Riprendiamo da dove eravamo
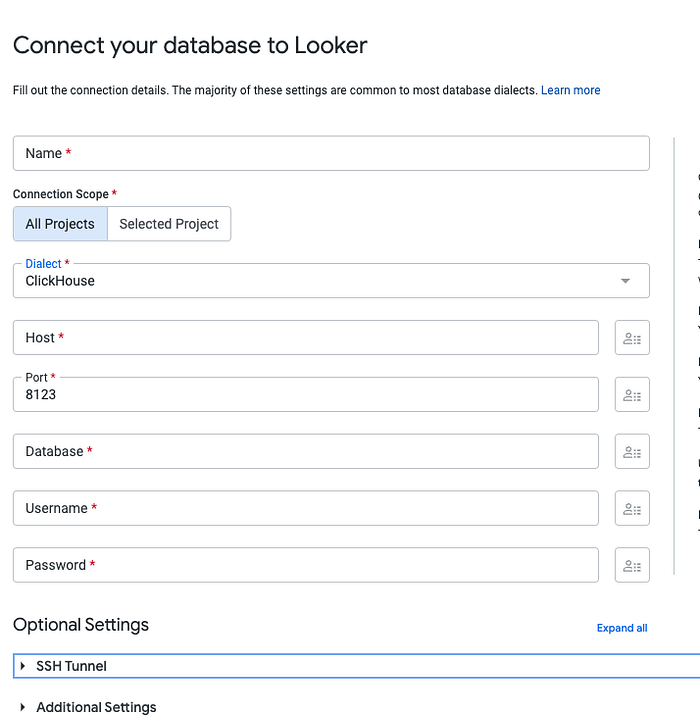
Nella sezione precedente abbiamo visto cosa fa concretamente questo piano e come creare un servizio ClickHouse di base sfruttando l'offerta DBaaS di Aiven o di ClickHouse. In questa sezione passiamo al trasferimento dei dati in ClickHouse e alla configurazione della replica tra ClickHouse e BigQuery.
Repository GitHub
Nel corso dell'articolo farò riferimento a una Cloud Function e a un job di BigQuery. Il codice sorgente di questi due artefatti è disponibile qui, in questo repository GitHub.
Il codice è volutamente molto semplice e pensato a scopo didattico: con ogni probabilità andrà personalizzato per essere utilizzato in uno scenario reale.
Estrarre i dati da BigQuery verso ClickHouse
Al momento non esistono metodi automatizzati per fare CDC o streaming di dati da BigQuery verso una destinazione qualsiasi. Ciò significa che i dati vanno catturati prima dell'inserimento in BigQuery oppure estratti dopo l'inserimento. L'assenza di un metodo ufficiale rende l'argomento piuttosto articolato e per questo, in questo articolo, mi concentrerò solo sui caricamenti batch.
Ne parleremo nella prossima sezione, ma prima dobbiamo estrarre il dataset iniziale da BigQuery e portarlo in ClickHouse per creare la nostra baseline.
BigQuery dispone di una funzione di esportazione che è il modo più semplice per estrarne i dati. Presenta però due svantaggi importanti: può esportare una sola tabella alla volta e può scrivere i dati solo su GCS.
Vista la limitazione di una sola tabella per volta, è il momento giusto per stabilire se replicare in ClickHouse tutte le tabelle oppure quale sottoinsieme rappresenti un buon candidato per la replica e per l'utilizzo da parte di Looker.
Un modo rapido per elencare tutte le tabelle è eseguire questa query sul suo dataset, che ne restituirà l'elenco completo. Inoltre, se non sa con certezza quali tabelle siano usate più di frequente, questa query elencherà il numero di query che hanno colpito ciascuna tabella del dataset. Attenzione: questa query può avere un costo significativo, quindi controlli prima la stima dei costi nell'interfaccia e regoli il numero di giorni da scansionare prima di eseguirla.
Quando si passa all'esportazione vera e propria, il modo migliore è usare il comando CLI bq e prelevare l'intera tabella. Lo consiglio perché il comando SQL "EXPORT DATA…" comporta costi di elaborazione/scansione sul volume di dati esportato, oppure costi di slot se si usano le Editions, mentre il comando CLI o la chiamata API esegue il dump dell'intera tabella senza costi aggiuntivi.
Se invece le serve solo una parte di una tabella — di solito un insieme di partizioni — esiste un trucco: usare il comando bq cp per copiare una partizione in una nuova tabella, caricabile poi direttamente in ClickHouse. Purtroppo questo comando non funziona con i wildcard né con più di una partizione alla volta, quindi va eseguito una partizione per volta. È relativamente facile da automatizzare con uno script, ma riporto comunque il comando:
bq cp –append_table=true `<source_project_id>:<source_dataset>.<source_table>$<source_partition_name>` `<target_project_id>.<target_dataset>.<target_table>`
Se la tabella non è partizionata (e non è enorme), consiglio semplicemente di caricarla per intero in ClickHouse e poi sfoltirla con SQL, così da non incorrere in costi di elaborazione su BigQuery.
Quando è pronto a procedere con l'esportazione iniziale, andiamo avanti.
Esporterò i dati in formato parquet, perché è il tipo di file più vicino al filesystem usato da BigQuery e si carica facilmente in ClickHouse mantenendo intatti i tipi di colonna.
Il comando per esportare una tabella da BigQuery è:
bq extract — destination_format=PARQUET \
<project_id>:<dataset>.<table_name> \
gs://<bucket_name>/<path_and_filename>
(Una nota: se inserisce i file in una sottocartella, verifichi che esista nel suo bucket, altrimenti riceverà un messaggio di errore piuttosto criptico relativo agli argomenti posizionali.)
Una volta esportata la tabella su GCS, è il momento di caricarla in ClickHouse: proseguiamo il nostro percorso.
Caricare i dati iniziali in ClickHouse
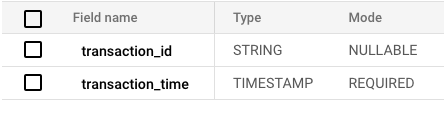
Per caricare i dati in ClickHouse, la query SQL ufficiale da eseguire è la seguente (al momento della stesura):
CREATE TABLE <table_name>
ENGINE = MergeTree
ORDER BY tuple() AS
SELECT *
FROM S3Cluster(default,
'https://storage.googleapis.com/<bucket_name>/<path>/*.parquet');
Nota: in alcune versioni di ClickHouse esiste un bug per cui la query qui sopra fallisce, ma crea comunque la tabella. Per aggirarlo è sufficiente eseguire un INSERT INTO