Mehr Produktivität für Enterprise-Entwicklerteams: sichere, selbst gehostete KI-Coding-Assistenten auf Amazon SageMaker

Einführung und Kontext
KI-gestütztes Coding hat die Softwareentwicklung grundlegend verändert: Routineaufgaben werden automatisiert, die Genauigkeit steigt, und Engineers können sich stärker auf komplexe Problemstellungen konzentrieren. Unternehmen entscheiden sich zunehmend dafür, ihre LLM-Modelle in privaten Umgebungen zu betreiben – vor allem, um sensibles geistiges Eigentum und proprietären Code zu schützen, regulatorische Vorgaben einzuhalten und Anpassungen an spezifische Unternehmensanforderungen zu ermöglichen.
Überblick
In diesem Blogbeitrag hosten wir ein Marketplace-LLM in Ihrer Amazon SageMaker-Umgebung. Dafür nutzen wir ein Modell aus Amazon SageMaker Jumpstart. Die meisten KI-gestützten autonomen Coding-Agenten – etwa Roo Code, Cline und Continue.dev – unterstützen offene Protokolle wie OpenAI. LiteLLM eignet sich daher hervorragend als OpenAI-Proxy für unsere SageMaker-Inferenz.
Warum selbst gehostete LLM-Modelle?
Selbst gehostete LLM-Modelle bieten Unternehmen mehrere Vorteile:
- Datenschutz und Sicherheit: Internes Hosting schützt sensible Daten, Quellcode und proprietäre Algorithmen.
- Anpassbarkeit: KI-Modelle lassen sich auf eigene Coding-Stile, Geschäftslogik und regulatorische Anforderungen zuschneiden.
- Kostenoptimierung: Effizientes Ressourcenmanagement senkt die Kosten gegenüber KI-Diensten von Drittanbietern.
Produktivität und Anwendungsbeispiele
KI-gestütztes Coding steigert Produktivität und Effizienz in der Softwareentwicklung – zum Beispiel durch:
- Automatisierte Generierung von Boilerplate-Code
- Unterstützung beim Debugging und beim Aufspüren von Performance-Engpässen
- Bessere Code-Review-Prozesse
- Schnelleres Onboarding und Training neuer Engineers
Wichtige Aspekte
- Sicherheit und Compliance: Sorgfältige Konfiguration von IAM-Rollen, Verschlüsselung und Zugriffskontrollen.
- Kostenmanagement: Regelmäßiges Monitoring und Optimierung der Infrastrukturnutzung.
- Performance-Optimierung: Wahl geeigneter SageMaker-Instanztypen passend zu den Anforderungen Ihrer workloads.
Die Rolle von Amazon SageMaker beim Self-Hosting
Amazon SageMaker macht Self-Hosting deutlich einfacher und bietet:
- Zugriff auf eine breite Auswahl vortrainierter LLMs über SageMaker Jumpstart.
- Skalierbares, sicheres und leistungsfähiges Infrastrukturmanagement.
- Nahtlose Integration in AWS-Services und damit weniger operativen Aufwand.
Vorteile von Fargate
AWS Fargate für den Betrieb des LiteLLM-Proxys senkt den operativen Aufwand spürbar:
- Kein manuelles Infrastrukturmanagement und keine Serverwartung erforderlich.
- Automatisches Skalieren und hohe Verfügbarkeit sorgen für konstante Performance.
- Weniger Komplexität beim Sicherheitsmanagement durch Isolation und AWS-managed Umgebungen.
Architektur
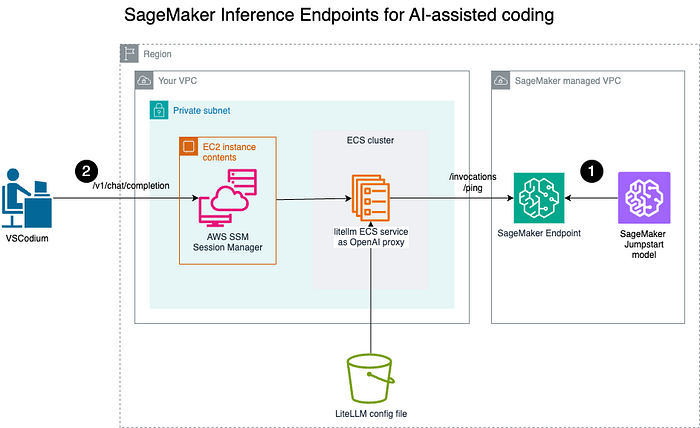
- Modell auf einem Amazon SageMaker Endpoint für Echtzeit-Inferenz bereitstellen.
