Potenzi la produttività degli sviluppatori enterprise con assistenti di coding AI sicuri e self-hosted su Amazon SageMaker

Introduzione e contesto
Il coding assistito dall'AI ha trasformato profondamente lo sviluppo software: automatizza le attività di routine, aumenta la precisione e libera gli sviluppatori, che possono dedicarsi maggiormente alla risoluzione di problemi complessi. Sempre più aziende scelgono di ospitare i propri LLM in ambienti privati, soprattutto per tutelare proprietà intellettuale e codice proprietario, rispettare le normative sui dati e personalizzare i modelli in base alle esigenze specifiche dell'organizzazione.
Panoramica
In questo articolo ospiteremo un LLM del marketplace nel Suo ambiente Amazon SageMaker, partendo da un modello di Amazon SageMaker Jumpstart. La maggior parte degli agenti di coding autonomi basati su AI — come Roo Code, Cline e Continue.dev — supporta protocolli aperti come OpenAI: ciò rende LiteLLM il proxy OpenAI ideale per la nostra inferenza SageMaker.
Perché scegliere LLM self-hosted?
Le aziende traggono vantaggio dagli LLM self-hosted per diversi motivi:
- Privacy e sicurezza dei dati: l'hosting interno mette al riparo dati sensibili, codice sorgente e algoritmi proprietari.
- Personalizzazione: i modelli AI vengono adattati a stili di codifica, logiche di business e requisiti normativi specifici.
- Ottimizzazione dei costi: una gestione efficiente delle risorse riduce i costi rispetto ai servizi AI di terze parti.
Produttività e casi d'uso
Il coding assistito dall'AI fa crescere produttività ed efficienza lungo l'intero ciclo di sviluppo software, ad esempio:
- Automatizzando la generazione di codice boilerplate
- Supportando il debug e l'individuazione dei colli di bottiglia nelle prestazioni
- Migliorando i processi di code review
- Accelerando l'onboarding e la formazione dei nuovi sviluppatori
Aspetti importanti da considerare
- Sicurezza e conformità: configurazione corretta di ruoli IAM, crittografia e controlli di accesso.
- Gestione dei costi: monitoraggio e ottimizzazione costanti dell'utilizzo dell'infrastruttura.
- Ottimizzazione delle prestazioni: scelta del tipo di istanza SageMaker più adatto in base alle esigenze degli specifici workloads.
Il ruolo di Amazon SageMaker nel self-hosting
Amazon SageMaker semplifica il self-hosting offrendo:
- Accesso a un'ampia gamma di LLM pre-addestrati tramite SageMaker Jumpstart.
- Gestione dell'infrastruttura scalabile, sicura e ad alte prestazioni.
- Integrazione fluida con i servizi AWS, che riduce la complessità operativa.
I vantaggi di Fargate
Adottare AWS Fargate per il deployment del proxy LiteLLM riduce sensibilmente l'overhead operativo:
- Elimina la necessità di gestire manualmente l'infrastruttura e la manutenzione dei server.
- Gestisce in automatico scalabilità e disponibilità, garantendo prestazioni costanti.
- Riduce la complessità di gestione della sicurezza grazie all'isolamento e ad ambienti gestiti da AWS.
Architettura
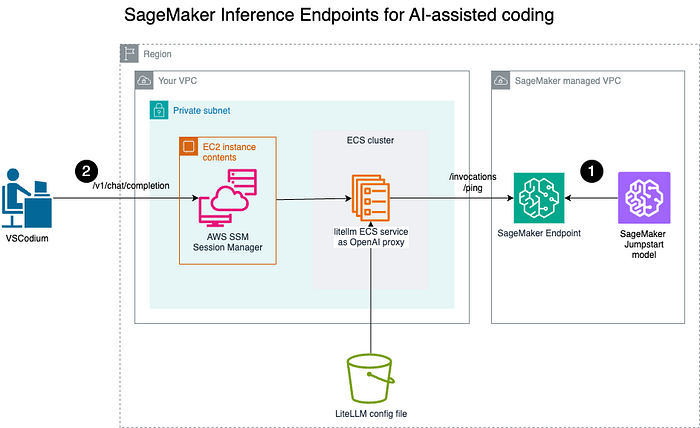
- Esegua il deployment di un modello sull'endpoint Amazon SageMaker per l'inferenza in tempo reale;
- Gli Engineers che usano assistenti di coding AI in IDE locali — ad esempio VSCodium — si collegano in modo sicuro al proxy OpenAI LiteLLM tramite un canale protetto per invocare il LiteLLM OpenAI Proxy.
