Photo de Reza Rostampisheh sur Unsplash
Dans l'univers des parsers, le nec plus ultra de l'analyse de texte, c'est un parser capable de construire un arbre syntaxique abstrait (AST) à partir de votre texte. Le principal intérêt d'un AST, c'est qu'il produit une chaîne JSON contenant la classification des informations analysées. C'est extrêmement utile et pratique pour développer des services par-dessus. Et lorsque le texte d'entrée est une requête SQL, ça l'est encore davantage.
Tout éditeur SQL digne de ce nom utilise un parser. superQuery s'appuie sur un parser nommé pegJs, un système en JavaScript enrichi par l'équipe désormais rachetée par DoiT International afin de prendre également en charge l'essentiel de la syntaxe de Google BigQuery.
À propos de zetaSQL
Début 2019, Google a publié en open source le parser AST baptisé zetaSQL, utilisé en production pour le parsing et le formatage des requêtes dans Google BigQuery et Cloud Spanner. Le dépôt est disponible ici. zetaSQL se compile avec bazel et se compose principalement de code C++, même si une implémentation Java est également proposée.
En se plongeant dans le code, on découvre que le parser offre de nombreuses fonctionnalités, parmi lesquelles :
- Le formatage d'une requête SQL (sql_formatter.h)
- L'analyse d'une requête SQL (analyzer.h)
- La détection des erreurs de syntaxe avec retour de l'erreur, de la ligne et de la colonne (parse_helpers.h)
En parcourant le dépôt, on constate vite qu'il paraît simple à compiler. Pour vous faire gagner du temps, je précise que le fichier .bazelrc est crucial : il fixe la version du compilateur C++ au niveau requis, en cohérence avec les autres logiciels Google. Il est donc indispensable de l'avoir sous la main pendant la compilation.
Par ailleurs, le dépôt zetaSQL de base ne fournit pas (encore) de Dockerfile permettant de compiler la dernière version de zetaSQL. Je le mets à disposition ici, basé sur Ubuntu 18.04 et la dernière version de bazel.
Mon implémentation (zetasql-analyzer-server) répond au point 3 ci-dessus, c'est-à-dire la détection des erreurs de syntaxe. Elle s'inspire d'une implémentation Docker réalisée par apstndb et baptisée zetasql-format-server (qui répond au point 2). En coulisses, il s'agit d'un serveur Go qui encapsule l'API de formatage (ou d'analyse) de zetaSQL et expose un endpoint via Google Cloud Run.
Exemples
Cas simple
Voici un exemple de sortie de l'endpoint d'analyse pour une requête erronée SELEC 1 (le T manque) :
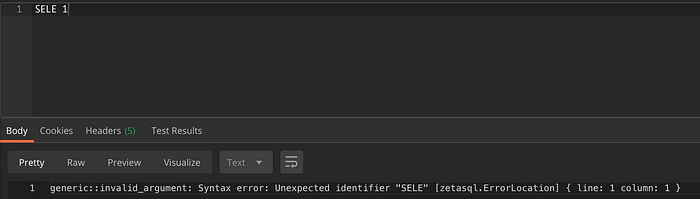
L'emplacement de l'erreur, la ligne, la colonne et le message sont renvoyés pour une requête simple.
Cas plus complexe
Dans l'exemple ci-dessous, le second niveau imbriqué de la requête omet le mot SELECT. On voit bien que le parser signale cette information.
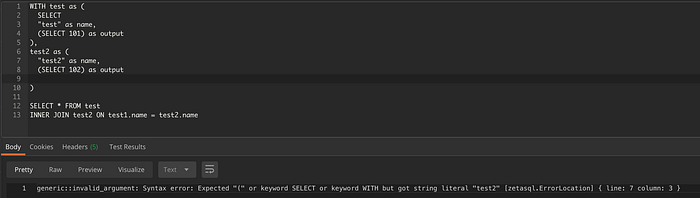
Localisation de l'erreur pour une requête un peu plus complexe.
Et côté vitesse et performances ?
D'après le nombre limité de tests que j'ai menés, la plupart des réponses (même pour des requêtes de plus de 600 lignes) restent sous la seconde, avec une moyenne de 300 ms.
Voici les graphiques de temps de réponse pour les deux exemples, depuis mon ordinateur portable, avec une connexion Internet haut débit :
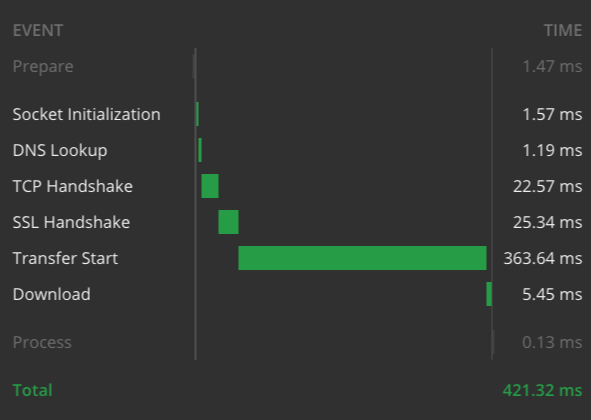
Temps de traitement pour SELE 1
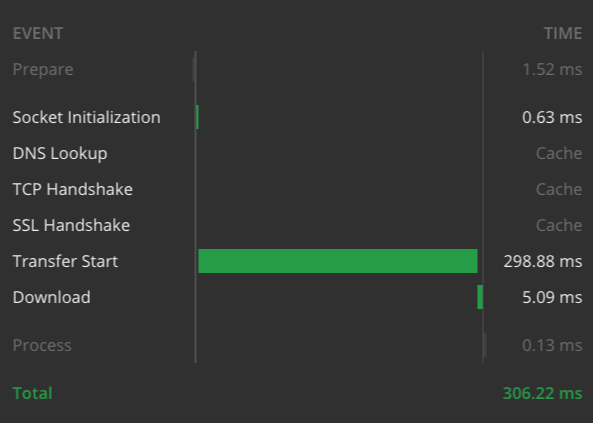
Temps de traitement pour l'exemple plus complexe ci-dessus.
La stack qui rend possible ce parsing à haute vitesse repose sur une image de conteneur distroless (https://github.com/GoogleContainerTools/distroless) et une infrastructure serverless (Cloud Run) avec le C++ comme langage d'entrée.
Installation et utilisation
Pour l'installer, n'hésitez pas à consulter le fichier README ici. Dites-moi où je peux vous aider à le mettre en route.
Une fois l'endpoint créé dans Cloud Run, vous pouvez en obtenir des informations via une commande curl :
curl -X POST -H 'Content-type: application/text' --data 'SLECT 1, ' https://<votre endpoint ici>
Pour finir
Bon parsing !
Références
- zetasql-analyzer-server : https://github.com/ebendutoit/zetasql-analyzer-server
- zetaSQL : https://github.com/google/zetasql
- zetasql-format-server : https://github.com/apstndb/zetasql-format-server