Lleva la productividad de tus desarrolladores al siguiente nivel con asistentes de coding con IA seguros y autohospedados en Amazon SageMaker

Introducción y contexto
El coding asistido por IA ha transformado de raíz el desarrollo de software: automatiza tareas rutinarias, mejora la precisión y libera a los desarrolladores para que se concentren en resolver problemas más complejos. Cada vez más empresas optan por alojar sus modelos LLM en entornos privados, sobre todo para proteger la propiedad intelectual y el código propietario, cumplir con las regulaciones de datos y poder personalizarlos según las necesidades específicas de cada organización.
Visión general
En este blog vamos a alojar un LLM del marketplace en tu entorno de Amazon SageMaker, usando un modelo de Amazon SageMaker Jumpstart. La mayoría de los agentes autónomos de coding con IA, como Roo Code, Cline y Continue.dev, son compatibles con protocolos abiertos como OpenAI, lo que convierte a LiteLLM en el proxy OpenAI ideal para nuestra inferencia en SageMaker.
¿Por qué optar por LLMs autohospedados?
Las empresas obtienen varios beneficios al autohospedar sus modelos LLM:
- Privacidad y seguridad de los datos: alojarlos internamente garantiza la protección de los datos sensibles, el código fuente y los algoritmos propietarios.
- Personalización: permite adaptar los modelos de IA a estilos de coding específicos, a la lógica de negocio y a los requisitos regulatorios.
- Optimización de costos: una gestión eficiente de los recursos reduce los costos frente a los servicios de IA de terceros.
Productividad y casos de uso de ejemplo
El coding asistido por IA mejora la productividad y la eficiencia en todo el ciclo de desarrollo de software, por ejemplo:
- Automatizando la generación de código boilerplate
- Apoyando en el debugging y en la detección de cuellos de botella de rendimiento
- Mejorando los procesos de revisión de código
- Acelerando el onboarding y la capacitación de nuevos desarrolladores
Consideraciones importantes
- Seguridad y cumplimiento: configura correctamente los roles IAM, el cifrado y los controles de acceso.
- Gestión de costos: monitorea y optimiza el uso de la infraestructura de forma constante.
- Optimización del rendimiento: elige los tipos de instancia de SageMaker adecuados según las exigencias de cada workload.
El rol de Amazon SageMaker en el autohospedaje
Amazon SageMaker simplifica el autohospedaje al ofrecer:
- Acceso a una amplia gama de LLMs preentrenados a través de SageMaker Jumpstart.
- Una infraestructura escalable, segura y de alto rendimiento.
- Integración fluida con los servicios de AWS, lo que reduce la complejidad operativa.
Beneficios de usar Fargate
Usar AWS Fargate para desplegar el proxy de LiteLLM reduce de forma considerable la carga operativa, ya que:
- Elimina la necesidad de gestionar manualmente la infraestructura y mantener servidores.
- Se encarga automáticamente del escalado y la disponibilidad, lo que asegura un rendimiento consistente.
- Reduce la complejidad de la gestión de seguridad gracias al aislamiento y a los entornos administrados por AWS.
Arquitectura
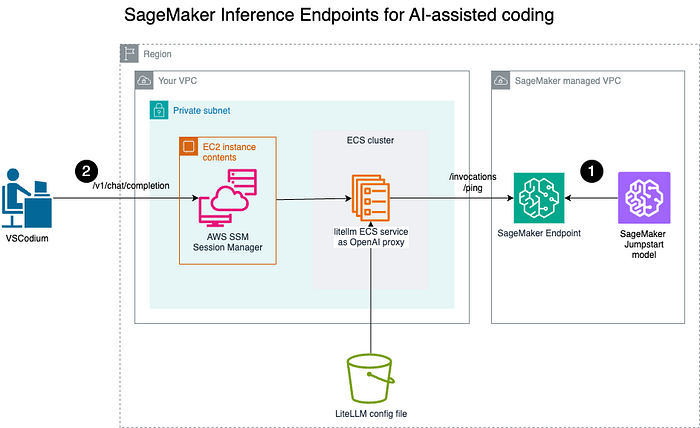
- Despliega un modelo en el endpoint de Amazon SageMaker para inferencia en tiempo real;
- Los Engineers que usan asistentes de coding con IA en IDEs locales, como VSCodium, se conectan de forma segura al proxy OpenAI de LiteLLM por un canal cifrado para invocar el LiteLLM OpenAI Proxy.
