Boostez la productivité de vos développeurs en entreprise avec des assistants de coding IA sécurisés et auto-hébergés sur Amazon SageMaker

Introduction et contexte
Le coding assisté par IA a profondément transformé le développement logiciel : il automatise les tâches routinières, gagne en précision et libère les développeurs pour qu'ils se concentrent sur la résolution de problèmes complexes. Les entreprises privilégient de plus en plus l'hébergement de leurs LLM dans des environnements privés, principalement pour protéger leur propriété intellectuelle sensible et leur code propriétaire, respecter les réglementations sur les données et permettre une personnalisation adaptée à leurs besoins spécifiques.
Vue d'ensemble
Dans cet article, nous allons héberger un LLM du marketplace dans votre environnement Amazon SageMaker, à partir d'un modèle issu d'Amazon SageMaker Jumpstart. La plupart des agents de coding autonomes propulsés par IA, comme Roo Code, Cline et Continue.dev, prennent en charge des protocoles ouverts tels qu'OpenAI, ce qui fait de LiteLLM un proxy OpenAI idéal pour notre inférence SageMaker.
Pourquoi auto-héberger ses LLM ?
L'auto-hébergement des LLM apporte aux entreprises plusieurs bénéfices :
- Confidentialité et sécurité des données : un hébergement interne garantit la sécurité des données sensibles, du code source et des algorithmes propriétaires.
- Personnalisation : adaptation des modèles d'IA aux styles de codage spécifiques, à la logique métier et aux exigences réglementaires.
- Optimisation des coûts : une gestion efficace des ressources réduit les coûts comparé aux services d'IA tiers.
Productivité et exemples d'usage
Le coding assisté par IA renforce la productivité et l'efficacité tout au long du cycle de développement, par exemple :
- Automatisation de la génération de code boilerplate
- Aide au débogage et à l'identification des goulots d'étranglement de performance
- Amélioration des processus de revue de code
- Accélération de l'onboarding et de la formation des nouveaux développeurs
Points de vigilance
- Sécurité et conformité : configuration appropriée des rôles IAM, du chiffrement et des contrôles d'accès.
- Maîtrise des coûts : suivi régulier et optimisation de l'utilisation de l'infrastructure.
- Optimisation des performances : choix des types d'instances SageMaker adaptés aux exigences spécifiques des workloads.
Le rôle d'Amazon SageMaker dans l'auto-hébergement
Amazon SageMaker simplifie l'auto-hébergement et offre :
- Un accès à un large éventail de LLM pré-entraînés via SageMaker Jumpstart.
- Une gestion d'infrastructure scalable, sécurisée et performante.
- Une intégration fluide avec les services AWS, qui réduit la complexité opérationnelle.
Les atouts de Fargate
Recourir à AWS Fargate pour déployer le proxy LiteLLM allège considérablement la charge opérationnelle :
- Plus de gestion manuelle de l'infrastructure ni de maintenance des serveurs.
- Scalabilité et disponibilité gérées automatiquement, pour des performances constantes.
- Complexité de la sécurité réduite grâce à l'isolation et aux environnements gérés par AWS.
Architecture
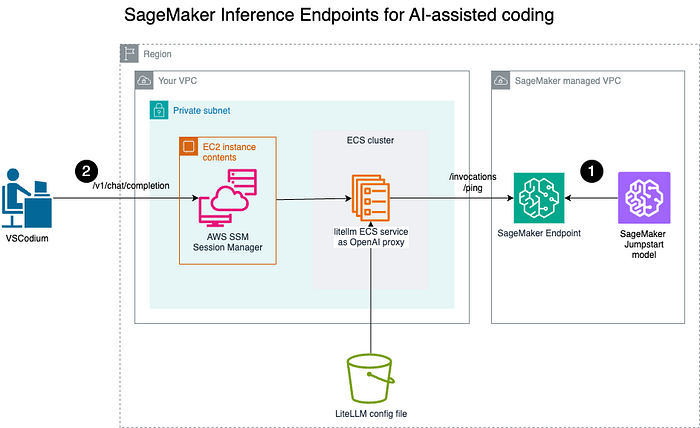
- Déployez un modèle sur l'endpoint Amazon SageMaker pour l'inférence en temps réel ;
- Les Engineers utilisant des assistants de coding propulsés par IA dans leur IDE local, par exemple VSCodium, se connectent en toute sécurité au proxy OpenAI LiteLLM via un canal sécurisé pour invoquer ce dernier.