I passaggi in sintesi
Per prima cosa effettueremo il deployment di un modello pre-addestrato come endpoint Amazon SageMaker. Quindi avvieremo un proxy OpenAI con LiteLLM come servizio ECS.
A questo punto gli sviluppatori potranno collegarsi al proxy OpenAI. Per semplicità, in questo tutorial la connessione avverrà tramite l'IP pubblico del task ECS.
Passo 1: deployment di un modello pre-addestrato su Amazon SageMaker
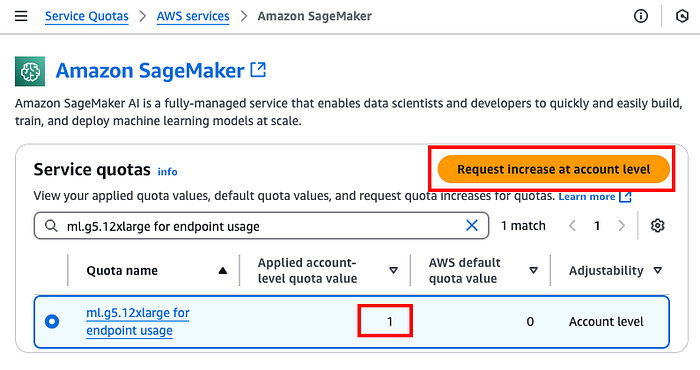
Prerequisito: prima di provisionare un endpoint Amazon SageMaker, verifichi che il Suo account disponga di una quota pari ad almeno 1 per il tipo di istanza che utilizzerà. Può controllarla su https://console.aws.amazon.com/servicequotas/home/services/sagemaker/quotas. Useremo ml.g5.12xlarge, quindi serve almeno 1 unità sul Suo account. In caso contrario può inviare una richiesta selezionando "Request increase at account level".
- Se non ha già un ruolo di esecuzione Amazon SageMaker (https://docs.aws.amazon.com/sagemaker/latest/dg/sagemaker-roles.html), crei un ruolo IAM per l'esecuzione SageMaker — lo chiameremo
AmazonSageMaker-Endpoints-ExecutionRole— e vi alleghi la managed policyarn:aws:iam::aws:policy/AmazonSageMakerFullAccesse la trust policy persagemaker.amazonaws.com:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Effect": "Allow",\
"Principal": {\
"Service": "sagemaker.amazonaws.com"\
},\
"Action": "sts:AssumeRole"\
}\
]
