So nutzen Sie GKE Cost Allocation zusammen mit den Cost-Allocation-Funktionen in DoiT Cloud Intelligence™, um Ihre GKE-Ausgaben bis ins Detail aufzuschlüsseln.

Ausreichend Kostentransparenz für Kubernetes-Ausgaben zu schaffen, ist eine Herausforderung, die so alt ist wie Kubernetes selbst.
Die dynamische Ressourcenzuweisung und die kurze Lebensdauer von Containern erschweren es, Kosten einzelnen Anwendungen oder Services zuzuordnen. Hinzu kommt, dass viele Ressourcen von verschiedenen Komponenten gemeinsam genutzt werden.
Trotzdem ist Kostentransparenz in Kubernetes entscheidend für ein wirksames Ressourcen- und Kostenmanagement.
Um genau hier anzusetzen, hat Google Cloud Ende letzten Jahres GKE Cost Allocation veröffentlicht – ein Feature, das Kunden eine detaillierte Aufschlüsselung ihrer Cluster-Kosten liefert.
In diesem Beitrag zeigen wir, was GKE Cost Allocation leistet und wie Sie die Daten zusammen mit den Cost-Allocation-Funktionen in DoiT Cloud Intelligence einsetzen, um Ihre GKE-Ausgaben granular auszuwerten.
Konkret zeigen wir am Beispiel eines fiktiven Gaming-Unternehmens, wie sich GKE-Kosten den einzelnen Spielen zuordnen lassen, wie sich gemeinsam genutzte Kosten unter den Spielen aufteilen und wie sich die Kosten je Spiel anschließend nach Umgebung aufschlüsseln lassen.
Was ist GKE Cost Allocation
GKE Cost Allocation ist die von Google Cloud empfohlene Methode, um an Cluster-Abrechnungsinformationen zu kommen. Im Vergleich zum Vorgänger GKE Usage Metering lassen sich Cluster-Kosten mit GKE Cost Allocation deutlich einfacher Nutzern zuordnen. Außerdem können Sie Cluster- und Namespace-Kosten gemeinsam mit anderen Google-Cloud-Servicekosten betrachten – was mit Usage Metering nicht möglich war. Google Cloud plant zudem, GKE Usage Metering damit künftig vollständig abzulösen.
Die Aktivierung von GKE Cost Allocation ist verglichen mit GKE Usage Metering deutlich unkomplizierter: Es genügt ein gcloud-Befehl oder ein Häkchen pro Cluster in der Google Cloud Console. Nach der Aktivierung wird ein BQ-Dataset erstellt, das Metriken zu CPU, Speicherverbrauch und Festplatten der in den Clustern laufenden workloads enthält.
So lassen sich Cluster- und Namespace-Kosten – sowie Informationen zu Ressourcen mit GKE Labels – komfortabel auswerten.
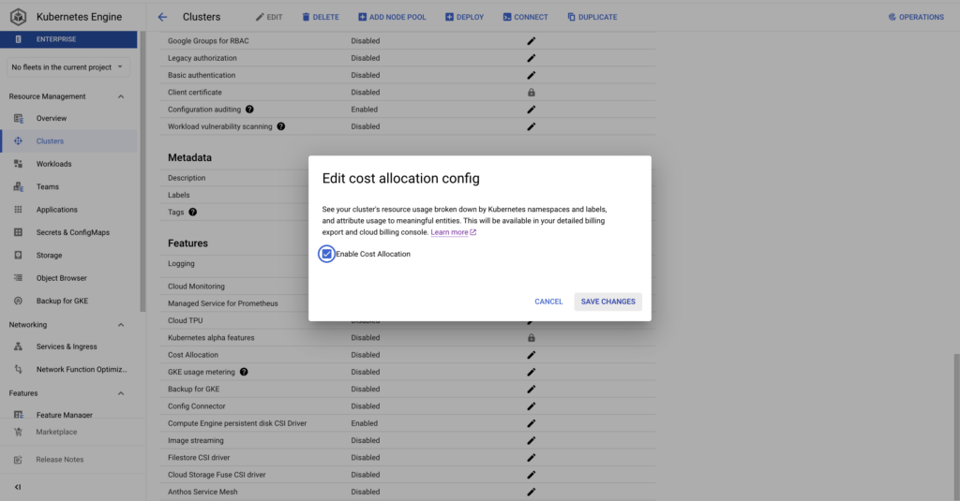
Ist GKE Cost Allocation in Ihren Clustern aktiv, können Sie Fragen wie diese beantworten:
- Welcher Tenant verursacht welchen Anteil meiner Cluster-Kosten?