Aperçu des étapes
Nous commencerons par déployer un modèle pré-entraîné en tant qu'endpoint Amazon SageMaker. Nous lancerons ensuite un proxy OpenAI avec LiteLLM sous forme de service ECS.
Les développeurs pourront alors se connecter au proxy OpenAI. Par souci de simplicité, ce tutoriel passera par l'IP publique de la tâche ECS.
Étape 1 : déployer un modèle pré-entraîné sur Amazon SageMaker
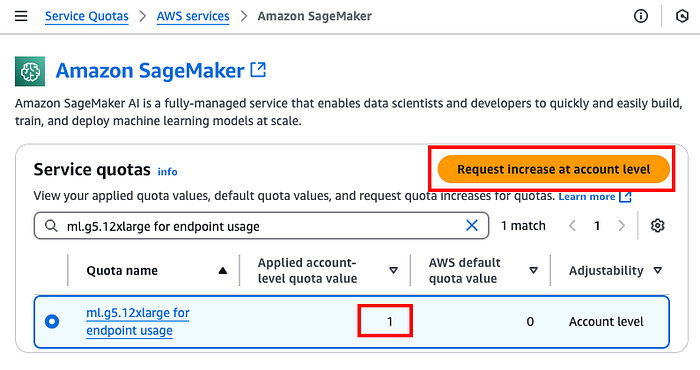
Prérequis : avant de provisionner un endpoint Amazon SageMaker, assurez-vous que votre compte dispose d'un quota d'au moins 1 pour le type d'instance utilisé. Vous pouvez le vérifier sur https://console.aws.amazon.com/servicequotas/home/services/sagemaker/quotas. Nous utiliserons ml.g5.12xlarge ; il vous faudra donc au moins 1 sur votre compte. À défaut, soumettez une demande en sélectionnant Request increase at account level.
- Si vous ne disposez pas déjà d'un rôle d'exécution Amazon SageMaker (https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html), créez un rôle IAM pour l'exécution SageMaker, que nous appellerons
AmazonSageMaker-Endpoints-ExecutionRole, attachez-y la policy managéearn:aws:iam::aws:policy/AmazonSageMakerFullAccesset la trust policy poursagemaker.amazonaws.com:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "sagemaker.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
2. Identifiez le VPC, les sous-réseaux privés et l'endpoint Amazon SageMaker à déployer.
3. Créez un VPC endpoint S3 pour que l'endpoint Amazon SageMaker puisse télécharger le modèle pré-entraîné depuis le bucket S3 :
aws ec2 create-vpc-endpoint \
--private-dns-enabled \
--vpc-id <vpc-id> \
--service-name com.amazonaws.<region>.s3 \
--route-table-ids <route-table-id>
Si la commande s'exécute correctement, la table de routage doit contenir le VPC Endpoint ainsi que la NAT, par exemple :
% aws ec2 describe-route-tables --route-table-ids <route-table-id> --query 'RouteTables[*].Routes'
[\
[\
{\
"DestinationCidrBlock": "10.0.0.0/23",\
"GatewayId": "local",\
"Origin": "CreateRouteTable",\
"State": "active"\
},\
{\
"DestinationCidrBlock": "0.0.0.0/0",\
"NatGatewayId": "nat-<NAT GW ID>",\
"Origin": "CreateRoute",\
"State": "active"\
},\
{\
"DestinationPrefixListId": "pl-63a5400a",\
"GatewayId": "vpce-<VPCE ID>",\
"Origin": "CreateRoute",\
"State": "active"\
}\
]\
]
3. Créez un Security Group ecs-sagemaker-endpoint avec les règles suivantes :
Règle entrante :
- Protocole : HTTPS (443)
- Source : le security group lui-même (auto-référentiel)
Règle sortante :
- Protocole : HTTPS (443)
- Destination : VPC endpoint S3
Note : par bonne pratique de cybersécurité, le Security Group par défaut ne devrait autoriser aucune règle entrante ou sortante. Détails sur https://docs.aws.amazon.com/securityhub/latest/userguide/ec2-controls.html#ec2-2
- Identifiez votre modèle dans Amazon SageMaker Jumpstart (par exemple Qwen2, Mistral, Llama 3.2). La liste des modèles pré-entraînés est disponible sur https://sagemaker.readthedocs.io/en/stable/doc_utils/pretrainedmodels.html.
