
Al Google Next 2019 di San Francisco, Google ha annunciato il passaggio di Cloud Run in Beta: il momento giusto, ho pensato, per metterlo alla prova su un'applicazione reale.
Immagine di TriggerMesh — Multicloud Serverless Management Platform ( http://triggermesh.com)
Google Cloud Run è una piattaforma di calcolo gestita che scala automaticamente i container stateless. Cloud Run è serverless: astrae completamente la gestione dell'infrastruttura, lasciando spazio a ciò che conta davvero — sviluppare applicazioni di qualità. È costruito su Knative e permette di scegliere se eseguire i container in modalità completamente gestita con Cloud Run, oppure nel proprio cluster Google Kubernetes Engine con Cloud Run su GKE.
Volevo confrontare un servizio in esecuzione su un cluster GKE "vanilla" con Cloud Run, sia nella versione completamente gestita sia in quella eseguita sul mio cluster GKE.
Per la prova ho deciso di usare Banias ( codice su Github), una Opinionated Serverless Event Analytics Pipeline. Banias è composto da due parti:
Frontend — riceve tutti gli eventi dai client e li scrive su Pub/Sub. È implementato in Go.
Backend — un Google Cloud Dataflow che valida e trasforma i dati provenienti da Pub/Sub e li scrive in BigQuery. È implementato in Java con il Google Dataflow SDK.
Nel deploy di Banias su Google Cloud Run mi sono imbattuto in due problemi:
- Banias usa Viper per la propria configurazione. Viper assegna un prefisso a ogni variabile d'ambiente, ma Cloud Run usa la variabile d'ambiente PORT: abbiamo quindi dovuto modificare il codice perché cercasse PORT anziché BANIAS_PORT.
- Cloud Run può ascoltare su una sola porta. Banias espone un endpoint Prometheus per lo scraping, e questo su Cloud Run non ha funzionato.
Ho installato Banias in diverse configurazioni:
- Su un cluster GKE (nodi n1-standard-4) come deployment "normale"
- Su un cluster separato (stessa configurazione dei nodi) ma usando Cloud Run
- Sulla versione gestita di Cloud Run
Il primo test ha misurato il tempo necessario per servire la prima richiesta (il cosiddetto cold start):
- GKE ~0,008 secondi
- Cloud Run su GKE ~7 secondi
- Cloud Run gestito ~7 secondi
Per generare il carico ho usato K6 — strumento di load testing open source orientato agli sviluppatori e scritto in Go. Ho scelto di salvare i risultati dei test in InfluxDB e di visualizzarli con Grafana. Per avviare la generazione del carico abbiamo lanciato K6 così:
k6 run — out influxdb=http://x.x.x.x:8086/myk6db — u 2500 — duration 1m — rps 6000 test_file.js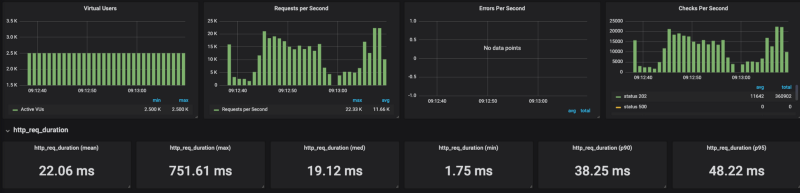 Banias su GKE
Banias su GKE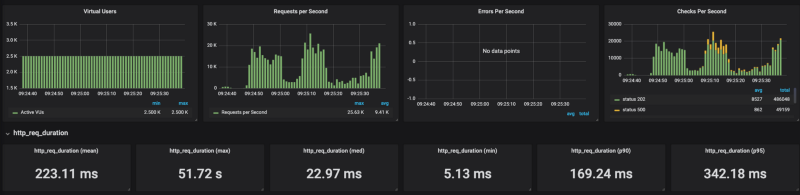 Banias sulla versione gestita di Cloud Run
Banias sulla versione gestita di Cloud Run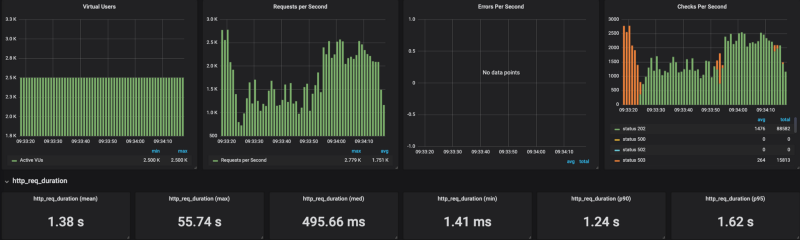 Banias su Cloud Run sul mio cluster GKE
Banias su Cloud Run sul mio cluster GKE
Come mostrano i risultati, Cloud Run fatica a scalare sotto carichi elevati (ho provato diverse impostazioni di concorrenza, da 80 a 1, con esiti analoghi). Limitando le richieste al secondo a circa 4k RPS (senza limiti si arriva a 20K RPS), Cloud Run è riuscito invece a reggere il carico in modo più che dignitoso.
Distribuire workloads su Cloud Run è davvero semplice; tuttavia, almeno per ora, non tutti i tipi di workloads e di carichi vi girano in modo efficiente.
Vuoi leggere altre storie? Dai un'occhiata al nostro blog oppure segui Aviv su Twitter.