Foto di Reza Rostampisheh su Unsplash
Nel mondo dei parser, lo stato dell'arte per potenza e funzionalità di analisi del testo è rappresentato da un parser capace di costruire un albero sintattico astratto (AST) del testo stesso. Il vantaggio principale di un AST è la possibilità di lavorare con una stringa JSON che contiene la classificazione delle informazioni analizzate: una base estremamente utile e comoda su cui costruire servizi. E se il testo in input è un'istruzione SQL, lo è ancora di più.
Ogni editor SQL che si rispetti utilizza un parser. superQuery usa un parser chiamato pegJs, un sistema basato su JavaScript potenziato dal team oggi acquisito da DoiT International per gestire in modo efficiente anche gran parte della sintassi di Google BigQuery.
Cos'è zetaSQL
All'inizio del 2019 Google ha rilasciato in open source il parser basato su AST chiamato zetaSQL, lo stesso usato in produzione per il parsing e la formattazione delle query in Google BigQuery e Cloud Spanner. Il repository si trova qui. zetaSQL si compila con bazel ed è scritto principalmente in C++, ma è disponibile anche un'implementazione Java.
Esaminando il codice si scopre che il parser offre diverse funzionalità, tra cui:
- Formattazione di un'istruzione SQL (sql_formatter.h)
- Analisi di un'istruzione SQL (analyzer.h)
- Individuazione degli errori di sintassi, con restituzione di errore, riga e colonna (parse_helpers.h)
Dando un'occhiata al repository, ci si accorge subito che la build sembra semplice. Per farvi risparmiare tempo, vale la pena segnalare che il file .bazelrc è cruciale: imposta la versione del compilatore C++ al livello corretto, supportato dagli altri software Google. È quindi indispensabile averlo durante la build.
Inoltre, il repository base di zetaSQL non offre (ancora) un Dockerfile per compilarne l'ultima versione. Lo metto a disposizione qui, basato su Ubuntu 18.04 e sull'ultima versione di bazel.
La mia implementazione (zetasql-analyzer-server) copre il punto 3 visto sopra, cioè l'individuazione degli errori di sintassi. Si basa su un'implementazione Docker realizzata da apstndb e chiamata zetasql-format-server (che copre invece il punto 2). Dietro le quinte c'è un server in Go che incapsula l'API del formatter (o dell'analyzer) di zetaSQL ed espone un endpoint su Google Cloud Run.
Esempi
Esempio semplice
Ecco un esempio di output dell'endpoint analyzer per una query errata, SELEC 1 (manca la T):
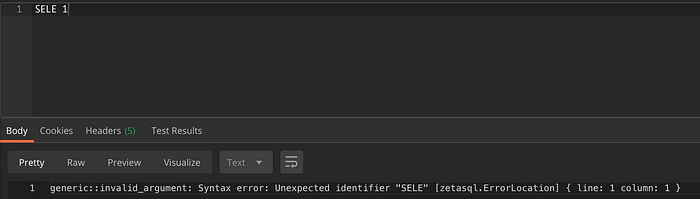
Per una query semplice vengono restituiti posizione dell'errore, riga, colonna e messaggio.
Esempio complesso
Nell'esempio qui sotto, nel secondo livello annidato della query manca la parola SELECT. Si vede chiaramente come il parser segnali questa informazione.
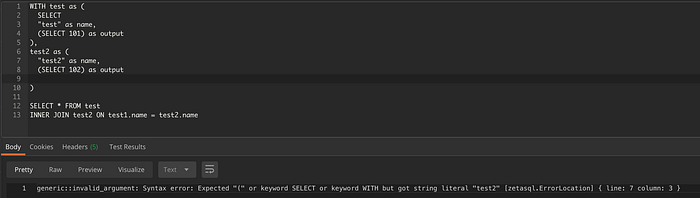
Posizione dell'errore per una query un po' più complessa.
E sul fronte velocità e prestazioni?
Dal numero limitato di test che ho eseguito, la maggior parte delle risposte (anche per query di oltre 600 righe) rimane entro 1 secondo, con una media di 300 ms.
Ecco i grafici dei tempi per i 2 esempi, eseguiti dal mio laptop con una connessione internet ad alta velocità:
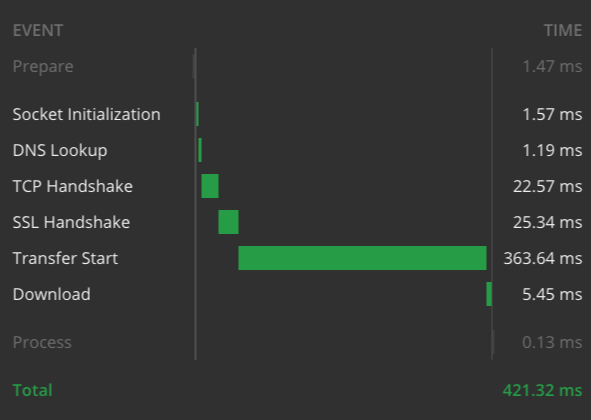
Tempo di risposta per "SELE 1"
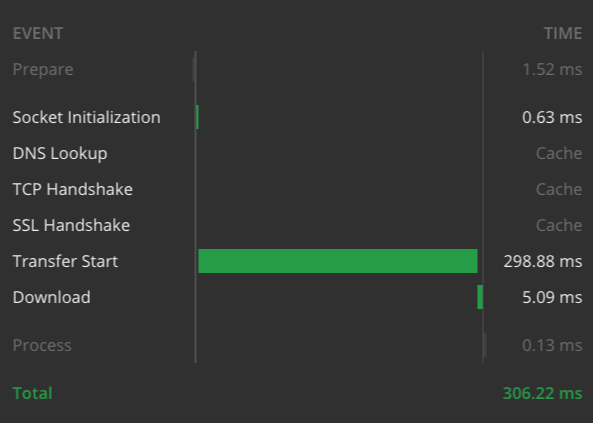
Tempo di risposta per l'esempio più complesso visto sopra.
Lo stack che permette un parsing così rapido si basa su un'immagine container distroless (https://github.com/GoogleContainerTools/distroless) e su un'infrastruttura serverless (Cloud Run), con il C++ come linguaggio di input.
Installazione e utilizzo
Per installarlo, vi invito a leggere il file README qui. Fatemi sapere se posso darvi una mano a metterlo in funzione.
Dopo aver creato un endpoint su Cloud Run, potete ottenere informazioni con un comando curl:
curl -X POST -H 'Content-type: application/text' --data 'SLECT 1, ' https://<il tuo endpoint qui>
Per concludere
Buon parsing!
Riferimenti
- zetasql-analyzer-server: https://github.com/ebendutoit/zetasql-analyzer-server
- zetaSQL: https://github.com/google/zetasql
- zetasql-format-server: https://github.com/apstndb/zetasql-format-server