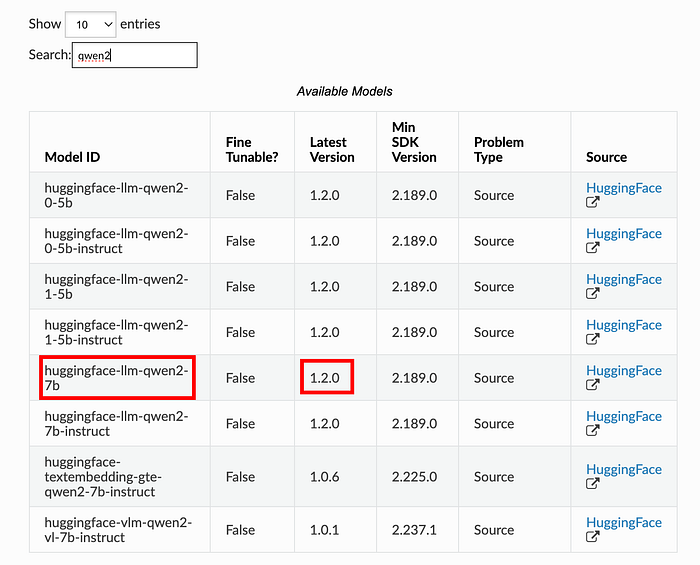
2. Notez l'ID et la version du modèle pour créer un modèle Amazon SageMaker :
from sagemaker.jumpstart.model import JumpStartModel
jump_start_model = JumpStartModel(
model_id="huggingface-llm-qwen2-7b-instruct",
model_version="1.2.0",
role="AmazonSageMaker-Endpoints-ExecutionRole",# ou le rôle d'exécution Amazon SageMaker concerné
vpc_config={
"Subnets": [ "Private Subnets" ],
"SecurityGroupIds": [ "ecs-sagemaker-endpoint" ]
},
)
jump_start_model.deploy(
initial_instance_count=1,
instance_type="ml.g5.12xlarge",
accept_eula=True,
endpoint_name="jumpstart-model"
)
Vérifiez l'état de votre endpoint avec l'AWS CLI :
% aws sagemaker list-endpoints
{
"Endpoints": [\
{\
"EndpointName": "jumpstart-model",\
"EndpointArn": "arn:aws:sagemaker:<AWS REGION>:<AWS ACCOUNT ID>:endpoint/jumpstart-model",\
"CreationTime": "<CreationTime>",\
"LastModifiedTime": "<LastModifiedTime>",\
"EndpointStatus": "InService"\
}\
]
}
Étape 2 : déployer le proxy OpenAI sur Amazon Elastic Container Service (ECS)
Les détails de configuration du proxy LiteLLM sont disponibles sur https://docs.litellm.ai/docs/proxy/configs
- Créez un fichier de configuration YAML (
config.yaml) pour mapper l'endpoint SageMaker :
model_list:
- model_name: jumpstart-model
litellm_params:
model: sagemaker/jumpstart-model # utilise le namespace sagemaker et pointe vers le nom de l'endpoint Amazon SageMaker