}
2. Individui il VPC, le Subnet private e l'endpoint Amazon SageMaker che verrà deployato.
3. Crei un VPC endpoint per S3, in modo che l'endpoint Amazon SageMaker possa scaricare il modello pre-addestrato dal bucket S3:
aws ec2 create-vpc-endpoint \
--private-dns-enabled \
--vpc-id <vpc-id> \
--service-name com.amazonaws.<region>.s3 \
--route-table-ids <route-table-id>
Se il comando viene eseguito correttamente, la route table dovrebbe contenere il VPC Endpoint insieme al NAT, ad esempio:
% aws ec2 describe-route-tables --route-table-ids <route-table-id> --query 'RouteTables[*].Routes'
[\
[\
{\
"DestinationCidrBlock": "10.0.0.0/23",\
"GatewayId": "local",\
"Origin": "CreateRouteTable",\
"State": "active"\
},\
{\
"DestinationCidrBlock": "0.0.0.0/0",\
"NatGatewayId": "nat-<NAT GW ID>",\
"Origin": "CreateRoute",\
"State": "active"\
},\
{\
"DestinationPrefixListId": "pl-63a5400a",\
"GatewayId": "vpce-<VPCE ID>",\
"Origin": "CreateRoute",\
"State": "active"\
}\
]\
]
3. Crei un Security Group ecs-sagemaker-endpoint con le seguenti regole:
Regola in ingresso:
- Protocollo: HTTPS (443)
- Origine: il security group stesso (autoreferenziale)
Regola in uscita
- Protocollo: HTTPS (443)
- Destinazione: VPC endpoint S3
Nota: secondo le buone pratiche di cybersecurity, il Security Group predefinito non dovrebbe consentire alcuna regola in ingresso o in uscita. Maggiori dettagli su https://docs.aws.amazon.com/securityhub/latest/userguide/ec2-controls.html#ec2-2
- Individui il modello da Amazon SageMaker Jumpstart (ad esempio Qwen2, Mistral, Llama 3.2). L'elenco dei modelli pre-addestrati è disponibile su https://sagemaker.readthedocs.io/en/stable/doc_utils/pretrainedmodels.html.
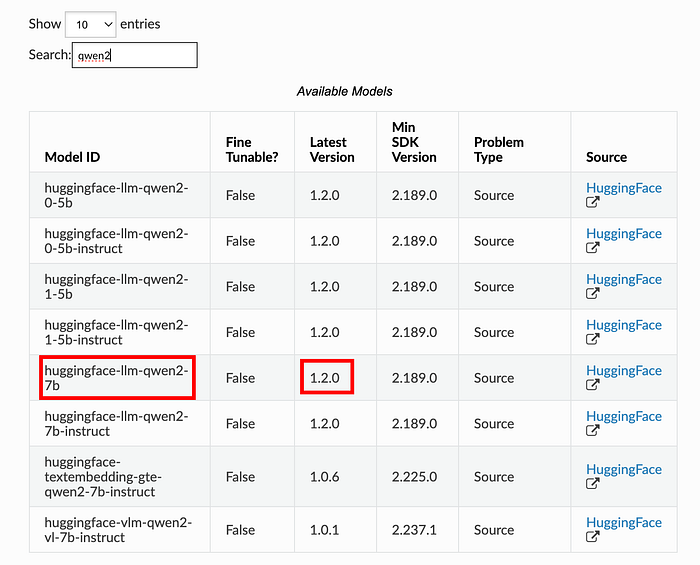
2. Annoti Model ID e versione per creare un modello Amazon SageMaker:
from sagemaker.jumpstart.model import JumpStartModel
jump_start_model = JumpStartModel(
model_id="huggingface-llm-qwen2-7b-instruct",
model_version="1.2.0",
role="AmazonSageMaker-Endpoints-ExecutionRole",# o il ruolo di esecuzione Amazon SageMaker pertinente
vpc_config={
"Subnets": [ "Private Subnets" ],
"SecurityGroupIds": [ "ecs-sagemaker-endpoint" ]
},
)
jump_start_model.deploy(
initial_instance_count=1,
instance_type="ml.g5.12xlarge",
accept_eula=True,
endpoint_name="jumpstart-model"
)
Verifichi lo stato dell'endpoint con la AWS CLI:
% aws sagemaker list-endpoints
{
"Endpoints": [\
{\
"EndpointName": "jumpstart-model",\
"EndpointArn": "arn:aws:sagemaker:<AWS REGION>:<AWS ACCOUNT ID>:endpoint/jumpstart-model",\
"CreationTime": "<CreationTime>",\
"LastModifiedTime": "<LastModifiedTime>",\
"EndpointStatus": "InService"\
}\
]
}
Passo 2: deployment del proxy OpenAI con Amazon Elastic Container Service (ECS)
I dettagli sulla configurazione del proxy LiteLLM sono disponibili su https://docs.litellm.ai/docs/proxy/configs
- Crei un file di configurazione YAML (
config.yaml) per mappare l'endpoint SageMaker:
model_list:
- model_name: jumpstart-model
litellm_params:
model: sagemaker/jumpstart-model # usa il namespace sagemaker e punta al nome dell'endpoint Amazon SageMaker
