La suite
Dans la partie précédente, nous avons présenté ce que ce plan va concrètement accomplir et comment créer un service ClickHouse de base en s'appuyant sur l'offre DBaaS d'Aiven ou de ClickHouse. Dans cette partie, nous allons amorcer l'ingestion des données dans ClickHouse et mettre en place la réplication entre celui-ci et BigQuery.
Dépôt GitHub
Tout au long de cet article, je ferai référence à une Cloud Function et à un job BigQuery. Le code source de ces deux artefacts se trouve ici, dans ce dépôt GitHub.
Ce code est volontairement très simple et conçu à des fins pédagogiques. Il y a donc de fortes chances qu'il doive être adapté pour répondre à un usage réel correspondant à votre scénario.
Extraire les données de BigQuery vers ClickHouse
Il n'existe à ce jour aucune méthode automatisée pour faire du CDC ou du streaming depuis BigQuery vers une destination arbitraire. Les données doivent donc être soit captées avant leur insertion dans BigQuery, soit extraites après coup. L'absence de méthode officielle fait du sujet un domaine particulièrement vaste. Pour cette raison, je ne couvrirai dans cet article que les chargements en batch.
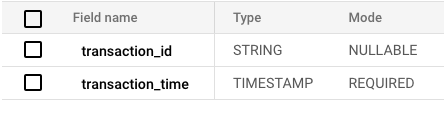
Nous y reviendrons dans la section suivante, mais il faut d'abord extraire le jeu de données initial de BigQuery vers ClickHouse afin d'établir notre référence.
BigQuery dispose d'une fonction d'export, qui constitue le moyen le plus simple d'en extraire les données vers une autre destination. Elle présente toutefois deux inconvénients majeurs : elle ne peut exporter qu'une seule table à la fois, et elle ne peut cibler que GCS pour le stockage.
Compte tenu de cette limitation à une table à la fois, c'est le bon moment pour déterminer si toutes les tables doivent être répliquées dans ClickHouse, ou quel sous-ensemble de tables se prête le mieux à une réplication en vue d'une utilisation par Looker.
Un moyen rapide de lister toutes les tables est d'exécuter la requête suivante sur votre dataset, qui vous renverra la liste complète. De plus, si vous ne savez pas quelles tables sont les plus sollicitées, cette requête listera le nombre de requêtes ayant ciblé chaque table du dataset. Notez que cette requête peut coûter cher : vérifiez d'abord l'estimation de coût dans l'UI puis ajustez le nombre de jours analysés avant de la lancer.
Pour réaliser l'export proprement dit, le mieux est d'utiliser la commande CLI bq pour récupérer une table entière. Je le recommande car la commande SQL EXPORT DATA… entraîne des frais de traitement/scan sur le volume de données exporté, ou des frais de slots si vous utilisez Editions, alors que la commande CLI ou l'appel API se contente de déverser la table entière sans frais supplémentaires.
Si vous ne voulez qu'une partie d'une table, ce qui correspond généralement à un ensemble de partitions, il existe une astuce avec la commande bq cp pour copier une partition vers une nouvelle table qui pourra ensuite être chargée directement dans ClickHouse. Malheureusement, cette commande ne fonctionne ni avec des wildcards ni avec plusieurs partitions à la fois ; il faut donc l'exécuter pour chaque partition. Cela peut être scripté assez facilement, mais voici la commande :
bq cp –append_table=true `<source_project_id>:<source_dataset>.<source_table>$<source_partition_name>` `<target_project_id>.<target_dataset>.<target_table>`
Si la table n'est pas partitionnée (et n'est pas massive), je recommande simplement de la charger entièrement dans ClickHouse et de la filtrer ensuite en SQL afin d'éviter d'engager des frais de traitement sur BigQuery.
Une fois prêt à effectuer l'export initial, poursuivons.
Je vais exporter les données au format parquet : c'est le type de fichier le plus proche du système de fichiers utilisé par BigQuery, et il se charge facilement dans ClickHouse en conservant les types de colonnes intacts.
La commande pour exporter une table depuis BigQuery est :
bq extract — destination_format=PARQUET \
<project_id>:<dataset>.<table_name> \
gs://<bucket_name>/<path_and_filename>
(Petite remarque : si vous placez les fichiers dans un sous-dossier, assurez-vous qu'il existe déjà dans votre bucket, sans quoi vous obtiendrez un message d'erreur très obscur sur les arguments positionnels.)
Une fois la table exportée vers GCS, il est temps de la charger dans ClickHouse — et notre périple continue.
Chargement initial des données dans ClickHouse
Pour le chargement dans ClickHouse, la requête SQL officielle à exécuter est la suivante (au moment de la rédaction) :
CREATE TABLE <table_name>
ENGINE = MergeTree
ORDER BY tuple() AS
SELECT *
FROM S3Cluster(default,
'https://storage.googleapis.com/<bucket_name>/<path>/*.parquet');
Note : certaines versions de ClickHouse présentent un bug qui fait échouer la requête ci-dessus, tout en créant néanmoins la table. Pour contourner le problème, faites simplement un INSERT INTO