2. Téléversez config.yaml dans un bucket S3.
3. Définissez votre conteneur ECS (container-definition.json) :
[\
{\
"name": "litellm",\
"image": "ghcr.io/berriai/litellm:main-latest",\
"cpu": 0,\
"portMappings": [\
{\
"containerPort": 4000,\
"hostPort": 4000,\
"protocol": "tcp"\
}\
],\
"essential": true,\
"environment": [\
{\
"name": "LITELLM_CONFIG_BUCKET_OBJECT_KEY",\
"value": "config.yaml"\
},\
{\
"name": "LITELLM_CONFIG_BUCKET_NAME",\
"value": "<S3 bucket>"\
},\
{\
"name": "LITELLM_MASTER_KEY",\
"value": "<Clé API pour appeler le proxy, par exemple sk-123123>"\
}\
],\
"mountPoints": [],\
"volumesFrom": [],\
"logConfiguration": {\
"logDriver": "awslogs",\
"options": {\
"awslogs-group": "/ecs/litellm",\
"awslogs-create-group": "true",\
"awslogs-region": "us-east-1",\
"awslogs-stream-prefix": "ecs"\
}\
},\
"systemControls": []\
}\
]
3. Créez un rôle IAM pour le rôle de tâche ECS, en appliquant le principe du moindre privilège :
{
"Version": "2012-10-17",
"Statement": [\
{\
"Sid": "Statement1",\
"Effect": "Allow",\
"Action": [\
"sagemaker:InvokeEndpoint"\
],\
"Resource": [\
"arn:aws:sagemaker:<AWS REGION>:<AWS ACCOUNT ID>:endpoint/jumpstart-model"\
]\
}\
]
}
4. Enregistrez la définition de tâche ECS :
aws ecs register-task-definition \
--family litellm-task \
--requires-compatibilities FARGATE \
--cpu 1024 \
--memory 2048 \
--network-mode awsvpc \
--runtime-platform cpuArchitecture=ARM64 \
--task-role-arn "<ECS Task Role ARN>" \
--container-definitions file://./container-definition.json \
--region $REGION
Avant de créer le service ECS, prévoyez les paramètres suivants :
- L'ID du sous-réseau dans lequel les tâches ECS s'exécuteront.
- Le Security Group autorisant les tâches ECS à se connecter aux endpoints Amazon SageMaker. Dans cet article, il a été créé sous le nom
ecs-sagemaker-endpoint.
Créez également un security group pour permettre aux tâches ECS de télécharger l'image du conteneur LiteLLM :
Règle sortante :
- Protocole : HTTPS (443)
- Destination : 0.0.0.0/0
- Description : téléchargement de l'image des tâches ECS
Un autre Security Group, pour la liaison entre le proxy et les tâches ECS :
Règle entrante :
- Protocole : port LiteLLM (4000)
- Source : le security group lui-même (auto-référentiel)
Règle sortante :
- Protocole : port LiteLLM (4000)
- Destination : ce même security group (auto-référentiel)
- Description : proxy et tâches ECS
Créez un service ECS associé à la définition de tâche et à l'ID du sous-réseau :
aws ecs create-service \
--cluster litellm-cluster \
--service-name litellm-service \
--task-definition litellm-task:1 \
--desired-count 1 \
--launch-type FARGATE \
--platform-version LATEST \
--network-configuration "awsvpcConfiguration={subnets=[<SUBNET ID>],assignPublicIp=DISABLED},securityGroups=[<sg-xxx for ecs-sagemaker-endpoint>,<sg-xxx for ecs-443-outbound>,<sg-xxx for proxy-ecs-4000>]" \
--region $REGION
Note : par bonne pratique de cybersécurité, les services ECS ne devraient pas avoir d'adresse IP publique. Détails sur https://docs.aws.amazon.com/securityhub/latest/userguide/ecs-controls.html#ecs- 2
Récupérez l'IP privée de la tâche ECS :
CLUSTER="litellm-cluster"
# étape 1 : récupérer l'ID de la tâche ECS
TASK=$(aws ecs list-tasks --cluster ${CLUSTER} --query "taskArns[0]" --output text)
# étape 2 : récupérer l'ENI de la tâche ECS
ENI=$(aws ecs describe-tasks --cluster $CLUSTER --tasks $TASK --query "tasks[0].attachments[0].details[?name=='networkInterfaceId'].value | [0]" --output text)
# étape 3 : récupérer l'adresse IP publique de l'ENI
aws ec2 describe-network-interfaces --network-interface-ids $ENI --query 'NetworkInterfaces[0].PrivateIpAddress' --output text
Notez l'IP privée de la tâche : elle sera utilisée dans la configuration du proxy.