2. Carichi config.yaml in un bucket S3.
3. Definisca il container ECS (container-definition.json):
[\
{\
"name": "litellm",\
"image": "ghcr.io/berriai/litellm:main-latest",\
"cpu": 0,\
"portMappings": [\
{\
"containerPort": 4000,\
"hostPort": 4000,\
"protocol": "tcp"\
}\
],\
"essential": true,\
"environment": [\
{\
"name": "LITELLM_CONFIG_BUCKET_OBJECT_KEY",\
"value": "config.yaml"\
},\
{\
"name": "LITELLM_CONFIG_BUCKET_NAME",\
"value": "<S3 bucket>"\
},\
{\
"name": "LITELLM_MASTER_KEY",\
"value": "<chiave API per chiamare il proxy, ad esempio sk-123123>"\
}\
],\
"mountPoints": [],\
"volumesFrom": [],\
"logConfiguration": {\
"logDriver": "awslogs",\
"options": {\
"awslogs-group": "/ecs/litellm",\
"awslogs-create-group": "true",\
"awslogs-region": "us-east-1",\
"awslogs-stream-prefix": "ecs"\
}\
},\
"systemControls": []\
}\
]
3. Crei un ruolo IAM per il task role ECS secondo il principio del minimo privilegio:
{
"Version": "2012-10-17",
"Statement": [\
{\
"Sid": "Statement1",\
"Effect": "Allow",\
"Action": [\
"sagemaker:InvokeEndpoint"\
],\
"Resource": [\
"arn:aws:sagemaker:<AWS REGION>:<AWS ACCOUNT ID>:endpoint/jumpstart-model"\
]\
}\
]
}
4. Registri la task definition ECS:
aws ecs register-task-definition \
--family litellm-task \
--requires-compatibilities FARGATE \
--cpu 1024 \
--memory 2048 \
--network-mode awsvpc \
--runtime-platform cpuArchitecture=ARM64 \
--task-role-arn "<ECS Task Role ARN>" \
--container-definitions file://./container-definition.json \
--region $REGION
Prima di creare il servizio ECS, servono queste impostazioni:
- L'ID della subnet in cui verranno eseguiti i task ECS.
- Il Security Group che consente ai task ECS di connettersi agli endpoint Amazon SageMaker. In questo articolo è stato creato come
ecs-sagemaker-endpoint.
Va inoltre creato un security group che consenta ai task ECS di scaricare l'immagine container LiteLLM:
Regola in uscita
- Protocollo: HTTPS (443)
- Destinazione: 0.0.0.0/0
- Descrizione: download dell'immagine per i task ECS
Un altro Security Group per il proxy verso i task ECS:
Regola in ingresso:
- Protocollo: porta LiteLLM (4000)
- Origine: il security group stesso (autoreferenziale)
Regola in uscita
- Protocollo: porta LiteLLM (4000)
- Destinazione: lo stesso security group (autoreferenziale)
- Descrizione: proxy e task ECS
Crei un servizio ECS con la task definition e il Subnet ID:
aws ecs create-service \
--cluster litellm-cluster \
--service-name litellm-service \
--task-definition litellm-task:1 \
--desired-count 1 \
--launch-type FARGATE \
--platform-version LATEST \
--network-configuration "awsvpcConfiguration={subnets=[<SUBNET ID>],assignPublicIp=DISABLED},securityGroups=[<sg-xxx for ecs-sagemaker-endpoint>,<sg-xxx for ecs-443-outbound>,<sg-xxx for proxy-ecs-4000>]" \
--region $REGION
Nota: secondo le buone pratiche di cybersecurity, i servizi ECS non dovrebbero avere indirizzi IP pubblici. Maggiori dettagli su https://docs.aws.amazon.com/securityhub/latest/userguide/ecs-controls.html#ecs- 2
Recuperi l'IP privato del task ECS:
CLUSTER="litellm-cluster"
# step 1: ottiene l'id del task ECS
TASK=$(aws ecs list-tasks --cluster ${CLUSTER} --query "taskArns[0]" --output text)
# step 2: ottiene la eni dal task ECS
ENI=$(aws ecs describe-tasks --cluster $CLUSTER --tasks $TASK --query "tasks[0].attachments[0].details[?name=='networkInterfaceId'].value | [0]" --output text)
# step 3: ottiene l'indirizzo IP pubblico della ENI
aws ec2 describe-network-interfaces --network-interface-ids $ENI --query 'NetworkInterfaces[0].PrivateIpAddress' --output text
Annoti l'IP privato del task: servirà per la configurazione del proxy.
