
Lors de la conférence Google Next 2019 à San Francisco, Google a annoncé le passage de Cloud Run en Beta. L'occasion idéale de le mettre à l'épreuve sur une application réelle.
Image par TriggerMesh — Multicloud Serverless Management Platform ( http://triggermesh.com)
Google Cloud Run est une plateforme de calcul managée qui met automatiquement à l'échelle vos conteneurs sans état. Cloud Run est serverless : la plateforme prend en charge toute la gestion de l'infrastructure, ce qui vous permet de vous concentrer sur l'essentiel — concevoir d'excellentes applications. Bâti sur Knative, il vous laisse le choix d'exécuter vos conteneurs en mode entièrement managé avec Cloud Run, ou directement dans votre cluster Google Kubernetes Engine via Cloud Run sur GKE.
Je voulais comparer un service tournant sur un cluster GKE classique avec Cloud Run, à la fois dans sa version entièrement managée et dans celle déployée sur mon propre cluster GKE.
Pour ce test, j'ai choisi Banias ( code sur Github), un Opinionated Serverless Event Analytics Pipeline. Banias se compose de deux parties :
Frontend — reçoit tous les événements des clients et les écrit dans Pub/Sub. Il est développé en Go.
Backend — un Google Cloud Dataflow qui valide et transforme les données issues de Pub/Sub avant de les écrire dans BigQuery. Il est développé en Java avec le SDK Google Dataflow.
J'ai rencontré deux difficultés en déployant Banias sur Google Cloud Run :
- Banias s'appuie sur Viper pour sa configuration. Viper applique un préfixe à chaque variable d'environnement. Or Cloud Run utilise la variable d'environnement PORT : nous avons donc dû modifier notre code pour qu'il recherche PORT et non BANIAS_PORT.
- Cloud Run ne peut écouter que sur un seul port. Banias expose un endpoint Prometheus pour le scraping, ce qui n'a pas fonctionné sur Cloud Run.
J'ai installé Banias selon plusieurs configurations :
- Sur un cluster GKE (nœuds n1-standard-4) en déploiement classique
- Sur un cluster distinct (même configuration de nœuds), mais via Cloud Run
- Sur la version managée de Cloud Run
L'expérimentation a démarré par la mesure du temps de traitement de la première requête (autrement dit, le cold start) :
- GKE ~0,008 seconde
- Cloud Run sur GKE ~7 secondes
- Cloud Run managé ~7 secondes
Pour générer la charge, j'ai utilisé K6 — un outil open source de tests de charge orienté développeurs et écrit en Go. J'ai stocké les résultats dans InfluxDB et les ai visualisés avec Grafana. Pour lancer la génération de charge, nous avons exécuté K6 ainsi :
k6 run — out influxdb=http://x.x.x.x:8086/myk6db — u 2500 — duration 1m — rps 6000 test_file.js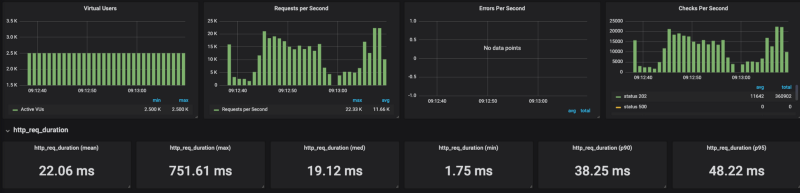 Banias sur GKE
Banias sur GKE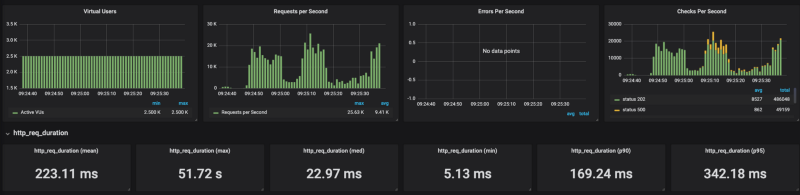 Banias sur la version managée de Cloud Run
Banias sur la version managée de Cloud Run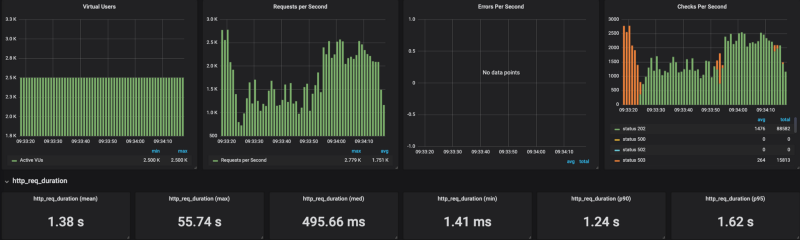 Banias sur Cloud Run dans mon propre cluster GKE
Banias sur Cloud Run dans mon propre cluster GKE
Les résultats le montrent : Cloud Run peine à monter en charge sous forte sollicitation (j'ai testé toute une plage de paramètres de concurrence, de 80 à 1, avec les mêmes résultats). Lorsque j'ai plafonné le nombre de requêtes par seconde (sans plafond, on atteint 20 000 RPS) autour de 4 000 RPS, Cloud Run s'en est plutôt bien sorti.
Déployer des workloads sur Cloud Run est très simple. Cela dit, pour l'instant, tous les types de workloads et de charges n'y tournent pas efficacement.
Envie de lire d'autres articles ? Consultez notre blog, ou suivez Aviv sur Twitter.