Étape 3 : mettre en place un proxy
Dans cet exemple, nous allons configurer une instance EC2 dans le même sous-réseau privé, gérée par Amazon System Manager, afin de pouvoir nous connecter au proxy LiteLLM via le port forwarding SSM.
- Créez un nouveau Security Group,
ssm-outbound-sg, pour autoriser les connexions sortantes sur le port 443 :
Règle sortante :
- Protocole : HTTPS (443)
- Destination : 0.0.0.0/0
- Description : connexions aux endpoints SSM
- Créez trois VPC endpoints pour permettre à l'EC2 du sous-réseau privé de se connecter aux endpoints SSM :
# Endpoint Systems Manager
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ssm \
--subnet-ids <private subnet-id that the EC2 will be provisioned> \
--security-group-ids <security-group-id for EC2 to connect to, such as ec2-ssm>
# Endpoint SSM Messages
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ssmmessages \
--subnet-ids <private subnet-id that the EC2 will be provisioned> \
--security-group-ids <security-group-id for EC2 to connect to, such as ec2-ssm>
# Endpoint EC2 Messages
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ec2messages \
--subnet-ids <private subnet-id that the EC2 will be provisioned> \
--security-group-ids <security-group-id for EC2 to connect to, such as ec2-ssm>
- Créez une instance EC2 Graviton, par exemple t4g.small, sous Amazon Linux, dans le sous-réseau privé.
- Attachez-lui les security groups suivants :
- Litellm-proxy, qui autorise le port sortant 4000 vers le même security group, afin que cette EC2 proxy puisse se connecter à la tâche ECS
ssm-outbound-sg, pour permettre à l'EC2 de se connecter aux endpoints SSM
3. Une fois l'EC2 prête, connectez-vous via l'agent SSM avec port forwarding :
aws ssm start-session \
--target <EC2 instance ID, such as i-012345> \
--document-name AWS-StartPortForwardingSessionToRemoteHost \
--parameters host="<ECS Task pivate IP>",portNumber="4000",localPortNumber="4000"
Étape 4 : configurer l'environnement de coding assisté par IA
Installez Continue.dev depuis le marketplace, par exemple https://open-vsx.org/extension/Continue/continue, puis ouvrez la configuration locale.
Configurez les tâches ECS nouvellement créées comme fournisseur de modèle :
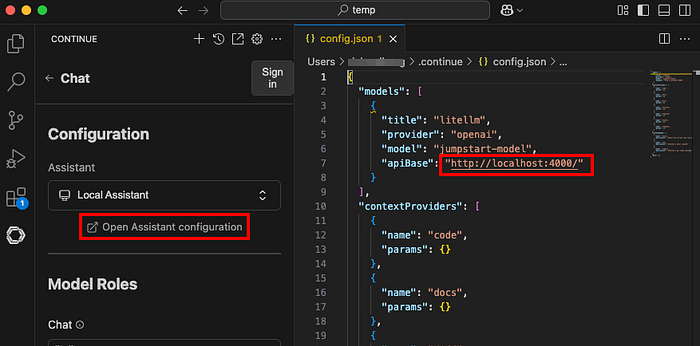
"models": [\
{\
"title": "litellm",\
"provider": "openai",\
"model": "jumpstart-model",\
"apiBase": "http://localhost:4000/",\
}\
],
Une fois la configuration mise à jour, vous pouvez joindre un fichier pour que l'IA vous assiste.