Resumen de los pasos
Primero desplegaremos un modelo preentrenado como endpoint de Amazon SageMaker. Después, ejecutaremos un proxy OpenAI con LiteLLM como un servicio de ECS.
Con eso listo, los desarrolladores ya pueden conectarse al proxy OpenAI. Para simplificar, en este tutorial la conexión se hará a través de la IP pública de la tarea de ECS.
Paso 1: Desplegar un modelo preentrenado en Amazon SageMaker
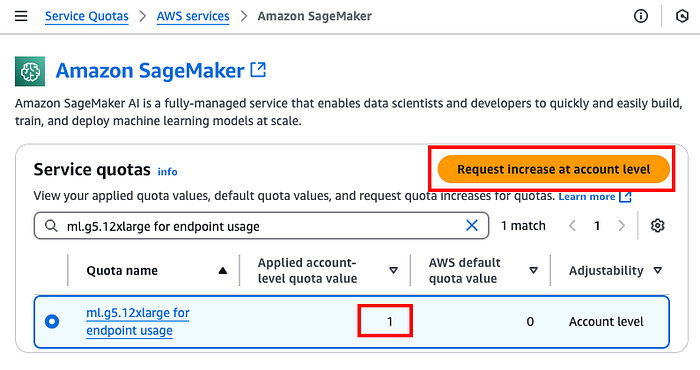
Prerrequisito: antes de aprovisionar un endpoint de Amazon SageMaker, conviene verificar que tu cuenta tenga una cuota de al menos 1 para la instancia que se usará en el endpoint. Puedes consultarlo en https://console.aws.amazon.com/servicequotas/home/services/sagemaker/quotas. Vamos a usar ml.g5.12xlarge, así que necesitarás al menos 1 en tu cuenta. Si no la tienes, puedes solicitar un aumento seleccionando "Request increase at account level."
- Si aún no tienes un rol de ejecución de Amazon SageMaker (https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html), crea un rol IAM para la ejecución de SageMaker, llámalo
AmazonSageMaker-Endpoints-ExecutionRole, asocia la política administradaarn:aws:iam::aws:policy/AmazonSageMakerFullAccessy la trust policy parasagemaker.amazonaws.com:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "sagemaker.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
2. Identifica la VPC, las Subnets privadas y el endpoint de Amazon SageMaker que se va a desplegar.
3. Crea un VPC endpoint de S3 para que el endpoint de Amazon SageMaker pueda descargar el modelo preentrenado desde el bucket de S3:
aws ec2 create-vpc-endpoint \
--private-dns-enabled \
--vpc-id <vpc-id> \
--service-name com.amazonaws.<region>.s3 \
--route-table-ids <route-table-id>
Si el comando se ejecuta correctamente, la tabla de rutas debe mostrar el VPC Endpoint junto con el NAT, así:
% aws ec2 describe-route-tables --route-table-ids <route-table-id> --query 'RouteTables[*].Routes'
[\
[\
{\
"DestinationCidrBlock": "10.0.0.0/23",\
"GatewayId": "local",\
"Origin": "CreateRouteTable",\
"State": "active"\
},\
{\
"DestinationCidrBlock": "0.0.0.0/0",\
"NatGatewayId": "nat-<NAT GW ID>",\
"Origin": "CreateRoute",\
"State": "active"\
},\
{\
"DestinationPrefixListId": "pl-63a5400a",\
"GatewayId": "vpce-<VPCE ID>",\
"Origin": "CreateRoute",\
"State": "active"\
}\
]\
]
3. Crea un Security Group ecs-sagemaker-endpoint con lo siguiente:
Regla de entrada:
- Protocolo: HTTPS (443)
- Origen: el mismo security group (autorreferencial)
Regla de salida:
- Protocolo: HTTPS (443)
- Destino: VPC endpoint de S3
Nota: como buena práctica de ciberseguridad, el Security Group por defecto no debería permitir reglas de entrada ni de salida. Más detalles en https://docs.aws.amazon.com/securityhub/latest/userguide/ec2-controls.html#ec2-2
- Identifica tu modelo en Amazon SageMaker Jumpstart (por ejemplo, Qwen2, Mistral, Llama 3.2). El listado de modelos preentrenados está disponible en https://sagemaker.readthedocs.io/en/stable/doc_utils/pretrainedmodels.html.
