
Auf der Google Next 2019 in San Francisco hat Google angekündigt, dass Cloud Run in die Beta geht – Grund genug, den Dienst an einer realen Anwendung auf die Probe zu stellen.
Bild: TriggerMesh – Multicloud Serverless Management Platform ( http://triggermesh.com)
Google Cloud Run ist eine Managed-Compute-Plattform, die zustandslose Container automatisch skaliert. Cloud Run ist serverless: Das gesamte Infrastrukturmanagement läuft im Hintergrund, sodass Sie sich auf das Wesentliche konzentrieren können – nämlich darauf, großartige Anwendungen zu bauen. Die Plattform setzt auf Knative auf und lässt Ihnen die Wahl: Container entweder vollständig managed über Cloud Run betreiben oder im eigenen Google Kubernetes Engine Cluster mit Cloud Run auf GKE.
Mein Ziel war es, einen Service auf einem klassischen GKE-Cluster mit Cloud Run zu vergleichen – einmal in der vollständig managed Variante und einmal auf meinem eigenen GKE-Cluster.
Für den Test habe ich Banias ( Code auf GitHub) gewählt – eine Opinionated Serverless Event Analytics Pipeline. Banias besteht aus zwei Teilen:
Frontend – nimmt sämtliche Events der Clients entgegen und schreibt sie in Pub/Sub. Implementiert in Go.
Backend – ein Google Cloud Dataflow, der die Daten aus Pub/Sub validiert, transformiert und nach BigQuery schreibt. Implementiert in Java mit dem Google Dataflow SDK.
Beim Deployment von Banias auf Google Cloud Run bin ich auf zwei Stolpersteine gestoßen:
- Banias nutzt Viper für die Konfiguration. Viper verwendet für jede Umgebungsvariable einen Präfix. Cloud Run nutzt jedoch die Umgebungsvariable PORT, weshalb wir den Code so anpassen mussten, dass er PORT statt BANIAS_PORT auswertet.
- Cloud Run kann nur auf einem einzigen Port lauschen. Banias stellt einen Prometheus-Endpoint zum Scrapen bereit – das ließ sich mit Cloud Run nicht umsetzen.
Ich habe Banias in mehreren Varianten installiert:
- Auf einem GKE-Cluster (Nodes vom Typ n1-standard-4) als "klassisches" Deployment
- Auf einem separaten Cluster (gleiche Node-Konfiguration), aber mit Cloud Run
- In der managed Variante von Cloud Run
Mein Experiment startete mit der Messung der Zeit bis zur ersten verarbeiteten Anfrage (Cold Start):
- GKE ~0,008 Sekunden
- Cloud Run auf GKE ~7 Sekunden
- Cloud Run managed ~7 Sekunden
Für die Lasterzeugung habe ich K6 eingesetzt – ein Open-Source-Lasttest-Tool für Entwickler, geschrieben in Go. Die Testergebnisse habe ich in InfluxDB abgelegt und mit Grafana visualisiert. Den Lasttest haben wir folgendermaßen gestartet:
k6 run — out influxdb=http://x.x.x.x:8086/myk6db — u 2500 — duration 1m — rps 6000 test_file.js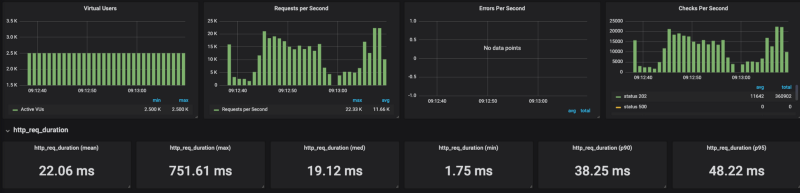 Banias auf GKE
Banias auf GKE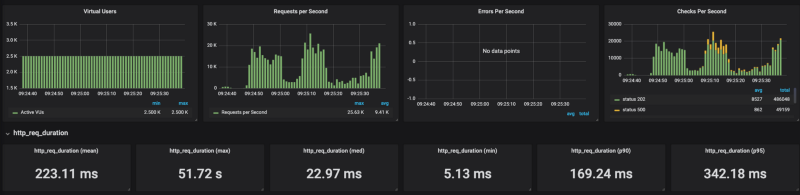 Banias auf der managed Variante von Cloud Run
Banias auf der managed Variante von Cloud Run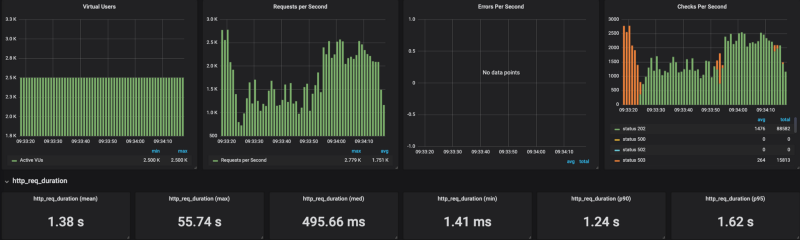 Banias auf Cloud Run auf meinem eigenen GKE-Cluster
Banias auf Cloud Run auf meinem eigenen GKE-Cluster
Die Ergebnisse zeigen: Cloud Run tut sich unter hoher Last mit der Skalierung schwer (ich habe Concurrency-Werte zwischen 80 und 1 durchgetestet – stets mit demselben Ergebnis). Sobald ich die Requests pro Sekunde auf rund 4k RPS begrenzt habe (ohne Limit landete ich bei 20K RPS), kam Cloud Run damit recht gut zurecht.
workloads auf Cloud Run auszurollen ist denkbar einfach – aktuell laufen aber nicht alle Arten von workloads und Lastprofilen effizient auf der Plattform.
Lust auf mehr? Schauen Sie in unseren Blog oder folgen Sie Aviv auf Twitter.