Auf den ersten Blick wirkt der Build im Repository unkompliziert. Damit Sie keine Zeit verlieren: Die Datei .bazelrc ist enorm wichtig, denn sie setzt die C++-Compiler-Version auf den Stand, der von der übrigen Google-Software unterstützt wird. Diese Datei muss beim Build also unbedingt vorhanden sein.
Außerdem stellt das zetaSQL-Repository (noch) kein Dockerfile bereit, mit dem sich die aktuelle Version von zetaSQL bauen und kompilieren lässt. Eines davon stelle ich hier bereit – auf Basis von Ubuntu 18.04 und der aktuellen bazel-Version.
Meine Implementierung (zetasql-analyzer-server) deckt Punkt 3 von oben ab – also den Syntaxfehler-Finder. Sie basiert auf einer Docker-Implementierung von apstndb namens zetasql-format-server (die Punkt 2 abdeckt). Unter der Haube läuft ein Go-Server, der die Formatter- bzw. Analyzer-API von zetaSQL kapselt und einen Endpunkt in Google Cloud Run bereitstellt.
Beispiele
Ein einfaches Beispiel
Hier eine Beispielausgabe des Analyzer-Endpunkts für die fehlerhafte Abfrage SELEC 1 (das T fehlt):
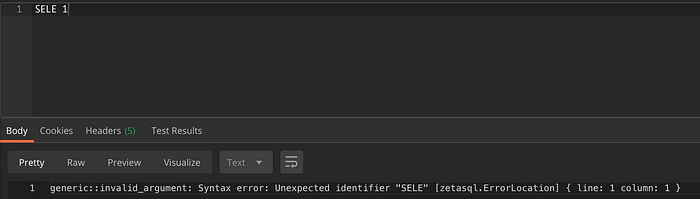
Für eine einfache Abfrage werden Fehlerposition, Zeile, Spalte und Fehlermeldung zurückgegeben.
Ein komplexeres Beispiel
Im folgenden Beispiel fehlt im zweiten Subselect das Schlüsselwort SELECT. Wie Sie sehen, weist der Parser genau darauf hin.
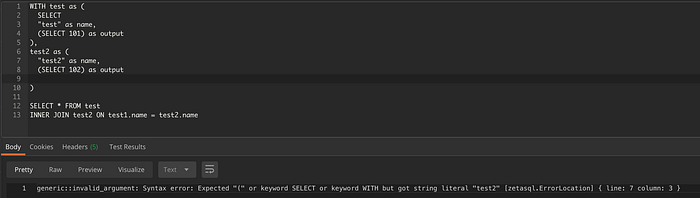
Fehlerposition für eine etwas komplexere Abfrage.
Wie steht es um Geschwindigkeit und Performance?
In den wenigen Tests, die ich bisher durchgeführt habe, blieben die meisten Antworten – selbst bei Abfragen mit über 600 Zeilen – unter einer Sekunde, im Mittel bei rund 300 ms.
Hier die Timing-Graphen für die beiden Beispiele, gemessen von meinem Laptop mit Highspeed-Internetverbindung:
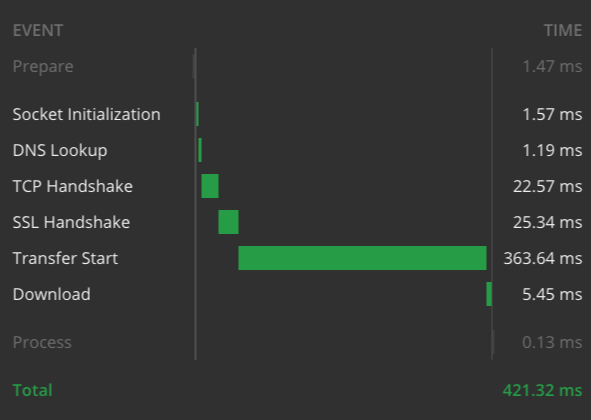
Antwortzeit für "SELE 1"
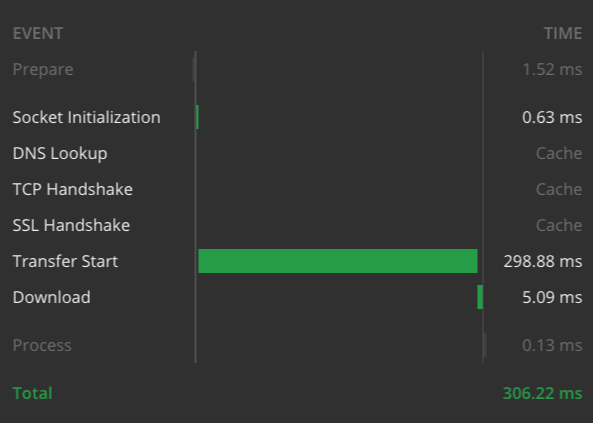
Antwortzeit für das etwas komplexere Beispiel von oben.
Den Stack hinter diesem schnellen Parsing bilden ein distroless-Container-Image (https://github.com/GoogleContainerTools/distroless) und eine serverless-Hardware-Umgebung (Cloud Run), als Eingabesprache dient C++.
Installation und Nutzung
Für die Installation lesen Sie am besten die README-Datei hier. Melden Sie sich gerne, wenn Sie bei der Einrichtung Unterstützung brauchen.
Sobald Sie einen Endpunkt in Cloud Run eingerichtet haben, fragen Sie ihn per curl ab:
curl -X POST -H 'Content-type: application/text' --data 'SLECT 1, ' https://<Ihr Endpunkt hier>
Zum Schluss
Viel Spaß beim Parsen!
Referenzen
- zetasql-analyzer-server: https://github.com/ebendutoit/zetasql-analyzer-server
- zetaSQL: https://github.com/google/zetasql
- zetasql-format-server: https://github.com/apstndb/zetasql-format-server