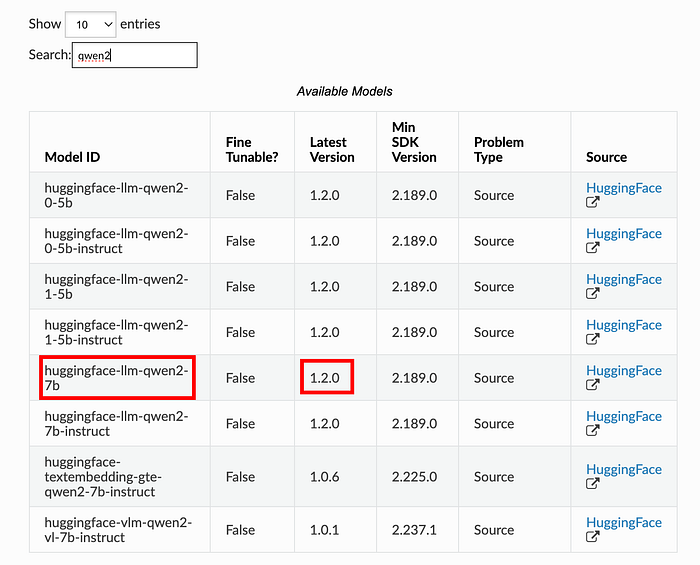
2. Anota el Model ID y la versión para crear un modelo de Amazon SageMaker:
from sagemaker.jumpstart.model import JumpStartModel
jump_start_model = JumpStartModel(
model_id="huggingface-llm-qwen2-7b-instruct",
model_version="1.2.0",
role="AmazonSageMaker-Endpoints-ExecutionRole",# o el rol de ejecución de Amazon SageMaker correspondiente
vpc_config={
"Subnets": [ "Private Subnets" ],
"SecurityGroupIds": [ "ecs-sagemaker-endpoint" ]
},
)
jump_start_model.deploy(
initial_instance_count=1,
instance_type="ml.g5.12xlarge",
accept_eula=True,
endpoint_name="jumpstart-model"
)
Confirma el estado de tu endpoint con AWS CLI:
% aws sagemaker list-endpoints
{
"Endpoints": [\
{\
"EndpointName": "jumpstart-model",\
"EndpointArn": "arn:aws:sagemaker:<AWS REGION>:<AWS ACCOUNT ID>:endpoint/jumpstart-model",\
"CreationTime": "<CreationTime>",\
"LastModifiedTime": "<LastModifiedTime>",\
"EndpointStatus": "InService"\
}\
]
}
Paso 2: Desplegar el proxy OpenAI con Amazon Elastic Container Service (ECS)
Los detalles para configurar el proxy de LiteLLM están en https://docs.litellm.ai/docs/proxy/configs
- Crea un archivo YAML de configuración (
config.yaml) para mapear el endpoint de SageMaker:
model_list:
- model_name: jumpstart-model
litellm_params:
model: sagemaker/jumpstart-model # usa el namespace sagemaker y apunta al nombre del endpoint de Amazon SageMaker