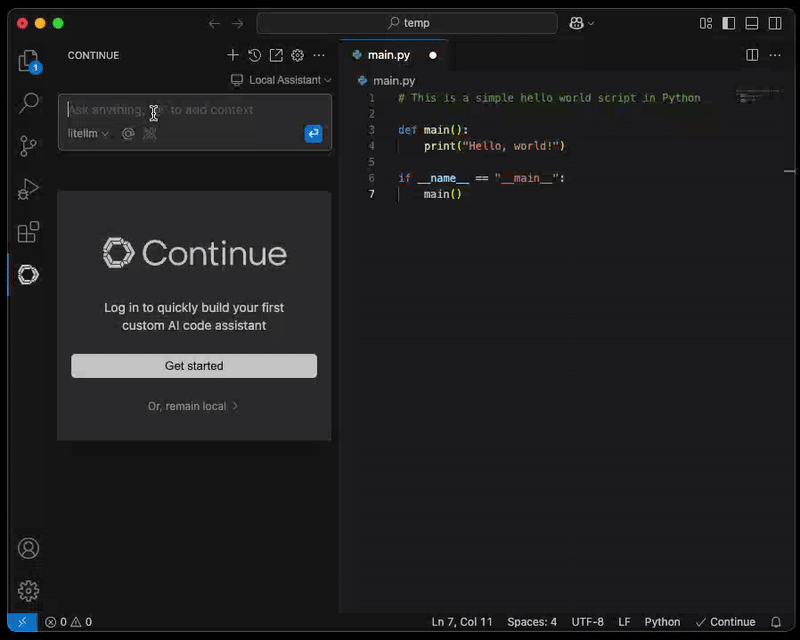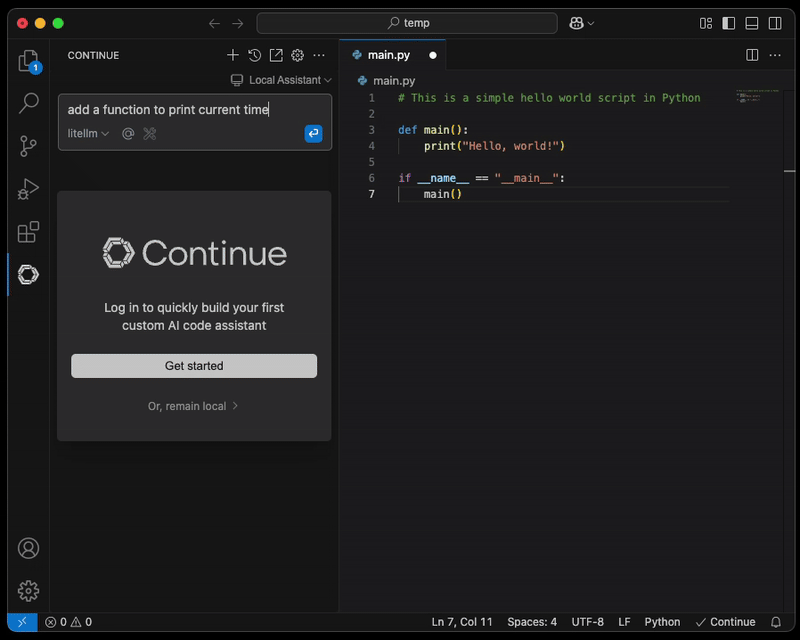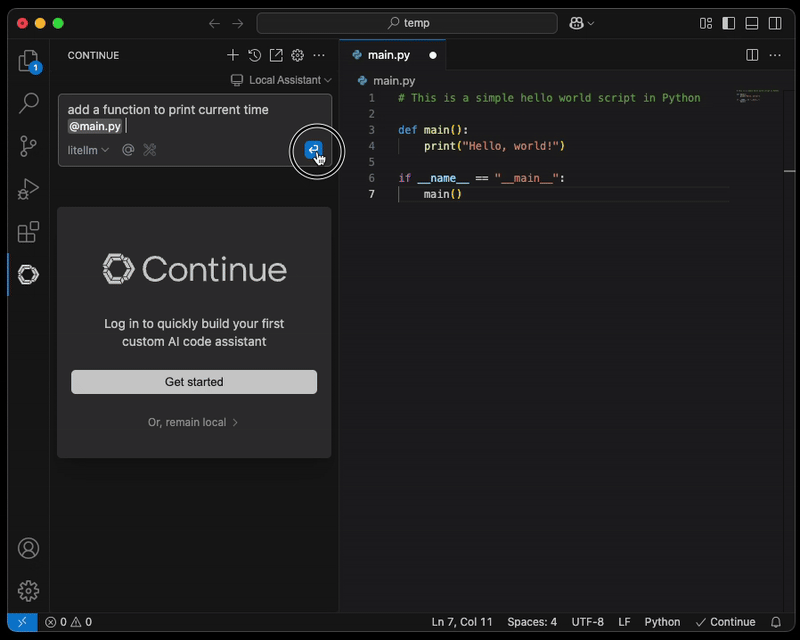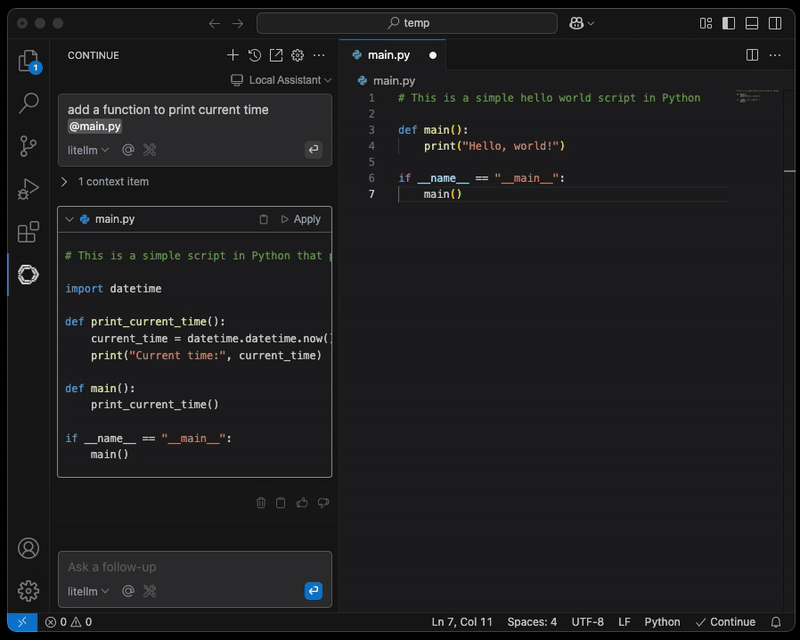
NOTE : une connexion sécurisée entre le poste de l'ingénieur et l'endpoint du proxy LiteLLM, par exemple via AWS Client VPN, est fortement recommandée.
Conclusion et appel à l'action
Héberger votre LLM sur Amazon SageMaker offre aux entreprises un contrôle inégalé, une confidentialité robuste des données et de réels gains de productivité dans le développement logiciel. DoiT International accompagne votre entreprise dans la conception et la mise en œuvre de solutions d'IA auto-hébergées, sécurisées et économiques, taillées sur mesure pour vos besoins.
Prêt à renforcer vos capacités de coding en toute sécurité ? Contactez DoiT International dès aujourd'hui pour échanger sur votre stratégie d'IA d'entreprise et garantir la confidentialité des données ainsi que la conformité.