Passo 3: configurazione del proxy
In questo esempio configureremo un'istanza EC2 nella stessa subnet privata, gestita da Amazon Systems Manager, così da potersi collegare al proxy LiteLLM tramite il port forwarding di SSM.
- Crei un nuovo Security Group,
ssm-outbound-sg, per consentire le connessioni in uscita sulla porta 443:
Regola in uscita
- Protocollo: HTTPS (443)
- Destinazione: 0.0.0.0/0
- Descrizione: connessioni agli endpoint SSM
- Crei tre VPC endpoint affinché l'EC2 nella subnet privata possa raggiungere gli endpoint SSM
# Endpoint Systems Manager
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ssm \
--subnet-ids <private subnet-id in cui verrà provisionata l'EC2> \
--security-group-ids <security-group-id a cui l'EC2 si connette, ad esempio ec2-ssm>
# Endpoint SSM Messages
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ssmmessages \
--subnet-ids <private subnet-id in cui verrà provisionata l'EC2> \
--security-group-ids <security-group-id a cui l'EC2 si connette, ad esempio ec2-ssm>
# Endpoint EC2 Messages
aws ec2 create-vpc-endpoint \
--vpc-id <vpc-id> \
--vpc-endpoint-type Interface \
--service-name com.amazonaws.<region>.ec2messages \
--subnet-ids <private subnet-id in cui verrà provisionata l'EC2> \
--security-group-ids <security-group-id a cui l'EC2 si connette, ad esempio ec2-ssm>
- Crei un'istanza EC2 Graviton, ad esempio t4g.small, con Amazon Linux, nella subnet privata.
- Associ a questa EC2 i seguenti security group:
- Litellm-proxy, che apre la porta 4000 in uscita verso lo stesso security group, in modo che questa EC2 proxy possa raggiungere il task ECS
ssm-outbound-sg, per consentire all'EC2 di connettersi agli endpoint SSM
3. Quando l'EC2 è pronta, si colleghi tramite l'agent SSM con port forwarding:
aws ssm start-session \
--target <ID istanza EC2, ad esempio i-012345> \
--document-name AWS-StartPortForwardingSessionToRemoteHost \
--parameters host="<IP privato del task ECS>",portNumber="4000",localPortNumber="4000"
Passo 4: configurare l'ambiente di coding assistito dall'AI
Installi Continue.dev dal marketplace, ad esempio da https://open-vsx.org/extension/Continue/continue, e apra la configurazione locale.
Configuri i task ECS appena creati come model provider:
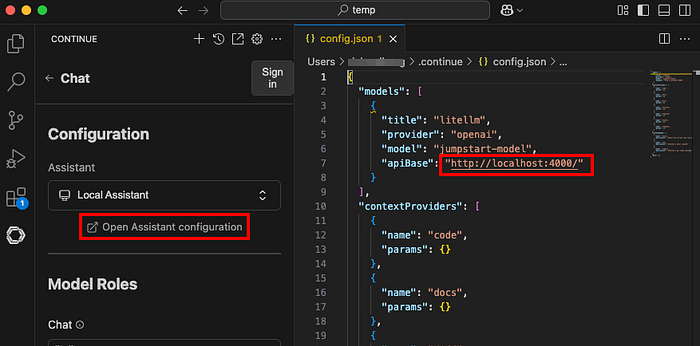
"models": [\
{\
"title": "litellm",\
"provider": "openai",\
"model": "jumpstart-model",\
"apiBase": "http://localhost:4000/",\
}\
],
Una volta aggiornata la configurazione, può allegare un file e farsi assistere dall'AI.