2. Sube config.yaml a un bucket de S3.
3. Define tu contenedor de ECS (container-definition.json):
[\
{\
"name": "litellm",\
"image": "ghcr.io/berriai/litellm:main-latest",\
"cpu": 0,\
"portMappings": [\
{\
"containerPort": 4000,\
"hostPort": 4000,\
"protocol": "tcp"\
}\
],\
"essential": true,\
"environment": [\
{\
"name": "LITELLM_CONFIG_BUCKET_OBJECT_KEY",\
"value": "config.yaml"\
},\
{\
"name": "LITELLM_CONFIG_BUCKET_NAME",\
"value": "<S3 bucket>"\
},\
{\
"name": "LITELLM_MASTER_KEY",\
"value": "<API key para llamar al proxy, por ejemplo sk-123123>"\
}\
],\
"mountPoints": [],\
"volumesFrom": [],\
"logConfiguration": {\
"logDriver": "awslogs",\
"options": {\
"awslogs-group": "/ecs/litellm",\
"awslogs-create-group": "true",\
"awslogs-region": "us-east-1",\
"awslogs-stream-prefix": "ecs"\
}\
},\
"systemControls": []\
}\
]
3. Crea un rol IAM para el task role de ECS con el menor privilegio posible, como se muestra a continuación:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Sid": "Statement1",\
"Effect": "Allow",\
"Action": [\
"sagemaker:InvokeEndpoint"\
],\
"Resource": [\
"arn:aws:sagemaker:<AWS REGION>:<AWS ACCOUNT ID>:endpoint/jumpstart-model"\
]\
}\
]
}
4. Registra la task definition de ECS:
aws ecs register-task-definition \
--family litellm-task \
--requires-compatibilities FARGATE \
--cpu 1024 \
--memory 2048 \
--network-mode awsvpc \
--runtime-platform cpuArchitecture=ARM64 \
--task-role-arn "<ECS Task Role ARN>" \
--container-definitions file://./container-definition.json \
--region $REGION
Antes de crear el servicio de ECS, necesitamos definir lo siguiente:
- El ID de la subnet en la que se ejecutarán las tareas de ECS.
- El Security Group que permite a las tareas de ECS conectarse a los endpoints de Amazon SageMaker. En este artículo se creó como
ecs-sagemaker-endpoint.
También hay que crear un security group para que las tareas de ECS puedan descargar la imagen del contenedor de LiteLLM:
Regla de salida:
- Protocolo: HTTPS (443)
- Destino: 0.0.0.0/0
- Descripción: descarga de imagen de tareas de ECS
Otro Security Group para el proxy hacia las tareas de ECS:
Regla de entrada:
- Protocolo: puerto LiteLLM (4000)
- Origen: el mismo security group (autorreferencial)
Regla de salida:
- Protocolo: puerto LiteLLM (4000)
- Destino: el mismo security group (autorreferencial)
- Descripción: proxy y tareas de ECS
Crea un servicio de ECS con la task definition y el ID de la subnet:
aws ecs create-service \
--cluster litellm-cluster \
--service-name litellm-service \
--task-definition litellm-task:1 \
--desired-count 1 \
--launch-type FARGATE \
--platform-version LATEST \
--network-configuration "awsvpcConfiguration={subnets=[<SUBNET ID>],assignPublicIp=DISABLED},securityGroups=[<sg-xxx for ecs-sagemaker-endpoint>,<sg-xxx for ecs-443-outbound>,<sg-xxx for proxy-ecs-4000>]" \
--region $REGION
Nota: como buena práctica de ciberseguridad, los servicios de ECS no deberían tener direcciones IP públicas. Más detalles en https://docs.aws.amazon.com/securityhub/latest/userguide/ecs-controls.html#ecs- 2
Obtén la IP privada de la tarea de ECS:
CLUSTER="litellm-cluster"
# paso 1: obtener el id de la tarea de ECS
TASK=$(aws ecs list-tasks --cluster ${CLUSTER} --query "taskArns[0]" --output text)
# paso 2: obtener el eni a partir de la tarea de ECS
ENI=$(aws ecs describe-tasks --cluster $CLUSTER --tasks $TASK --query "tasks[0].attachments[0].details[?name=='networkInterfaceId'].value | [0]" --output text)
# paso 3: obtener la dirección IP pública del ENI
aws ec2 describe-network-interfaces --network-interface-ids $ENI --query 'NetworkInterfaces[0].PrivateIpAddress' --output text
Anota la IP privada de la tarea, que se usará en la configuración del proxy.
