
Na conferência Google Next 2019, em São Francisco, o Google anunciou que o Cloud Run entrou em Beta, então achei que era hora de colocá-lo à prova com uma aplicação real.
Imagem da TriggerMesh — Multicloud Serverless Management Platform ( http://triggermesh.com)
O Google Cloud Run é uma plataforma de computação gerenciada que escala automaticamente seus contêineres stateless. O Cloud Run é serverless: abstrai todo o gerenciamento de infraestrutura para você focar no que realmente importa — desenvolver ótimas aplicações. Ele é construído sobre o Knative, o que permite rodar seus contêineres de forma totalmente gerenciada no Cloud Run ou no seu próprio cluster do Google Kubernetes Engine com o Cloud Run no GKE.
Eu queria comparar um serviço rodando em um cluster GKE comum com o Cloud Run, tanto na versão totalmente gerenciada quanto na versão rodando no meu próprio cluster GKE.
Para testar o Cloud Run, escolhi o Banias ( código no Github), que é um Opinionated Serverless Event Analytics Pipeline. O Banias tem duas partes:
Frontend — recebe todos os eventos dos clientes e os grava no Pub/Sub. O frontend é feito em Go.
Backend — um Google Cloud Dataflow que valida e transforma os dados do Pub/Sub e os grava no BigQuery. O backend é feito em Java com o Google Dataflow SDK.
Esbarrei em dois problemas ao tentar fazer o deploy do Banias no Google Cloud Run:
- O Banias usa o Viper para configuração. O Viper usa um prefixo para cada variável de ambiente. Só que o Cloud Run usa a variável de ambiente PORT, então tivemos que ajustar o código para procurar por PORT, e não por BANIAS_PORT.
- O Cloud Run só consegue escutar em uma porta. O Banias expõe um endpoint Prometheus para scraping, e isso não funcionou no Cloud Run.
Instalei o Banias em diferentes cenários:
- Em um cluster GKE (nós n1-standard-4) como um deployment "normal"
- Em um cluster separado (com a mesma configuração de nós), mas usando o Cloud Run
- Na versão gerenciada do Cloud Run
O experimento começou medindo o tempo até a primeira requisição ser processada (ou seja, o cold start):
- GKE ~0,008 segundo
- Cloud Run no GKE ~7 segundos
- Cloud Run gerenciado ~7 segundos
Para gerar carga, usei o K6 — uma ferramenta open source de teste de carga voltada para desenvolvedores, escrita em Go. Optei por armazenar os resultados dos testes no InfluxDB e visualizá-los no Grafana. Para começar a gerar carga, rodamos o K6 da seguinte forma:
k6 run — out influxdb=http://x.x.x.x:8086/myk6db — u 2500 — duration 1m — rps 6000 test_file.js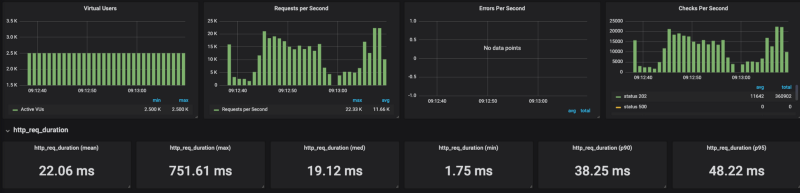 Banias no GKE
Banias no GKE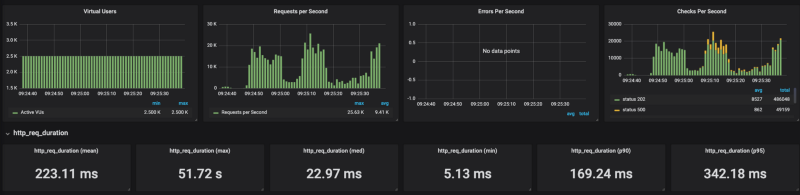 Banias na versão gerenciada do Cloud Run
Banias na versão gerenciada do Cloud Run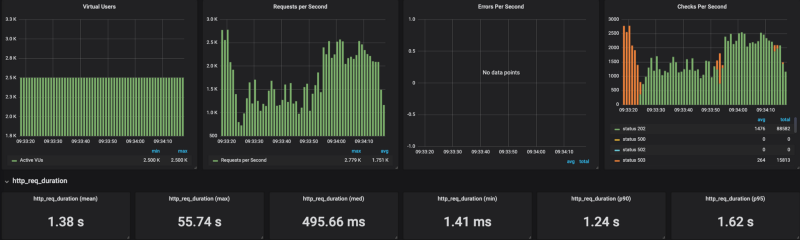 Banias no Cloud Run no meu próprio cluster GKE
Banias no Cloud Run no meu próprio cluster GKE
Como dá para ver nos resultados, o Cloud Run sofre para escalar sob carga pesada (testei com várias configurações de concorrência, de 80 a 1, sempre com o mesmo resultado). Quando limitei o número de requisições por segundo (sem limites, o resultado chegou a 20K RPS) para algo em torno de 4k RPS, o Cloud Run deu conta razoavelmente bem.
Fazer o deploy de workloads no Cloud Run é muito fácil, mas, por enquanto, nem todos os tipos de workloads e cargas conseguem rodar de forma eficiente nele.
Quer mais conteúdos? Confira nosso blog ou siga o Aviv no Twitter.