Dando sequência
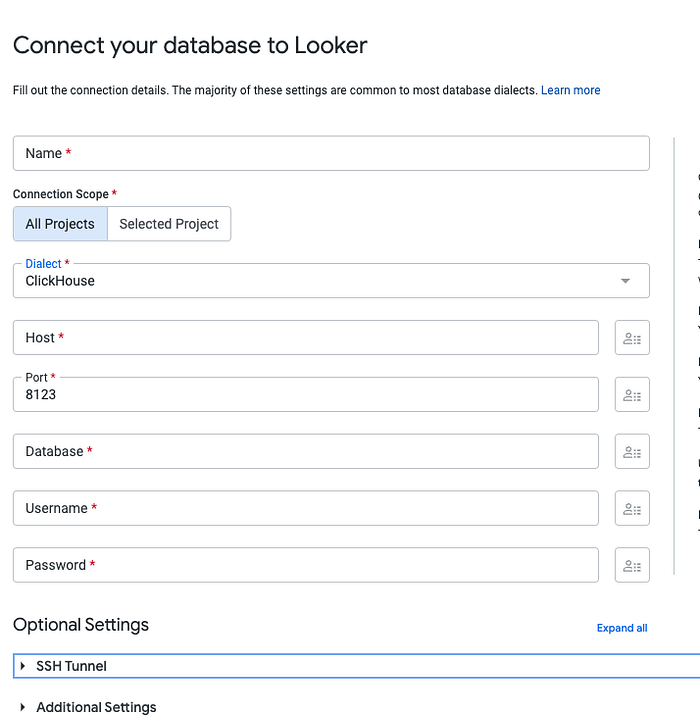
Na seção anterior, mostramos o que esse plano faz na prática e como criar um serviço básico do ClickHouse usando a oferta de DBaaS da Aiven ou do ClickHouse. Nesta seção, vamos começar o processo de levar os dados para o ClickHouse e configurar a replicação entre ele e o BigQuery.
Repositório no GitHub
Ao longo deste artigo, vou fazer referência a uma Cloud Function e a um job do BigQuery. O código-fonte desses dois artefatos está aqui, neste repositório do GitHub.
Vale destacar que esse código foi feito de forma bem simples, com propósito didático. Então é bem provável que você precise customizá-lo para usar de fato no seu cenário real.
Tirando os dados do BigQuery para o ClickHouse
Hoje, não existem métodos automatizados para fazer CDC ou streaming de dados do BigQuery para um destino qualquer. Isso significa que os dados precisam ser capturados antes de serem inseridos no BigQuery ou extraídos depois que já foram inseridos. A falta de um método oficial torna esse assunto bem extenso. Por isso, neste artigo vou abordar apenas as cargas em batch.
Falaremos disso na próxima seção, mas antes precisamos tirar o dataset inicial do BigQuery e levá-lo para o ClickHouse, criando assim nossa base.
O BigQuery tem uma função de exportação que é a forma mais fácil de tirar os dados de lá e levá-los para outro lugar. Mas há duas grandes desvantagens em usá-la: ela só consegue exportar uma única tabela por vez e só aceita o GCS como destino para armazenar os dados.
Por causa dessa limitação de uma tabela por vez, agora é um bom momento para decidir se todas as tabelas precisam ser replicadas para o ClickHouse ou qual subconjunto de tabelas é bom candidato à replicação para uso pelo Looker.
Uma forma rápida de listar todas as tabelas é executar a seguinte query no seu dataset, que vai cuspir a lista inteira para você. Além disso, se você não tem certeza de quais tabelas são mais usadas, esta query vai listar a contagem de queries que atingiram cada tabela do dataset. Atenção: essa query pode custar bastante, então confira a estimativa de custo na UI primeiro e ajuste o número de dias que ela escaneia antes de executá-la.
Na hora de fazer a exportação propriamente dita, a melhor forma é usar o comando bq da CLI e pegar a tabela inteira. Recomendo isso porque o comando SQL "EXPORT DATA…" gera cobranças de processamento/scan referentes ao volume de dados exportados, ou cobranças de slot pela exportação se você usa Editions, enquanto o comando da CLI ou a chamada via API simplesmente despeja a tabela inteira sem cobranças adicionais.
Agora, se você quer apenas parte de uma tabela — normalmente um conjunto de partições —, há um truque com o comando bq cp para copiar uma partição para uma nova tabela que pode ser carregada direto no ClickHouse. Infelizmente, esse comando não funciona com wildcards nem com mais de uma partição por vez, então é preciso rodá-lo por partição. Isso pode ser facilmente automatizado em um script, mas vou deixar o comando aqui:
bq cp –append_table=true `<source_project_id>:<source_dataset>.<source_table>$<source_partition_name>` `<target_project_id>.<target_dataset>.<target_table>`
Se a tabela não for particionada (e não for gigantesca), recomendo carregar a tabela inteira no ClickHouse e fazer a poda lá usando SQL, para não gerar cobranças de processamento no BigQuery.
Quando estiver pronto para fazer a exportação inicial, vamos em frente.
Vou despejar os dados no formato parquet, já que ele é o tipo de arquivo mais próximo do filesystem que o BigQuery usa e é facilmente carregado no ClickHouse com os tipos de coluna preservados.
O comando para exportar uma tabela do BigQuery é:
bq extract — destination_format=PARQUET \
<project_id>:<dataset>.<table_name> \
gs://<bucket_name>/<path_and_filename>
(Observação: se você for colocar os arquivos em uma subpasta, certifique-se de que ela existe no seu bucket; caso contrário, vai aparecer uma mensagem de erro bem confusa sobre argumentos posicionais)
Assim que uma tabela for exportada para o GCS, é hora de carregá-la no ClickHouse — e assim seguimos nossa jornada.
Carregando os dados iniciais no ClickHouse
Para carregar no ClickHouse, a query SQL oficial a executar é esta (no momento em que escrevo):
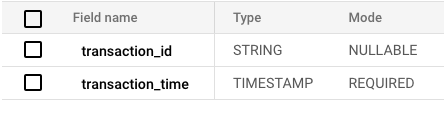
CREATE TABLE <table_name>
ENGINE = MergeTree
ORDER BY tuple() AS
SELECT *
FROM S3Cluster(default,
'https://storage.googleapis.com/<bucket_name>/<path>/*.parquet');
Observação: existe um bug em algumas versões do ClickHouse no qual a query acima falha, mas mesmo assim cria a tabela. Para contornar isso, basta fazer um INSERT INTO