- Wie verhalten sich meine Out-of-Cluster-Kosten (CloudSQL, GCS usw.) zu den In-Cluster-Kosten?
- Was kostet mich meine Backend-Anwendung?
Sobald aktiviert, fließen die granularen Abrechnungsinformationen zu Ihren Cluster- und Namespace-Kosten zusätzlich in DoiT Cloud Intelligence ein – und ermöglichen dort komplexere Cost-Allocation-Szenarien. Sehen wir uns ein konkretes Beispiel an.

GKE-Kosten den passenden Geschäftsbereichen zuordnen
Der erste Schritt jeder Cost Allocation: die Geschäftsbereiche festlegen, denen Sie Kosten zuordnen möchten. In DoiT Cloud Intelligence machen Sie das über Attributions. Damit gruppieren Sie Cloud-Ressourcen und strukturieren Kosten genau so, wie es Ihrer Allokationslogik entspricht.
Stellen wir uns ein fiktives Gaming-Unternehmen vor, das mehrere Spiele für seine Nutzer anbietet.
Wir möchten Ressourcen den verschiedenen Spielen sowie den Umgebungen zuordnen, in denen diese Spiele laufen.
Im Beispiel unten haben wir alle GKE-Kosten zu einem unserer Spiele – einem Action-Game – über jeden Namespace definiert, der das Wort "action" enthält. Mit Regex erfassen wir auf diese Weise auch alle künftig neu angelegten action-bezogenen Namespaces, ohne die Attribution manuell pflegen zu müssen.