Paso 3: Configurar un proxy
En este ejemplo levantaremos una EC2 en la misma subnet privada, administrada por Amazon System Manager, para conectarnos al proxy de LiteLLM mediante port forwarding de SSM.
- Crea un nuevo Security Group,
ssm-outbound-sg, que permita conexiones salientes en el puerto 443:
Regla de salida:
- Protocolo: HTTPS (443)
- Destino: 0.0.0.0/0
- Descripción: conexiones a endpoints de SSM
- Crea tres VPC endpoints para que la EC2 en la subnet privada se conecte a los endpoints de SSM:
# Endpoint de Systems Manager
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ssm \
--subnet-ids <private subnet-id en el que se aprovisionará la EC2> \
--security-group-ids <security-group-id al que se conectará la EC2, como ec2-ssm>
# Endpoint de SSM Messages
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ssmmessages \
--subnet-ids <private subnet-id en el que se aprovisionará la EC2> \
--security-group-ids <security-group-id al que se conectará la EC2, como ec2-ssm>
# Endpoint de EC2 Messages
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ec2messages \
--subnet-ids <private subnet-id en el que se aprovisionará la EC2> \
--security-group-ids <security-group-id al que se conectará la EC2, como ec2-ssm>
- Crea una EC2 Graviton, por ejemplo t4g.small, con Amazon Linux, en la subnet privada.
- Asocia estos security groups a la EC2:
- Litellm-proxy, que permite la salida en el puerto 4000 hacia el mismo security group, para que esta EC2 proxy pueda conectarse a la tarea de ECS.
ssm-outbound-sg, para que la EC2 pueda conectarse a los endpoints de SSM.
3. Cuando la EC2 esté lista, conéctate usando el agente SSM con port forwarding:
aws ssm start-session \
--target <ID de instancia EC2, por ejemplo i-012345> \
--document-name AWS-StartPortForwardingSessionToRemoteHost \
--parameters host="<IP privada de la tarea de ECS>",portNumber="4000",localPortNumber="4000"
Paso 4: Configurar el entorno de coding asistido por IA
Instala Continue.dev desde el marketplace, por ejemplo desde https://open-vsx.org/extension/Continue/continue, y abre la configuración local.
Configura las nuevas tareas de ECS como proveedor del modelo:
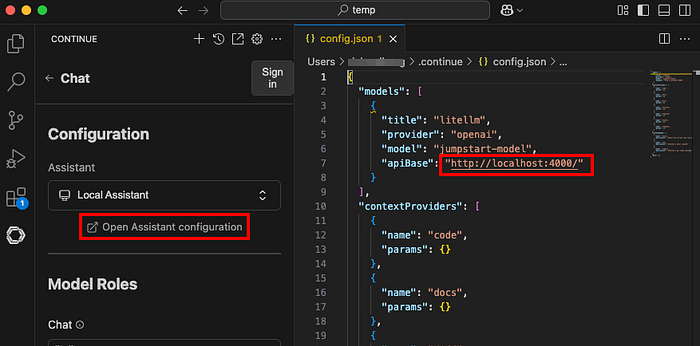
"models": [\
{\
"title": "litellm",\
"provider": "openai",\
"model": "jumpstart-model",\
"apiBase": "http://localhost:4000/",\
}\
],
Una vez actualizada la configuración, ya puedes adjuntar un archivo para que la IA te ayude.