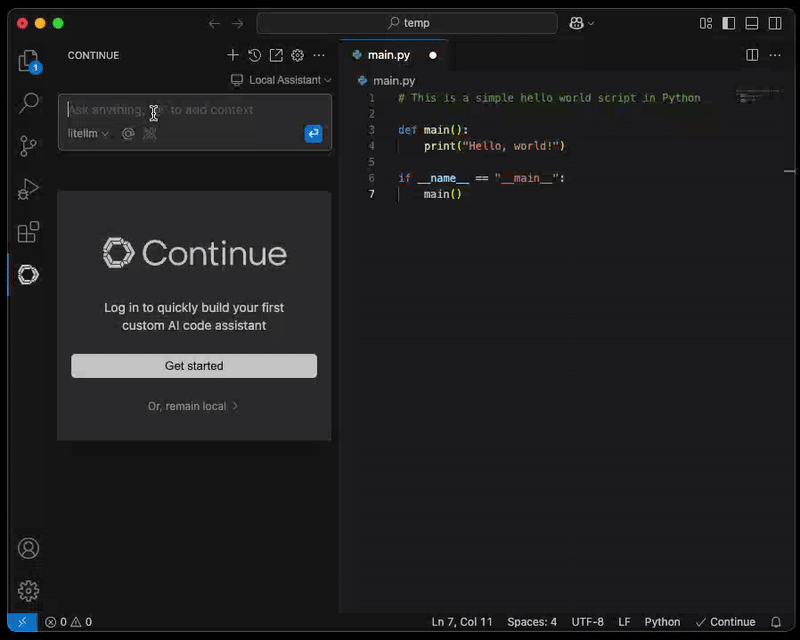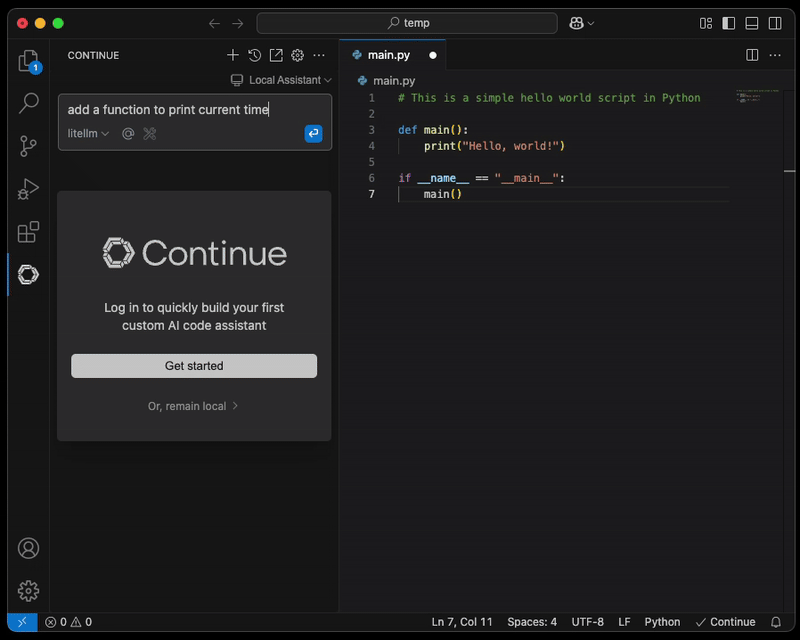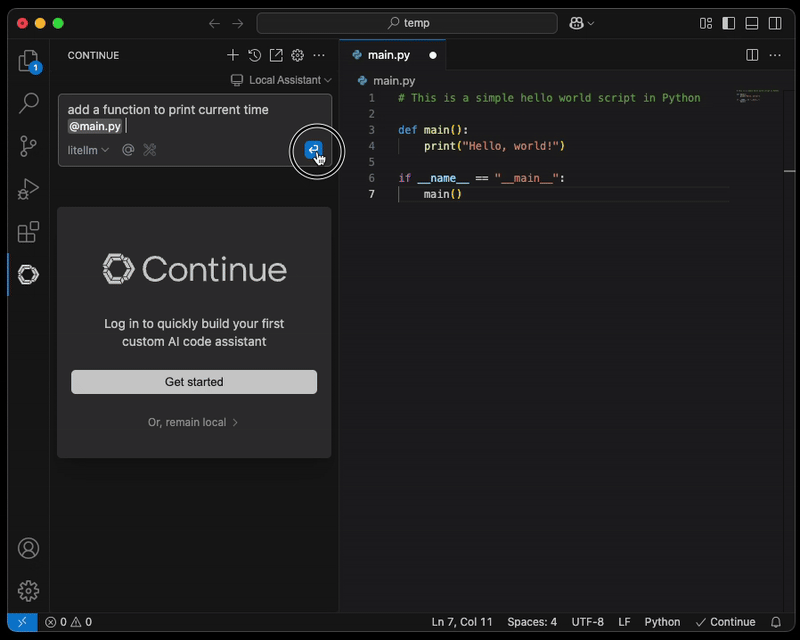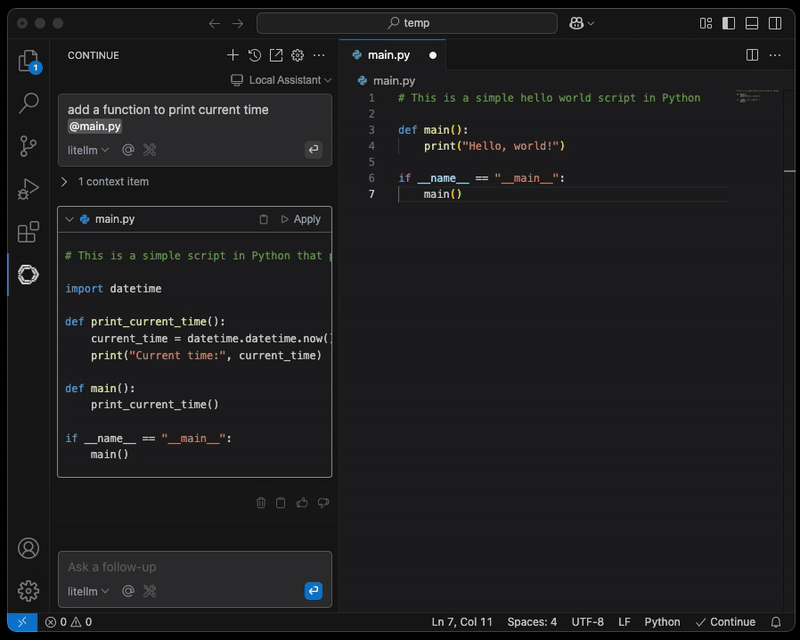
NOTA: si consiglia vivamente una connessione protetta tra il laptop dell'engineer e l'endpoint del proxy LiteLLM, ad esempio tramite AWS Client VPN.
Conclusioni e invito all'azione
Ospitare il Suo LLM su Amazon SageMaker offre alle aziende un controllo senza pari, una solida tutela della privacy dei dati e un netto incremento della produttività nello sviluppo software. DoiT International può accompagnarLa con competenza nella progettazione e implementazione di soluzioni AI self-hosted, sicure e convenienti, su misura per le Sue esigenze.
Vuole potenziare le Sue capacità di coding in totale sicurezza? Contatti DoiT International oggi stesso per definire la Sua strategia AI enterprise e garantire una solida tutela della privacy dei dati e la piena conformità.