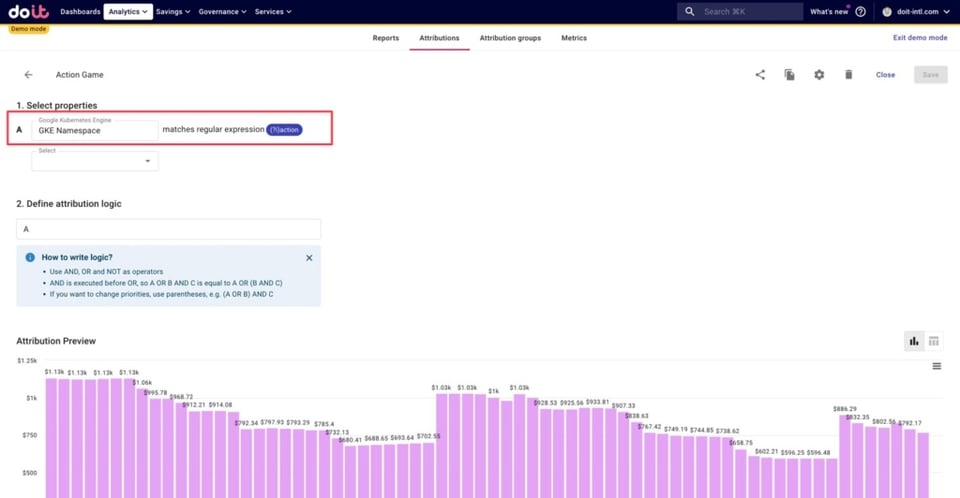
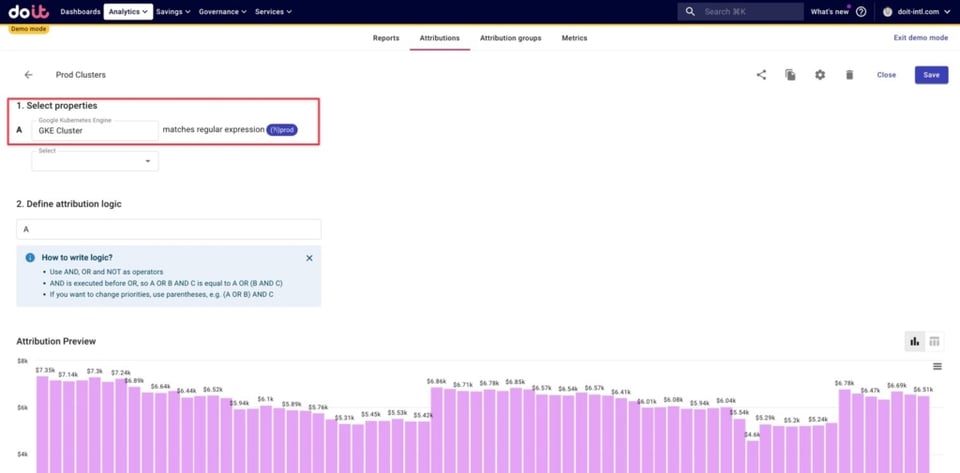
Zusätzlich haben wir Cluster für Produktionsumgebungen sowie für Dev-, Staging- und Beta-Umgebungen definiert. Unten sehen Sie ein Beispiel, wie wir Produktionscluster definieren – per Regex erfassen wir alle Cluster, deren Namen das Wort "prod" enthalten.
Geschäftsgruppierungen sinnvoll organisieren
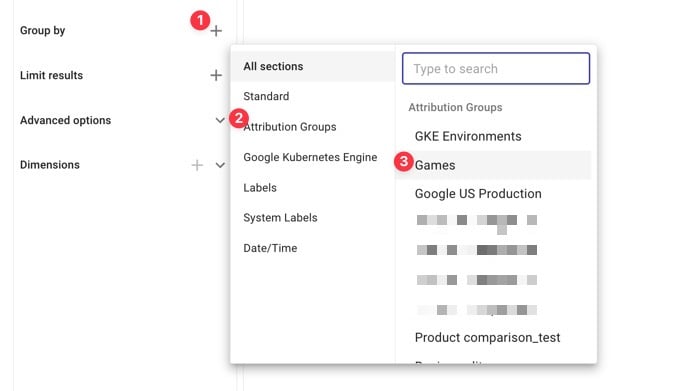
Als Nächstes fassen wir zusammengehörige Attributions in Attribution Groups zusammen. Mit diesen Gruppen können wir gemeinsam genutzte Kosten aufteilen, aber auch eine Attribution-Menge nach einer anderen aufschlüsseln. Beides setzen wir im nächsten Abschnitt um.
Wir haben eine "Games"-Attribution-Group erstellt, die folgende Attributions enthält:
- Vier Spiele unseres fiktiven Unternehmens
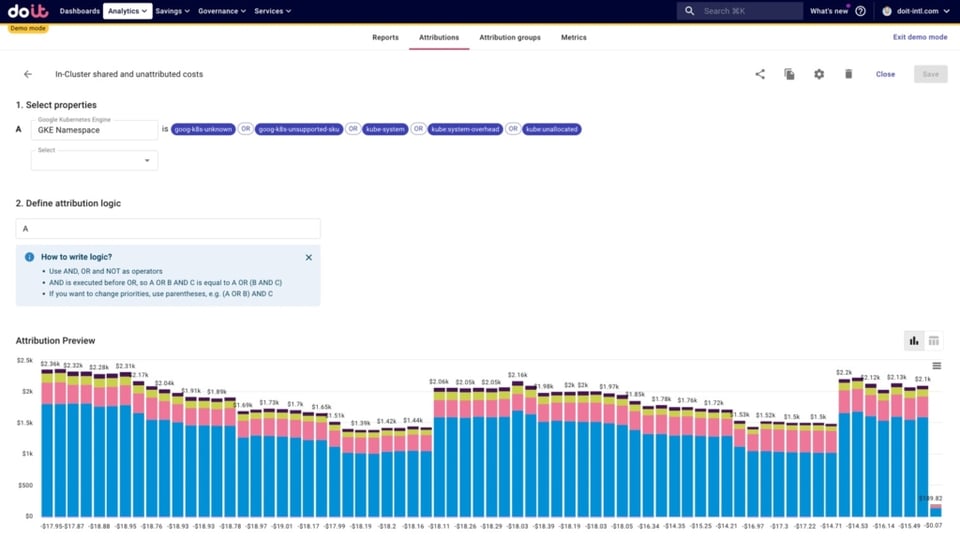
- Geteilte In-Cluster- und nicht zugeordnete Kosten, darunter:
- kube:system und kube:system-overhead: K8s-Systemkomponenten/-Namespaces. (kube-system ist der Namespace, und Google liefert zusätzlich diese Metrik, die den Overhead abbildet.)
