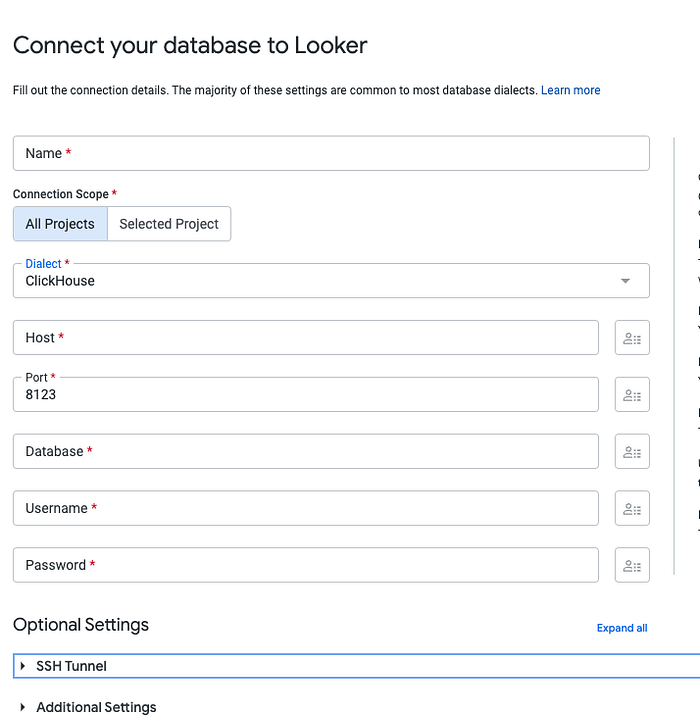
Wie geht es weiter
Im vorherigen Teil haben wir besprochen, was dieser Plan eigentlich leisten soll und wie sich ein einfacher ClickHouse-Service mit dem DBaaS-Angebot von Aiven oder ClickHouse aufsetzen lässt. In diesem Abschnitt steigen wir nun in den Prozess ein, die Daten nach ClickHouse zu bringen und die Replikation zwischen ClickHouse und BigQuery einzurichten.
GitHub-Repository
Im Verlauf dieses Artikels verweise ich auf eine Cloud Function und einen BigQuery-Job. Den Quellcode für beide Artefakte finden Sie hier in diesem GitHub-Repository.
Bitte beachten Sie: Der Code ist bewusst sehr einfach gehalten und als Lernbeispiel gedacht. Mit hoher Wahrscheinlichkeit muss er für den produktiven Einsatz in Ihrem Szenario angepasst werden.
Daten aus BigQuery nach ClickHouse bringen
Aktuell gibt es keine automatisierten Verfahren, um CDC oder Streaming aus BigQuery in ein beliebiges Ziel zu betreiben. Das heißt: Daten müssen entweder erfasst werden, bevor sie in BigQuery landen, oder im Nachgang extrahiert werden. Da es keinen offiziellen Weg gibt, ist das Thema sehr umfangreich. Daher behandle ich in diesem Artikel ausschließlich Batch-Loads.
Dazu kommen wir im nächsten Abschnitt. Zunächst müssen wir aber den initialen Datenbestand aus BigQuery nach ClickHouse bringen, um eine Baseline zu schaffen.
BigQuery bietet eine Exportfunktion, die der einfachste Weg ist, um Daten an einen anderen Ort zu bewegen. Sie hat allerdings zwei wesentliche Nachteile: Sie kann jeweils nur eine einzelne Tabelle exportieren, und sie kann ausschließlich GCS als Ziel ansprechen.
Wegen der Beschränkung auf eine Tabelle pro Vorgang ist jetzt ein guter Zeitpunkt, um zu entscheiden, ob wirklich alle Tabellen nach ClickHouse repliziert werden müssen oder welche Teilmenge sich für die Nutzung durch Looker am besten eignet.
Eine schnelle Möglichkeit, alle Tabellen aufzulisten, ist diese Query, die Sie auf Ihr Dataset anwenden – sie liefert Ihnen die komplette Liste. Falls Sie zudem unsicher sind, welche Tabellen besonders häufig genutzt werden, listet Ihnen diese Query die Anzahl der Abfragen pro Tabelle im Dataset auf. Achtung: Diese Abfrage kann erhebliche Kosten verursachen – prüfen Sie also zuerst die Kostenschätzung in der UI und passen Sie ggf. die Anzahl der gescannten Tage an, bevor Sie sie ausführen.
Für den eigentlichen Export ist es am besten, das bq-CLI-Kommando zu verwenden und eine ganze Tabelle zu ziehen. Der Grund: Beim SQL-Befehl "EXPORT DATA…" fallen Verarbeitungs- bzw. Scan-Kosten für die exportierte Datenmenge an – bzw. Slot-Kosten bei Editions. Das CLI-Kommando bzw. der API-Aufruf hingegen exportiert die gesamte Tabelle ohne zusätzliche Kosten.
Wenn Sie nur einen Teil einer Tabelle benötigen – also typischerweise eine Untermenge an Partitionen – gibt es einen Trick mit dem Befehl bq cp: Sie kopieren eine Partition in eine neue Tabelle, die sich dann direkt in ClickHouse laden lässt. Leider unterstützt dieser Befehl weder Wildcards noch mehrere Partitionen gleichzeitig, Sie müssen ihn also pro Partition ausführen. Das lässt sich relativ einfach skripten, der Befehl dazu lautet:
bq cp –append_table=true `<source_project_id>:<source_dataset>.<source_table>$<source_partition_name>` `<target_project_id>.<target_dataset>.<target_table>`
Wenn die Tabelle nicht partitioniert (und nicht riesig) ist, empfehle ich, sie komplett in ClickHouse zu laden und dort per SQL zu bereinigen, damit keine Verarbeitungskosten in BigQuery anfallen.
Wenn Sie für den initialen Export bereit sind, geht es weiter.
Ich werde die Daten im Parquet-Format ausgeben, da es dem Dateisystem von BigQuery am nächsten kommt und sich mit erhaltenen Spaltentypen problemlos in ClickHouse laden lässt.
Der Befehl zum Exportieren einer Tabelle aus BigQuery lautet:
bq extract — destination_format=PARQUET \
<project_id>:<dataset>.<table_name> \
gs://<bucket_name>/<path_and_filename>
(Hinweis: Wenn Sie die Dateien in einen Unterordner ablegen, stellen Sie sicher, dass dieser im Bucket existiert – sonst erhalten Sie eine sehr kryptische Fehlermeldung zu Positional Arguments.)
Sobald eine Tabelle nach GCS exportiert ist, geht es daran, sie in ClickHouse zu laden – und damit setzen wir unseren Weg fort.
Die Initialdaten in ClickHouse laden
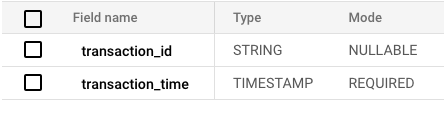
Beim Laden in ClickHouse lautet die offizielle SQL-Abfrage (Stand zum Zeitpunkt dieses Artikels):
CREATE TABLE <table_name>
ENGINE = MergeTree
ORDER BY tuple() AS
SELECT *
FROM S3Cluster(default,
'https://storage.googleapis.com/<bucket_name>/<path>/*.parquet');
Hinweis: In manchen ClickHouse-Versionen gibt es einen Bug, durch den die obige Abfrage fehlschlägt – die Tabelle aber dennoch erstellt wird. Als Workaround führen Sie einfach ein INSERT INTO