- Engineers, die in lokalen IDEs wie VSCodium mit KI-gestützten Coding-Assistenten arbeiten, verbinden sich über einen abgesicherten Kanal mit dem LiteLLM OpenAI-Proxy und rufen diesen auf.
Die Schritte im Überblick
Zuerst stellen wir ein vortrainiertes Modell als Amazon SageMaker Endpoint bereit. Anschließend betreiben wir einen OpenAI-Proxy mit LiteLLM als ECS-Service.
Engineers können sich nun mit dem OpenAI-Proxy verbinden. Der Einfachheit halber erfolgt die Verbindung in diesem Tutorial über die öffentliche IP-Adresse des ECS-Tasks.
Schritt 1: Vortrainiertes Modell auf Amazon SageMaker bereitstellen
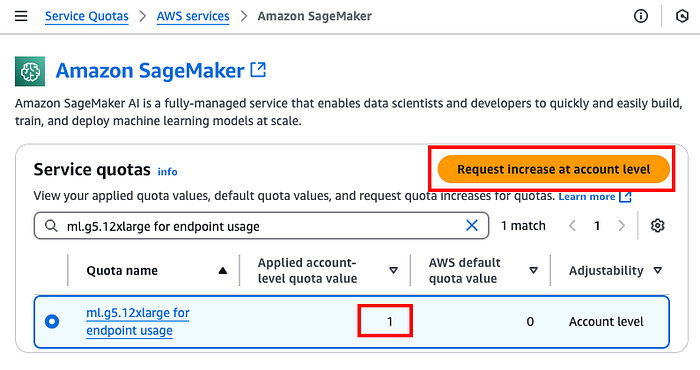
Voraussetzung: Bevor Sie einen Amazon SageMaker Endpoint provisionieren, sollten Sie sicherstellen, dass Ihr Konto ein Kontingent von mindestens 1 für die geplante Endpoint-Instanz hat. Prüfen lässt sich das unter https://console.aws.amazon.com/servicequotas/home/services/sagemaker/quotas. Wir verwenden ml.g5.12xlarge, Sie benötigen also mindestens 1 für Ihr Konto. Andernfalls können Sie über "Request increase at account level" eine Erhöhung beantragen.
- Falls Sie noch keine Amazon SageMaker Execution Role haben (https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html), legen Sie eine IAM-Rolle für die SageMaker-Ausführung an – nennen wir sie
AmazonSageMaker-Endpoints-ExecutionRole. Hängen Sie die Managed Policyarn:aws:iam::aws:policy/AmazonSageMakerFullAccesssowie die folgende Trust Policy fürsagemaker.amazonaws.coman:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "sagemaker.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