- kube:unallocated: Ressourcen, die weder von workloads noch für System-Overhead angefordert werden.
- goog-k8s-unknown: ein Fehlerfall der Cost Allocation – etwa wenn eine neue Compute-VM hochgefahren wird oder der Cluster skaliert (SKU konnte nicht verarbeitet werden).
- goog-k8s-unsupported-sku – existierende, aber nicht unterstützte SKUs (z. B. E2-Instanzen)
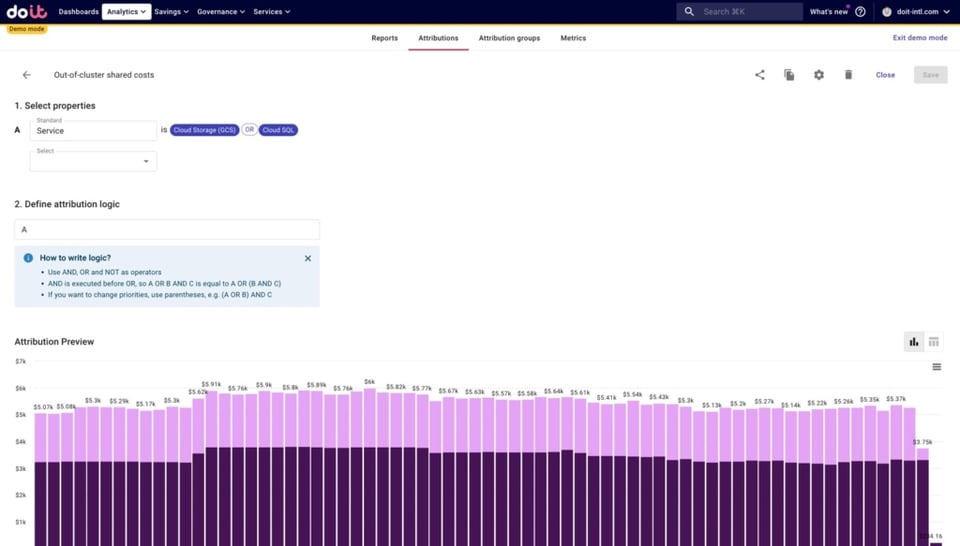
- Out-of-Cluster Shared Costs: Kosten für Nicht-Kubernetes-Ressourcen, die in Google Cloud außerhalb von Kubernetes laufen und von den auf dem Cluster deployten Apps genutzt werden
- Datenbanken wie Cloud SQL oder BigQuery
- Object Storage wie Google Cloud Storage
- Message Queues wie Pub/Sub, Kafka usw.