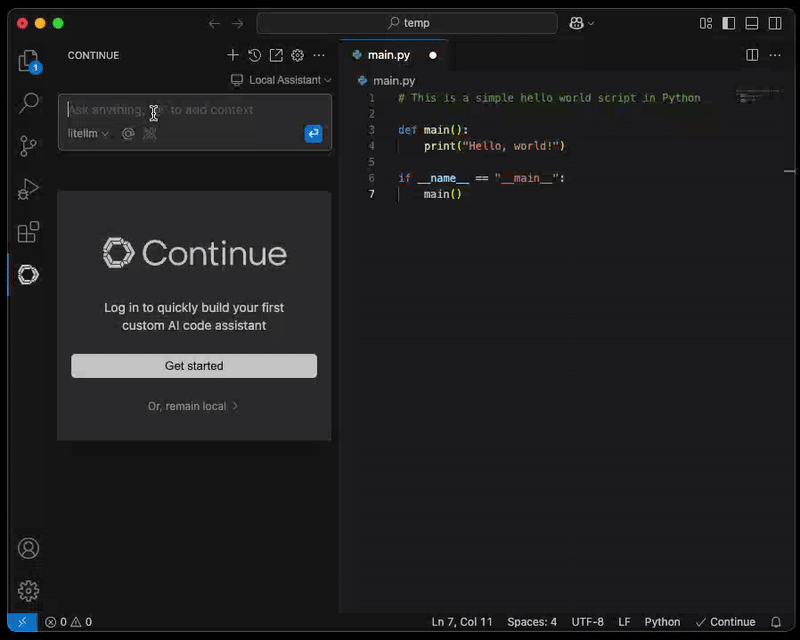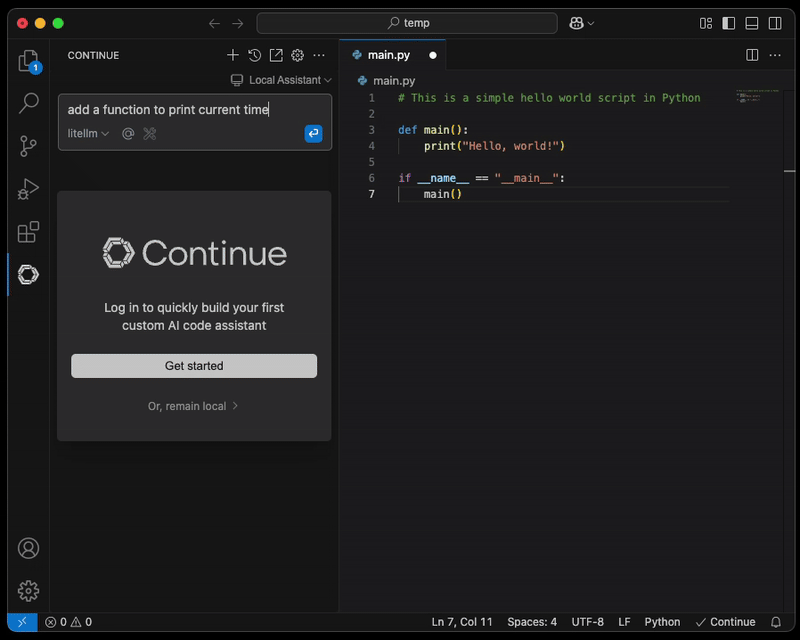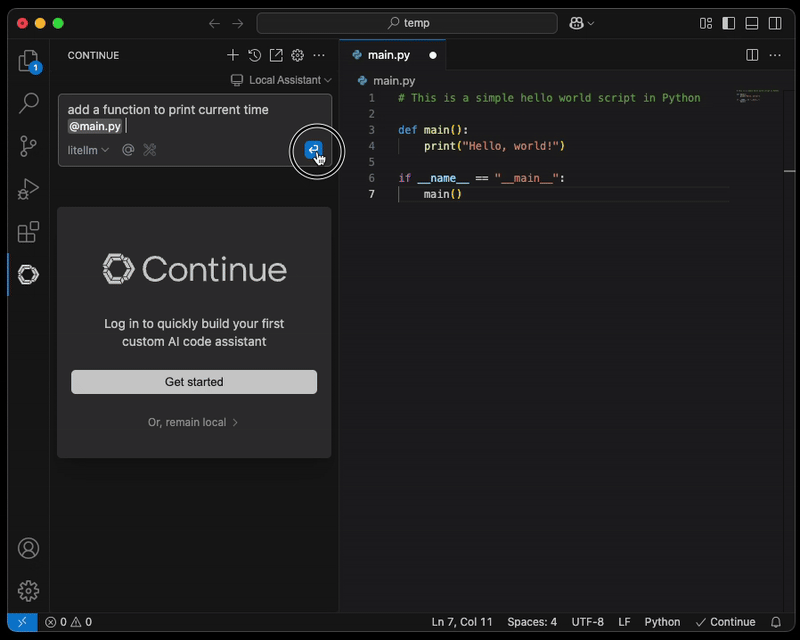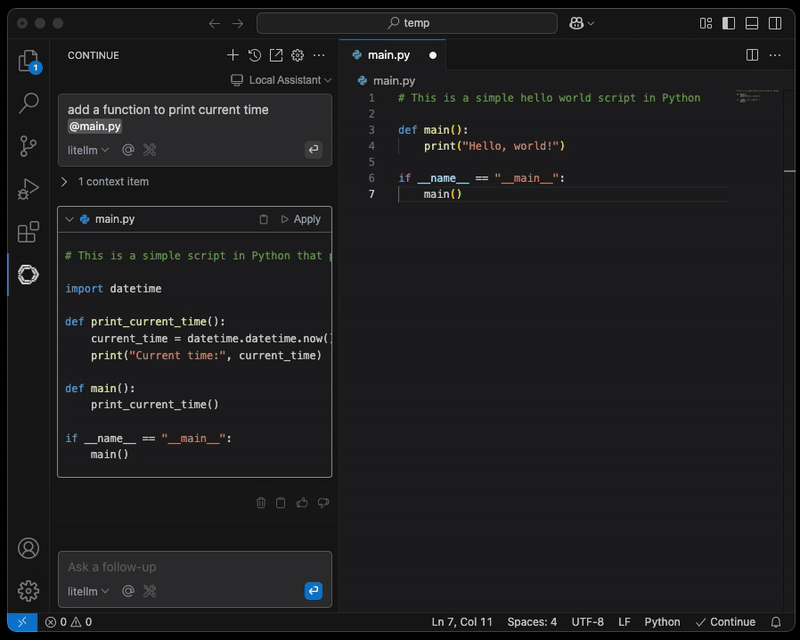
NOTA: se recomienda enfáticamente establecer una conexión segura desde la laptop del Engineer hacia el endpoint del proxy de LiteLLM, por ejemplo mediante AWS Client VPN.
Conclusión y llamada a la acción
Alojar tu LLM en Amazon SageMaker le da a tu empresa un control sin precedentes, una sólida privacidad de los datos y mejoras notables de productividad en el desarrollo de software. DoiT International puede acompañar a tu empresa en el diseño y la implementación de soluciones de IA autohospedadas, seguras y costo-eficientes, hechas a la medida de tus necesidades.
¿Listo para llevar tus capacidades de coding al siguiente nivel de forma segura? Contacta a DoiT International hoy mismo para conversar sobre tu estrategia de IA empresarial y asegurar una sólida privacidad de los datos y cumplimiento normativo.