2. Identifizieren Sie die VPC, die privaten Subnets und den bereitzustellenden Amazon SageMaker Endpoint.
3. Legen Sie einen S3 VPC Endpoint an, damit der Amazon SageMaker Endpoint das vortrainierte Modell aus dem S3 Bucket laden kann:
aws ec2 create-vpc-endpoint \
--private-dns-enabled \
--vpc-id <vpc-id> \
--service-name com.amazonaws.<region>.s3 \
--route-table-ids <route-table-id>
Wenn der Befehl erfolgreich durchläuft, sollte die Routing-Tabelle den VPC Endpoint zusammen mit dem NAT enthalten, beispielsweise:
% aws ec2 describe-route-tables --route-table-ids <route-table-id> --query 'RouteTables[*].Routes'
[\
[\
{\
"DestinationCidrBlock": "10.0.0.0/23",\
"GatewayId": "local",\
"Origin": "CreateRouteTable",\
"State": "active"\
},\
{\
"DestinationCidrBlock": "0.0.0.0/0",\
"NatGatewayId": "nat-<NAT GW ID>",\
"Origin": "CreateRoute",\
"State": "active"\
},\
{\
"DestinationPrefixListId": "pl-63a5400a",\
"GatewayId": "vpce-<VPCE ID>",\
"Origin": "CreateRoute",\
"State": "active"\
}\
]\
]
3. Legen Sie eine Security Group ecs-sagemaker-endpoint mit folgenden Regeln an:
Inbound-Regel:
- Protokoll: HTTPS (443)
- Quelle: Die Security Group selbst (selbstreferenzierend)
Outbound-Regel:
- Protokoll: HTTPS (443)
- Ziel: S3 VPC Endpoint
Hinweis: Aus Sicherheitsgründen sollte die Default Security Group weder Inbound- noch Outbound-Regeln zulassen. Details finden Sie unter https://docs.aws.amazon.com/securityhub/latest/userguide/ec2-controls.html#ec2-2
- Wählen Sie Ihr Modell aus Amazon SageMaker Jumpstart aus (z. B. Qwen2, Mistral, Llama 3.2). Eine Liste der vortrainierten Modelle finden Sie unter https://sagemaker.readthedocs.io/en/stable/doc_utils/pretrainedmodels.html.
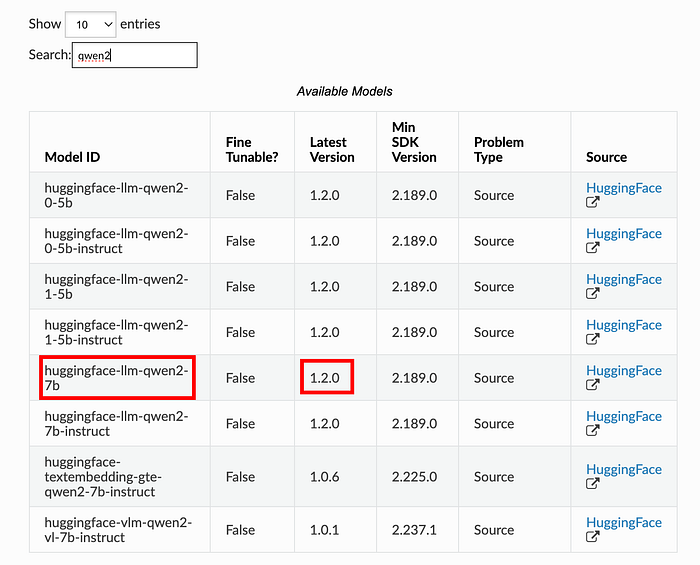
2. Notieren Sie sich Modell-ID und Version, um ein Amazon SageMaker Modell zu erstellen:
from sagemaker.jumpstart.model import JumpStartModel
jump_start_model = JumpStartModel(
model_id="huggingface-llm-qwen2-7b-instruct",
model_version="1.2.0",
role="AmazonSageMaker-Endpoints-ExecutionRole",# oder die entsprechende Amazon SageMaker Execution Role
vpc_config={
"Subnets": [ "Private Subnets" ],
"SecurityGroupIds": [ "ecs-sagemaker-endpoint" ]
},
)
jump_start_model.deploy(
initial_instance_count=1,
instance_type="ml.g5.12xlarge",
accept_eula=True,
endpoint_name="jumpstart-model"
)
Prüfen Sie den Status Ihres Endpoints per AWS CLI:
% aws sagemaker list-endpoints
{
"Endpoints": [\
{\
"EndpointName": "jumpstart-model",\
"EndpointArn": "arn:aws:sagemaker:<AWS REGION>:<AWS ACCOUNT ID>:endpoint/jumpstart-model",\
"CreationTime": "<CreationTime>",\
"LastModifiedTime": "<LastModifiedTime>",\
"EndpointStatus": "InService"\
}\
]
}
Schritt 2: OpenAI-Proxy mit Amazon Elastic Container Service (ECS) bereitstellen
Details zur Konfiguration des LiteLLM-Proxys finden Sie unter https://docs.litellm.ai/docs/proxy/configs
- Erstellen Sie eine YAML-Konfigurationsdatei (
config.yaml), die den SageMaker Endpoint einbindet:
model_list:
- model_name: jumpstart-model
litellm_params:
model: sagemaker/jumpstart-model # nutzt den sagemaker-Namespace und verweist auf den Amazon SageMaker Endpoint-Namen