- Alles, was die obigen Attributions nicht erfassen
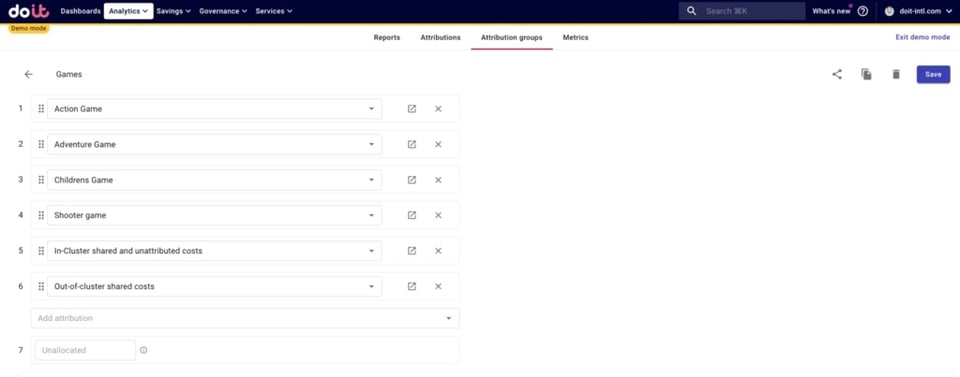
Die Nicht-Spiele-Attributions binden wir ein, weil es sich um geteilte Kosten handelt, die wir im nächsten Schritt unter den Spielen aufteilen wollen.
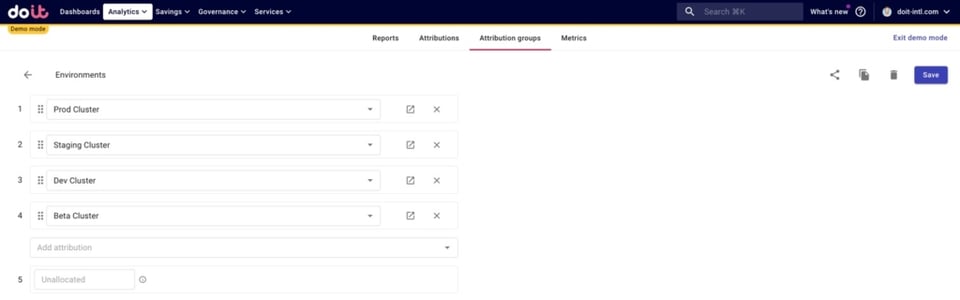
Analog haben wir eine Attribution Group für alle unsere Umgebungen erstellt.
Das ist sinnvoll: Wenn wir die geteilten Kosten unter unseren Spielen aufgeteilt haben, wollen wir wissen, wie viel je Umgebung und je Spiel anfällt.
Geteilte In-Cluster- und Out-of-Cluster-Kosten aufteilen
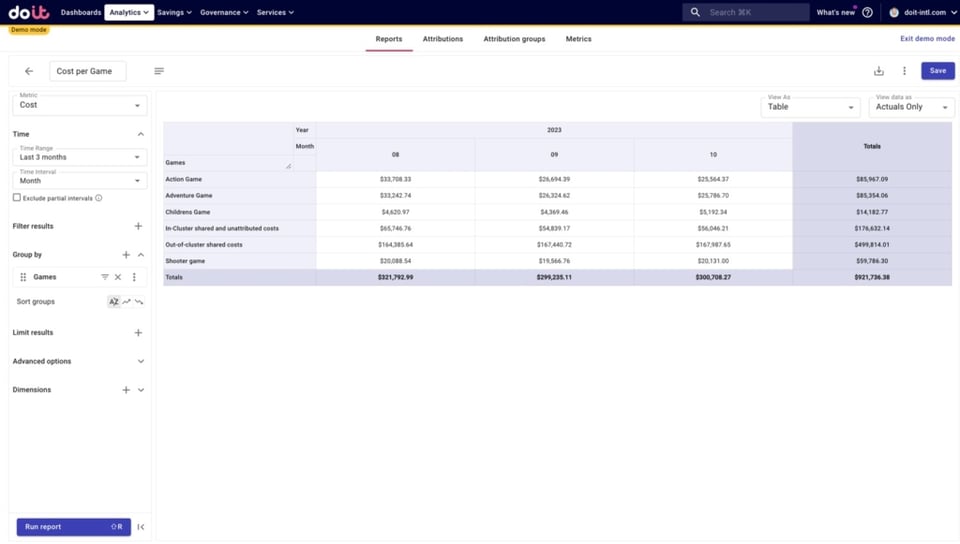
Zunächst erstellen wir einen Report, der die Attribution Group mit unseren Spielen und geteilten Kosten zeigt.
