
En la conferencia Google Next 2019, en San Francisco, Google anunció que Cloud Run pasó a Beta, así que me pareció un buen momento para ponerlo a prueba con una aplicación real.
Imagen de TriggerMesh — Multicloud Serverless Management Platform ( http://triggermesh.com)
Google Cloud Run es una plataforma de cómputo administrada que escala automáticamente tus contenedores stateless. Cloud Run es serverless: abstrae toda la gestión de la infraestructura para que te enfoques en lo que de verdad importa: construir grandes aplicaciones. Está construido sobre Knative, lo que te permite elegir entre ejecutar tus contenedores totalmente administrados con Cloud Run o en tu propio cluster de Google Kubernetes Engine con Cloud Run en GKE.
Quería comparar un servicio corriendo en un cluster GKE estándar frente a Cloud Run, tanto en la versión totalmente administrada como en la que corre sobre mi propio cluster de GKE.
Para poner a prueba Cloud Run, decidí usar Banias ( código en Github), un Opinionated Serverless Event Analytics Pipeline. Banias se compone de dos partes:
Frontend: recibe todos los eventos de los clientes y los escribe en Pub/Sub. Está implementado en Go.
Backend: un Google Cloud Dataflow que valida y transforma los datos de Pub/Sub y los escribe en BigQuery. Está implementado en Java con el SDK de Google Dataflow.
Me topé con dos problemas al intentar desplegar Banias en Google Cloud Run:
- Banias usa Viper para la configuración. Viper utiliza un prefijo para cada variable de entorno, pero Cloud Run usa la variable de entorno PORT, así que tuvimos que modificar el código para que buscara PORT y no BANIAS_PORT.
- Cloud Run solo puede escuchar en un puerto. Banias expone un endpoint de Prometheus para scraping, y eso no funcionó en Cloud Run.
Instalé Banias en distintas implementaciones:
- En un cluster de GKE (nodos n1-standard-4) como un deployment "normal"
- Un cluster aparte (con la misma configuración de nodos) pero usando Cloud Run
- La versión administrada de Cloud Run
El experimento arrancó midiendo el tiempo que tarda en atenderse la primera solicitud (es decir, el cold start):
- GKE ~0.008 segundos
- Cloud Run en GKE ~7 segundos
- Cloud Run administrado ~7 segundos
Para generar carga utilicé K6, una herramienta open source de pruebas de carga pensada para developers y escrita en Go. Opté por almacenar los resultados en InfluxDB y visualizarlos con Grafana. Para empezar a generar carga, ejecutamos K6 así:
k6 run — out influxdb=http://x.x.x.x:8086/myk6db — u 2500 — duration 1m — rps 6000 test_file.js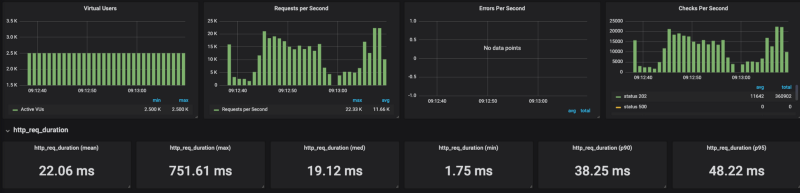 Banias en GKE
Banias en GKE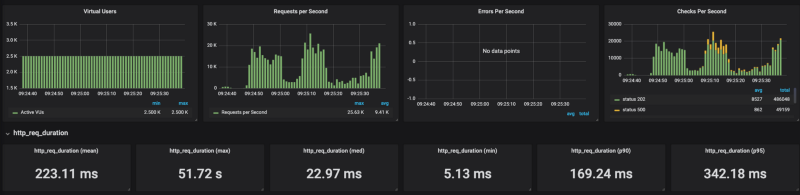 Banias en la versión administrada de Cloud Run
Banias en la versión administrada de Cloud Run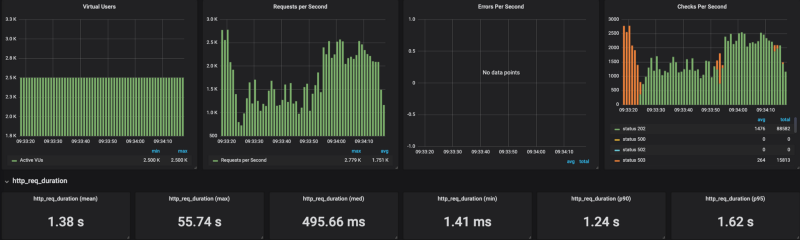 Banias en Cloud Run sobre mi propio cluster de GKE
Banias en Cloud Run sobre mi propio cluster de GKE
Como se ve en los resultados, a Cloud Run le cuesta escalar bajo cargas pesadas (lo probé con distintos ajustes de concurrencia, de 80 a 1, con los mismos resultados). Al limitar las solicitudes por segundo a alrededor de 4K RPS (sin límites llega a 20K RPS), Cloud Run respondió bastante bien.
Desplegar workloads en Cloud Run es muy sencillo; sin embargo, por ahora no todos los tipos de workloads ni todos los niveles de carga corren de forma eficiente en Cloud Run.
¿Quieres leer más historias? Visita nuestro blog o sigue a Aviv en Twitter.