2. Laden Sie die config.yaml in einen S3 Bucket hoch.
3. Definieren Sie Ihren ECS-Container (container-definition.json):
[\
{\
"name": "litellm",\
"image": "ghcr.io/berriai/litellm:main-latest",\
"cpu": 0,\
"portMappings": [\
{\
"containerPort": 4000,\
"hostPort": 4000,\
"protocol": "tcp"\
}\
],\
"essential": true,\
"environment": [\
{\
"name": "LITELLM_CONFIG_BUCKET_OBJECT_KEY",\
"value": "config.yaml"\
},\
{\
"name": "LITELLM_CONFIG_BUCKET_NAME",\
"value": "<S3 bucket>"\
},\
{\
"name": "LITELLM_MASTER_KEY",\
"value": "<API key to call the proxy, such as sk-123123>"\
}\
],\
"mountPoints": [],\
"volumesFrom": [],\
"logConfiguration": {\
"logDriver": "awslogs",\
"options": {\
"awslogs-group": "/ecs/litellm",\
"awslogs-create-group": "true",\
"awslogs-region": "us-east-1",\
"awslogs-stream-prefix": "ecs"\
}\
},\
"systemControls": []\
}\
]
3. Erstellen Sie eine IAM-Rolle für den ECS Task nach dem Least-Privilege-Prinzip:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Sid": "Statement1",\
"Effect": "Allow",\
"Action": [\
"sagemaker:InvokeEndpoint"\
],\
"Resource": [\
"arn:aws:sagemaker:<AWS REGION>:<AWS ACCOUNT ID>:endpoint/jumpstart-model"\
]\
}\
]
}
4. Registrieren Sie die ECS Task Definition:
aws ecs register-task-definition \
--family litellm-task \
--requires-compatibilities FARGATE \
--cpu 1024 \
--memory 2048 \
--network-mode awsvpc \
--runtime-platform cpuArchitecture=ARM64 \
--task-role-arn "<ECS Task Role ARN>" \
--container-definitions file://./container-definition.json \
--region $REGION
Bevor wir den ECS-Service erstellen, brauchen wir folgende Einstellungen:
- Die Subnet-ID, in der die ECS-Tasks laufen sollen.
- Die Security Group, die den ECS-Tasks die Verbindung zu den Amazon SageMaker Endpoints erlaubt. In diesem Artikel haben wir sie als
ecs-sagemaker-endpointangelegt.
Außerdem benötigen wir eine Security Group, damit die ECS-Tasks das LiteLLM-Container-Image herunterladen können:
Outbound-Regel:
- Protokoll: HTTPS (443)
- Ziel: 0.0.0.0/0
- Beschreibung: Image-Download für ECS-Tasks
Eine weitere Security Group für die Verbindung zwischen Proxy und ECS-Tasks:
Inbound-Regel:
- Protokoll: LiteLLM-Port (4000)
- Quelle: Die Security Group selbst (selbstreferenzierend)
Outbound-Regel:
- Protokoll: LiteLLM-Port (4000)
- Ziel: Dieselbe Security Group (selbstreferenzierend)
- Beschreibung: Proxy und ECS-Tasks
Erstellen Sie einen ECS-Service auf Basis der Task Definition mit der Subnet-ID:
aws ecs create-service \
--cluster litellm-cluster \
--service-name litellm-service \
--task-definition litellm-task:1 \
--desired-count 1 \
--launch-type FARGATE \
--platform-version LATEST \
--network-configuration "awsvpcConfiguration={subnets=[<SUBNET ID>],assignPublicIp=DISABLED},securityGroups=[<sg-xxx for ecs-sagemaker-endpoint>,<sg-xxx for ecs-443-outbound>,<sg-xxx for proxy-ecs-4000>]" \
--region $REGION
Hinweis: Aus Sicherheitsgründen sollten ECS-Services keine öffentlichen IP-Adressen haben. Details finden Sie unter https://docs.aws.amazon.com/securityhub/latest/userguide/ecs-controls.html#ecs- 2
Ermitteln Sie die private IP-Adresse des ECS-Tasks:
CLUSTER="litellm-cluster"
# Schritt 1: ECS Task ID abrufen
TASK=$(aws ecs list-tasks --cluster ${CLUSTER} --query "taskArns[0]" --output text)
# Schritt 2: ENI aus dem ECS Task ermitteln
ENI=$(aws ecs describe-tasks --cluster $CLUSTER --tasks $TASK --query "tasks[0].attachments[0].details[?name=='networkInterfaceId'].value | [0]" --output text)
# Schritt 3: private IP-Adresse des ENI abrufen
aws ec2 describe-network-interfaces --network-interface-ids $ENI --query 'NetworkInterfaces[0].PrivateIpAddress' --output text
Notieren Sie sich die private IP-Adresse des Tasks – sie wird für die Proxy-Konfiguration benötigt.