Dazu gehen wir wie folgt vor:
Anschließend teilen wir unsere beiden Blöcke geteilter Kosten – geteilte und nicht zugeordnete In-Cluster-Kosten und geteilte Out-of-Cluster-Kosten – auf die Spiele auf.
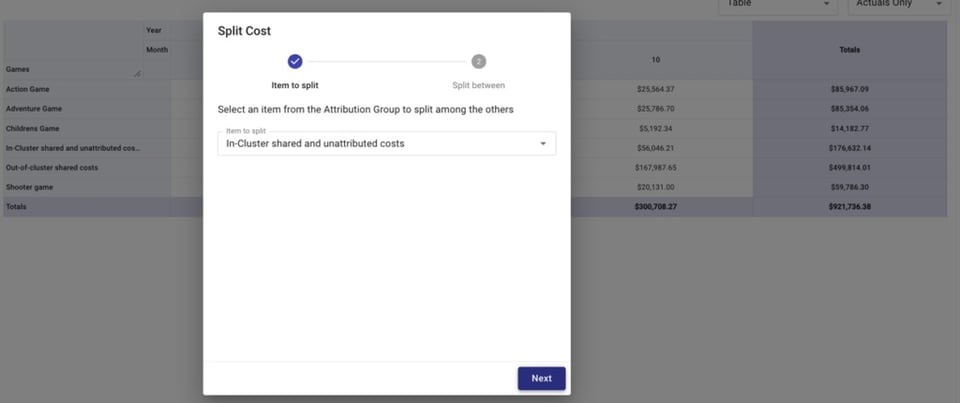
Die Aufteilung kann gleichmäßig erfolgen, proportional zum Anteil eines Spiels an den Gesamtkosten oder über einen individuell festgelegten Wert.
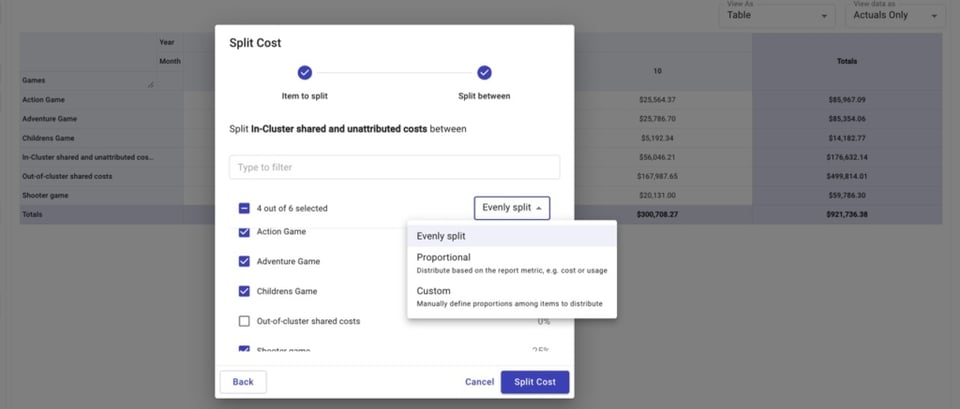
Danach sehen wir für jedes Spiel:
- Die Kosten für den Betrieb des Spiels
- Seinen Anteil an geteilten, In-Cluster- bzw. nicht zugeordneten Kosten
- Seinen Anteil an geteilten Out-of-Cluster-Kosten
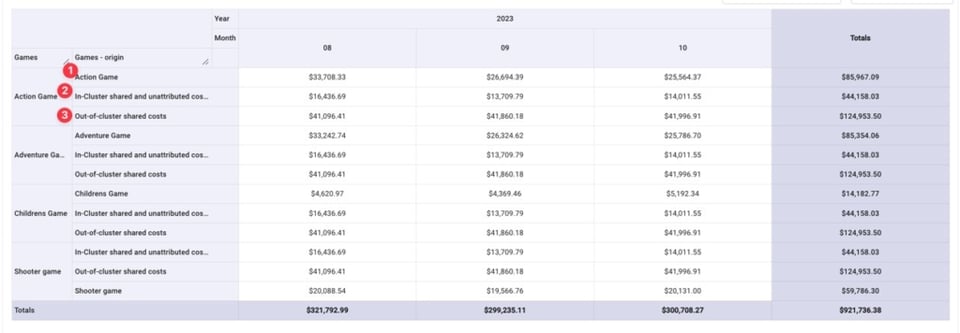
Zur Vereinfachung fassen wir alle drei Positionen unter den Gesamtkosten je Spiel zusammen.
