Foto de Reza Rostampisheh no Unsplash
No mundo dos parsers, o estado da arte em poder e funcionalidade de análise de texto está nos parsers capazes de montar uma árvore de sintaxe abstrata (AST) a partir do seu texto. A grande vantagem da AST é gerar uma string JSON com as classificações das informações analisadas. Isso é extremamente útil e facilita muito a construção de serviços em cima dela. E quando o texto de entrada é uma instrução SQL, melhor ainda.
Todo editor SQL que se preze usa um parser. O superQuery usa um parser chamado pegJs, um sistema baseado em JavaScript que foi aprimorado pela equipe recém-adquirida pela DoiT International para também dar conta de boa parte da sintaxe do Google BigQuery de forma eficiente.
Sobre o zetaSQL
No início de 2019, o Google abriu o código do parser baseado em AST chamado zetaSQL, usado em produção para fazer parsing e formatação de queries no Google BigQuery e no Cloud Spanner. O repositório está aqui. O zetaSQL pode ser compilado com bazel e é composto majoritariamente por código C++, mas também há uma implementação em Java disponível.
Mergulhando no código, dá para ver que o parser tem várias funcionalidades, entre elas:
- Formatar uma instrução SQL (sql_formatter.h)
- Analisar uma instrução SQL (analyzer.h)
- Identificar erros de sintaxe e devolver o erro, a linha e a coluna (parse_helpers.h)
Olhando o repositório, percebemos rapidamente que parece fácil de buildar. Para te poupar tempo, vale destacar que o arquivo .bazelrc é muito importante: ele define a versão correta do compilador C++, conforme o que os outros softwares do Google suportam. Por isso, é fundamental ter esse arquivo na hora do build.
Além disso, o repositório base do zetaSQL ainda não traz um Dockerfile que permita buildar e compilar a versão mais recente do zetaSQL. Eu disponibilizo um aqui, baseado no Ubuntu 18.04 e na versão mais recente do bazel.
Minha implementação (zetasql-analyzer-server) resolve o ponto 3 acima, ou seja, o identificador de erros de sintaxe. Ela se baseia em uma implementação Docker feita pelo apstndb, chamada zetasql-format-server (que resolve o ponto 2 acima). Por baixo dos panos, trata-se de um servidor em Go que encapsula a API do formatador (ou do analisador) do zetaSQL e expõe um endpoint no Google Cloud Run.
Exemplos
Um caso simples
Veja um exemplo de saída do endpoint do analisador para uma query com erro SELEC 1 (faltando o T):
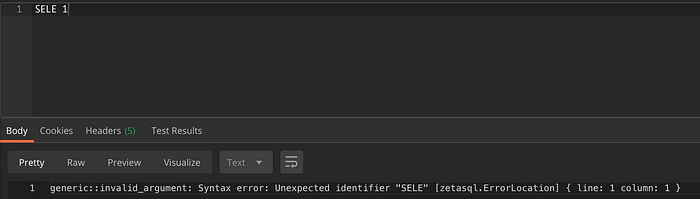
São retornados a localização do erro, a linha, a coluna e a mensagem de erro para uma query simples.
Um caso mais complicado
No exemplo abaixo, o segundo nível aninhado da query está sem a palavra SELECT. Dá para ver que o parser aponta essa informação.
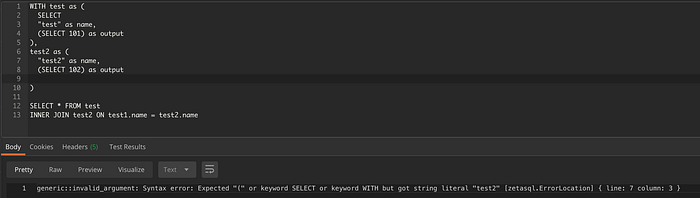
Localização do erro em uma query um pouco mais complicada.
E quanto à velocidade e ao desempenho?
Pelo número limitado de testes que rodei, a maioria das respostas (mesmo para queries com mais de 600 linhas) fica dentro de 1 segundo, com média de 300ms.
Veja os gráficos de tempo dos 2 exemplos a partir do meu laptop, com conexão de internet de alta velocidade:
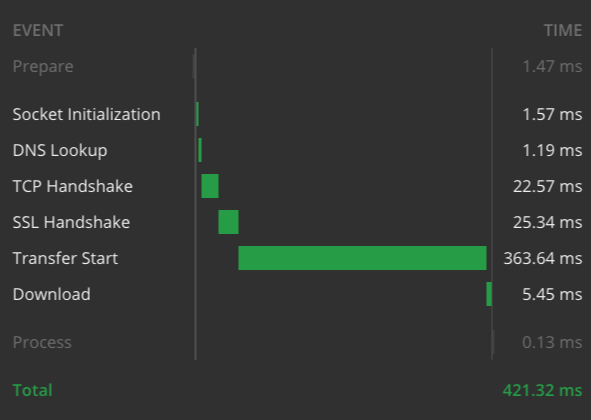
Tempo de resposta do evento para "SELE 1"
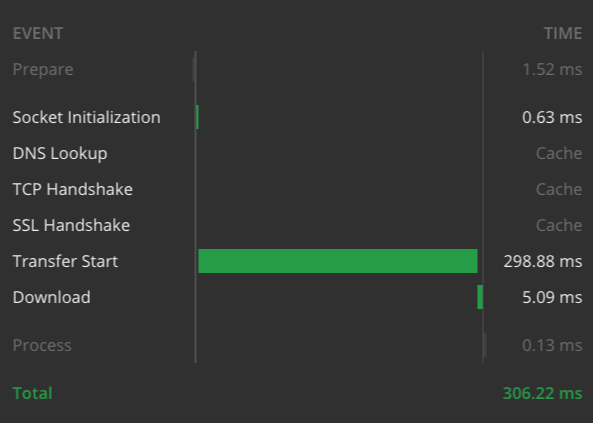
Tempo de resposta do evento para o exemplo mais complicado acima.
A stack que viabiliza esse parsing em alta velocidade usa uma imagem de container distroless (https://github.com/GoogleContainerTools/distroless) e uma implementação de hardware serverless (Cloud Run) com C++ como linguagem de entrada.
Instalação e uso
Para instalar, dá uma olhada no arquivo README aqui. Me avise em que posso ajudar para você colocar tudo no ar.
Depois de criar um endpoint no Cloud Run, você consegue obter informações dele com um comando curl:
curl -X POST -H 'Content-type: application/text' --data 'SLECT 1, ' https://<seu endpoint vai aqui>
Para finalizar
Bom parsing!
Referências
- zetasql-analyzer-server: https://github.com/ebendutoit/zetasql-analyzer-server
- zetaSQL: https://github.com/google/zetasql
- zetasql-format-server: https://github.com/apstndb/zetasql-format-server