Schritt 3: Proxy einrichten
In diesem Beispiel richten wir eine EC2-Instanz im selben privaten Subnet ein, die über Amazon Systems Manager verwaltet wird. So können wir uns per SSM-Portforwarding mit dem LiteLLM-Proxy verbinden.
- Erstellen Sie eine neue Security Group
ssm-outbound-sg, die ausgehende Verbindungen auf Port 443 erlaubt:
Outbound-Regel:
- Protokoll: HTTPS (443)
- Ziel: 0.0.0.0/0
- Beschreibung: Verbindungen zu SSM-Endpoints
- Erstellen Sie drei VPC Endpoints, damit die EC2-Instanz im privaten Subnet die SSM-Endpoints erreicht:
# Systems Manager Endpoint
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ssm \
--subnet-ids <private subnet-id, in dem die EC2 bereitgestellt wird> \
--security-group-ids <security-group-id, mit der sich die EC2 verbindet, z. B. ec2-ssm>
# SSM Messages Endpoint
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ssmmessages \
--subnet-ids <private subnet-id, in dem die EC2 bereitgestellt wird> \
--security-group-ids <security-group-id, mit der sich die EC2 verbindet, z. B. ec2-ssm>
# EC2 Messages Endpoint
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ec2messages \
--subnet-ids <private subnet-id, in dem die EC2 bereitgestellt wird> \
--security-group-ids <security-group-id, mit der sich die EC2 verbindet, z. B. ec2-ssm>
- Starten Sie eine Graviton-EC2-Instanz, etwa eine t4g.small mit Amazon Linux, im privaten Subnet.
- Hängen Sie der EC2-Instanz folgende Security Groups an:
- Litellm-proxy, die ausgehende Verbindungen auf Port 4000 zur selben Security Group erlaubt, damit sich diese Proxy-EC2 mit dem ECS-Task verbinden kann.
ssm-outbound-sg, damit die EC2 die SSM-Endpoints erreicht.
3. Sobald die EC2-Instanz bereit ist, verbinden Sie sich über den SSM Agent mit Portforwarding:
aws ssm start-session \
--target <EC2 instance ID, z. B. i-012345> \
--document-name AWS-StartPortForwardingSessionToRemoteHost \
--parameters host="<Private IP des ECS-Tasks>",portNumber="4000",localPortNumber="4000"
Schritt 4: KI-gestützte Coding-Umgebung konfigurieren
Installieren Sie Continue.dev aus dem Marketplace, etwa über https://open-vsx.org/extension/Continue/continue, und öffnen Sie die lokale Konfiguration.