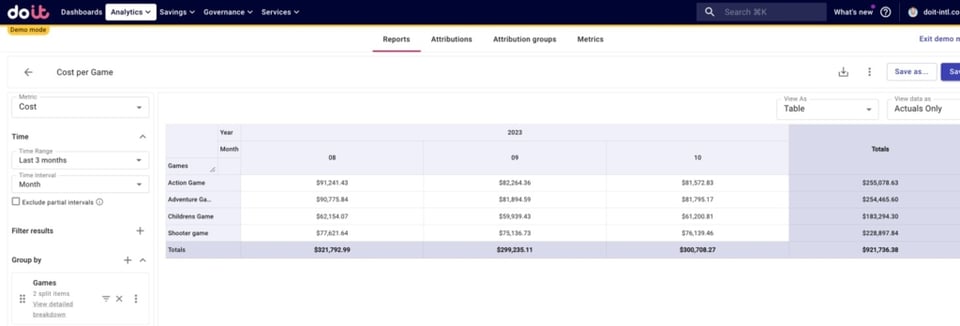
Spielkosten nach Umgebung aufschlüsseln
Jetzt können wir auswerten, wie sich die Gesamtkosten jedes Spiels auf die einzelnen Umgebungen verteilen, indem wir unsere "GKE Environments"-Attribution-Group in die Aufschlüsselung aufnehmen.
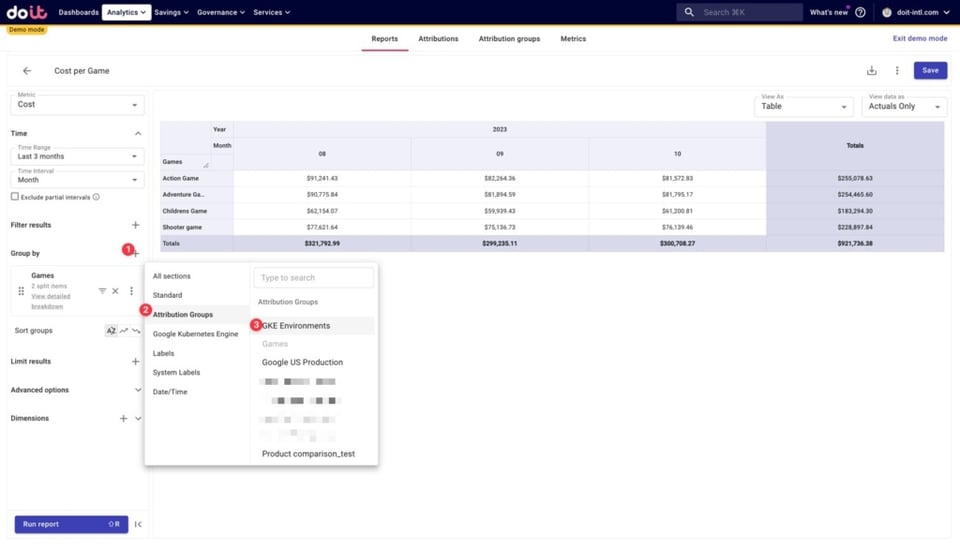
Im Folgenden sehen wir, wie sich die Kosten jedes Spiels auf die zuvor angelegten Umgebungs-Attributions verteilen – sowie auf etwaige nicht zugeordnete Kosten. Diese stammen aus Ressourcen, die in keiner der hier verwendeten Attributions in den Attribution Groups erfasst sind.
