Continuemos
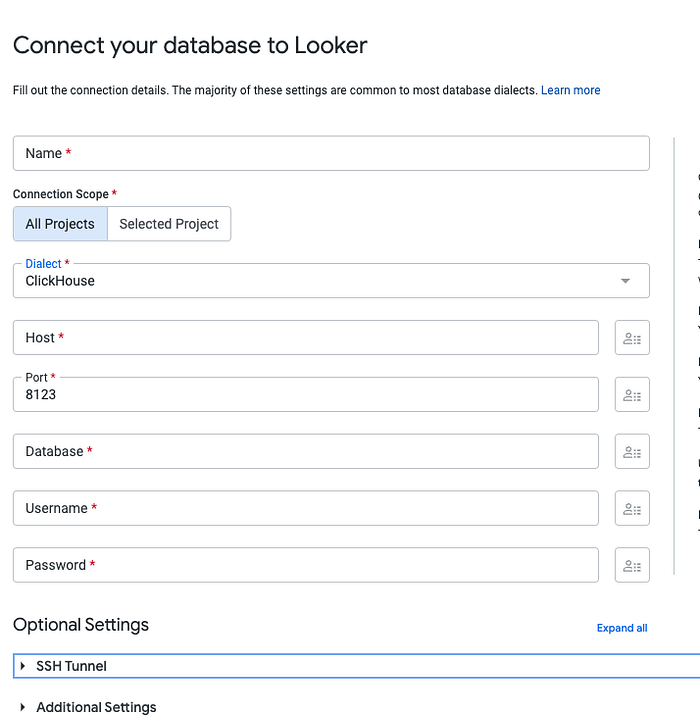
En la sección anterior vimos qué hace este plan en concreto y cómo crear un servicio básico de ClickHouse con la oferta DBaaS de Aiven o de ClickHouse. En esta sección vamos a empezar a llevar los datos a ClickHouse y a configurar la replicación entre este y BigQuery.
Repositorio de GitHub
A lo largo del artículo voy a hacer referencia a una Cloud Function y a un job de BigQuery. El código fuente de ambos se encuentra aquí, en este repositorio de GitHub.
Ten en cuenta que el código es muy simple a propósito y está pensado como material de aprendizaje. Por eso, lo más probable es que tengas que personalizarlo para usarlo en un escenario real.
Cómo sacar los datos de BigQuery hacia ClickHouse
Hoy en día no existen métodos automatizados para hacer CDC o streaming de datos desde BigQuery hacia un destino arbitrario. Esto significa que los datos deben capturarse antes de insertarlos en BigQuery o extraerse después de que se insertaron. La falta de un método oficial hace que este sea un tema bastante extenso. Por eso, en este artículo voy a cubrir únicamente las cargas en batch.
Eso lo veremos en la siguiente sección, pero primero hay que sacar el dataset inicial de BigQuery y llevarlo a ClickHouse para crear nuestra línea base.
BigQuery cuenta con una función de exportación que es la forma más sencilla de mover datos hacia otro lugar. Sin embargo, tiene dos desventajas clave: solo permite exportar una tabla a la vez y solo puede apuntar a GCS para almacenarlos.
Dada esta limitación de una sola tabla a la vez, este es un buen momento para definir si todas las tablas deben replicarse en ClickHouse o cuál subconjunto es buen candidato para replicar y consumir desde Looker.
Una forma rápida de listar todas las tablas es ejecutar la siguiente consulta contra tu dataset, que te devolverá la lista completa. Además, si no tienes claro qué tablas se usan con más frecuencia, esta otra consulta mostrará el conteo de queries que han llegado a cada tabla del dataset. Ten cuidado, porque esta consulta puede salir bastante cara, así que primero revisa la estimación de costo en la UI y ajusta la cantidad de días que escanea antes de ejecutarla.
Cuando llegue el momento de hacer la exportación, lo mejor es usar el comando bq de la CLI y tomar la tabla completa. Lo recomiendo porque usar el comando SQL "EXPORT DATA…" genera cargos de procesamiento/escaneo por la cantidad de datos exportados, o cargos de slots si usas Editions, mientras que el comando de la CLI o la llamada a la API simplemente vuelcan la tabla completa sin cargos adicionales.
Si solo necesitas una parte de la tabla, que normalmente es un conjunto de particiones, hay un truco: usar el comando bq cp para copiar una partición a una nueva tabla y luego cargarla directamente en ClickHouse. Lamentablemente, este comando no admite wildcards ni más de una partición a la vez, así que tienes que ejecutarlo por cada partición. Esto se puede automatizar con un script sin mayor problema, pero igual quiero dejar el comando aquí:
bq cp –append_table=true `<source_project_id>:<source_dataset>.<source_table>$<source_partition_name>` `<target_project_id>.<target_dataset>.<target_table>`
Si la tabla no está particionada (y no es enorme), te recomiendo cargarla completa en ClickHouse y depurarla desde ahí con SQL para no incurrir en cargos de procesamiento en BigQuery.
Cuando estés listo para hacer la exportación inicial, sigamos.
Voy a volcar los datos en formato parquet, ya que es el tipo de archivo más cercano al sistema de archivos que utiliza BigQuery y se carga fácilmente en ClickHouse manteniendo intactos los tipos de columna.
El comando para exportar una tabla desde BigQuery es:
bq extract — destination_format=PARQUET \
<project_id>:<dataset>.<table_name> \
gs://<bucket_name>/<path_and_filename>
(Una nota: si vas a poner los archivos en una subcarpeta, asegúrate de que exista en tu bucket; si no, recibirás un mensaje de error muy poco claro sobre argumentos posicionales.)
Una vez exportada la tabla a GCS, es momento de cargarla en ClickHouse y así seguimos con el recorrido.
Cargar los datos iniciales en ClickHouse
Al cargar en ClickHouse, la consulta SQL oficial a ejecutar es esta (al momento de escribir):
CREATE TABLE <table_name>
ENGINE = MergeTree
ORDER BY tuple() AS
SELECT *
FROM S3Cluster(default,
'https://storage.googleapis.com/<bucket_name>/<path>/*.parquet');
Nota: hay un bug en algunas versiones de ClickHouse en el que la consulta anterior falla, pero igualmente crea la tabla. Para evitarlo, basta con hacer un INSERT INTO