Tragen Sie die neu erstellten ECS-Tasks als Modell-Provider ein:
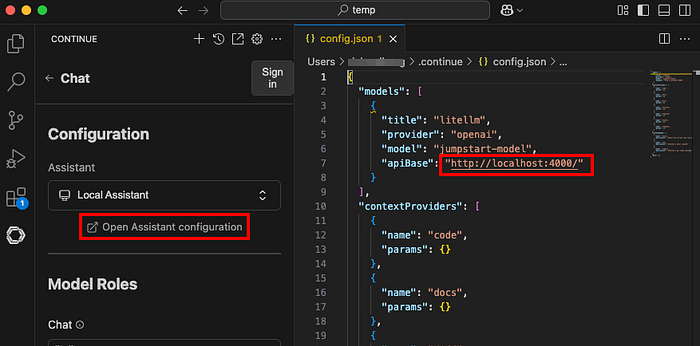
"models": [\
{\
"title": "litellm",\
"provider": "openai",\
"model": "jumpstart-model",\
"apiBase": "http://localhost:4000/",\
}\
],
Sobald die Konfiguration aktualisiert ist, können Sie eine Datei anhängen, mit der die KI Sie unterstützt.

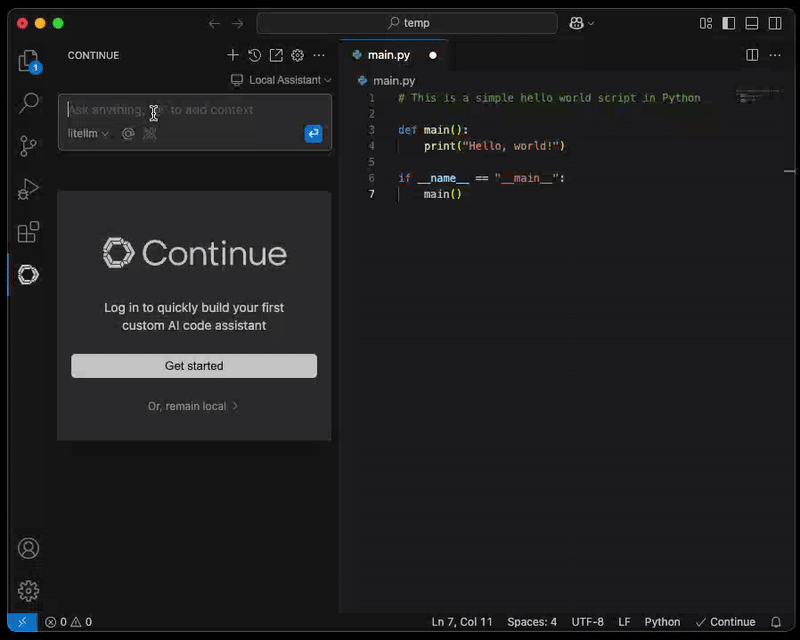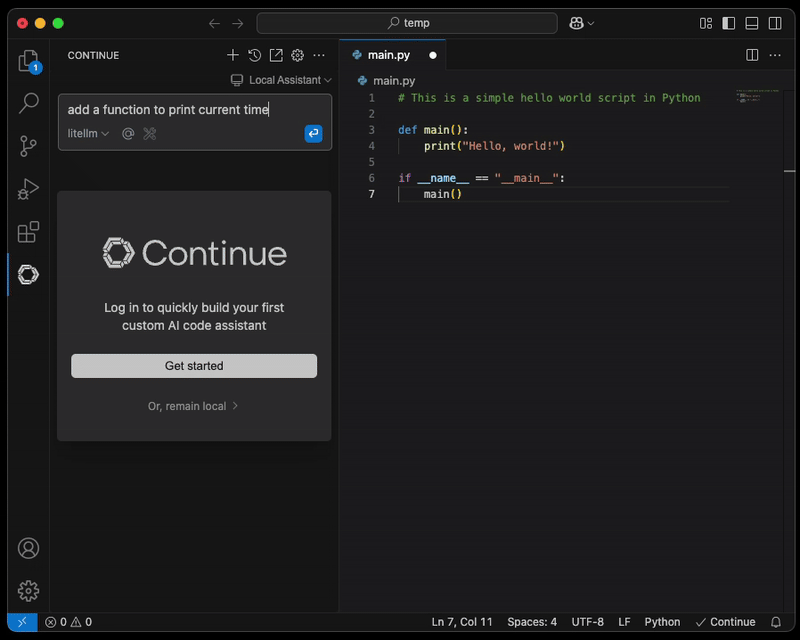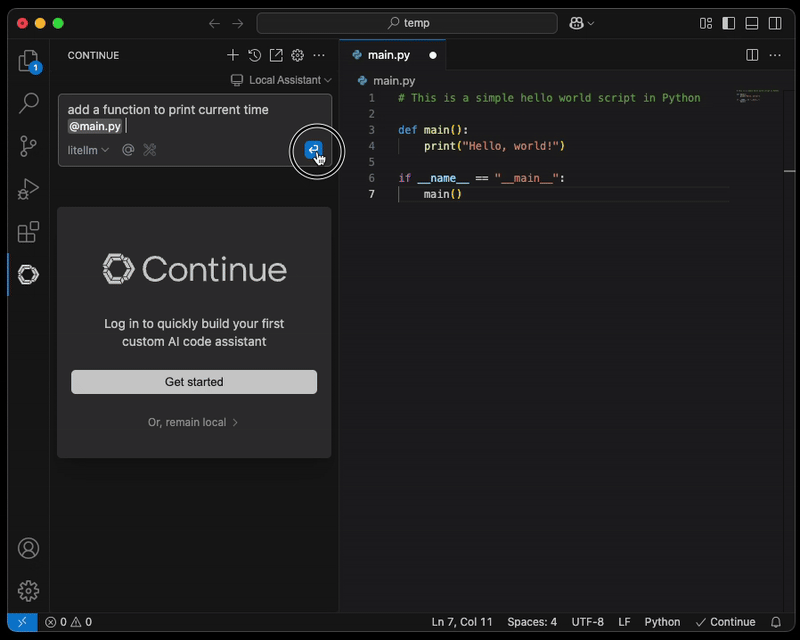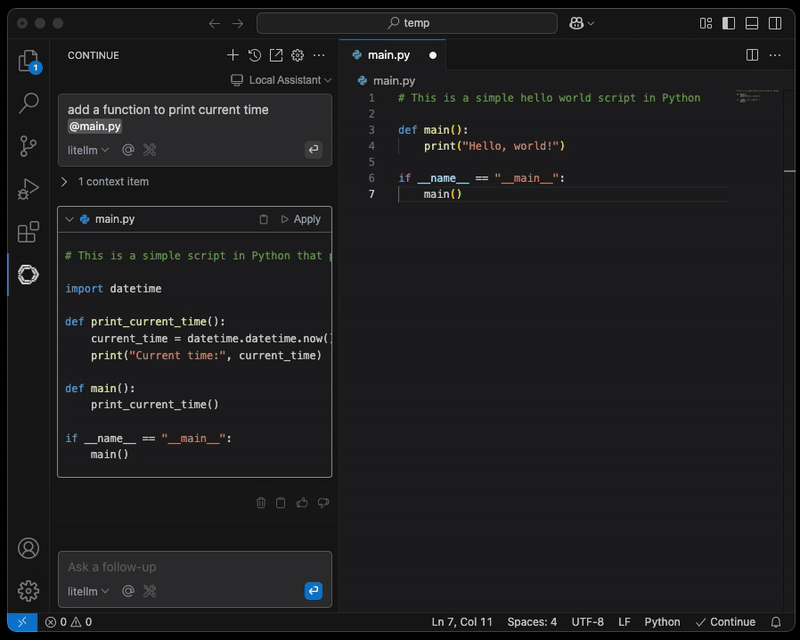
HINWEIS: Eine abgesicherte Verbindung vom Laptop des Engineers zum LiteLLM-Proxy-Endpoint, etwa über AWS Client VPN, ist dringend zu empfehlen.
Fazit und nächste Schritte
Wer das eigene LLM-Modell auf Amazon SageMaker hostet, gewinnt volle Kontrolle, soliden Datenschutz und spürbare Produktivitätsgewinne in der Softwareentwicklung. DoiT International begleitet Ihr Unternehmen kompetent bei Design und Umsetzung selbst gehosteter, sicherer und kosteneffizienter KI-Lösungen – passgenau auf Ihre Anforderungen zugeschnitten.
Bereit, Ihre Coding-Workflows sicher auf das nächste Level zu heben? Sprechen Sie mit DoiT International über Ihre Enterprise-KI-Strategie und sorgen Sie für konsequenten Datenschutz und Compliance.