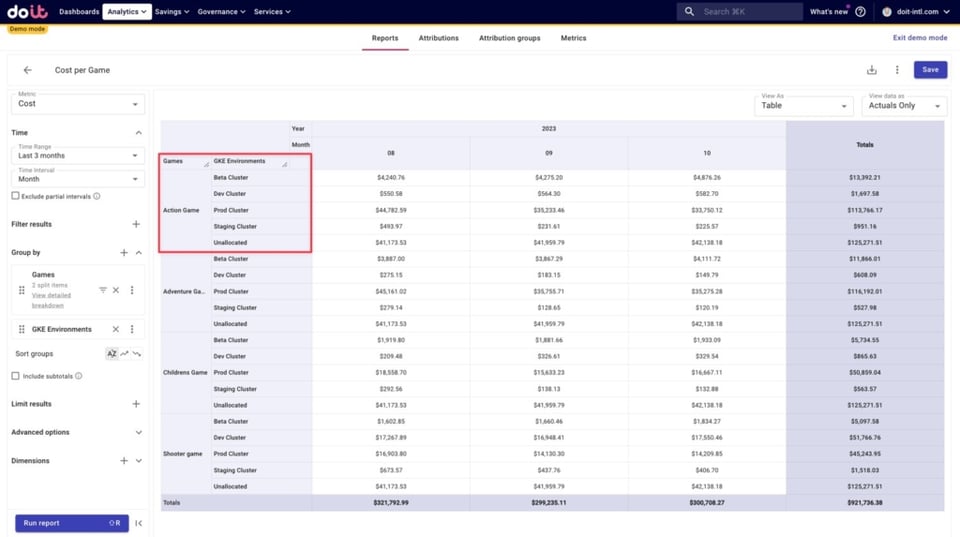
Wir können diesen nicht zugeordneten Kosten auf den Grund gehen und bestehende Attributions ggf. so anpassen, dass die betroffenen Ressourcen einbezogen werden.
Filtern wir unten ausschließlich nach nicht zugeordneten Kosten in der "GKE Environments"-Attribution-Group und ergänzen wir "Service" in unserer Aufschlüsselung.
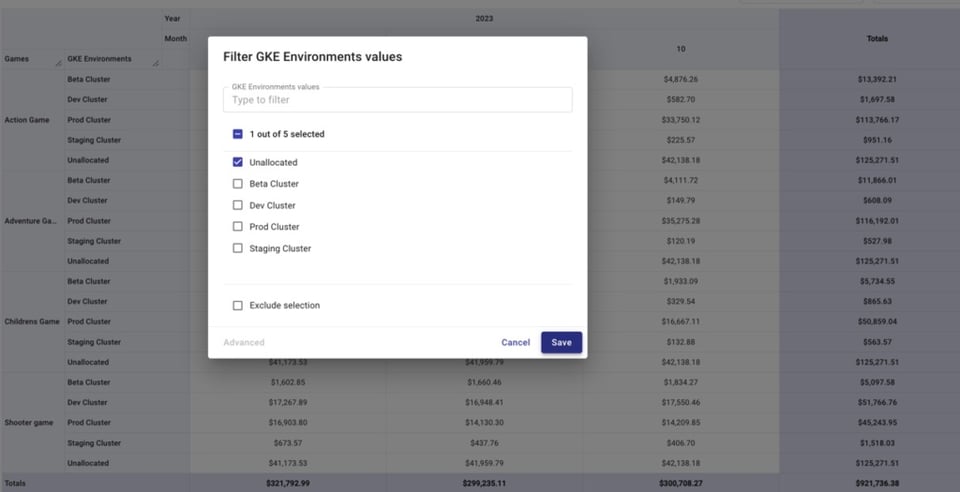
So lassen sich nicht gelabelte Ressourcen identifizieren, sofern sie zu Services gehören, deren Ressourcen sich labeln lassen, oder Projekte erkennen, die in einer Attribution einbezogen sein sollten, es aber nicht sind.
Unten sehen wir, dass es einige GCE-, GCS- und Cloud-SQL-Kosten gibt, die nicht in unseren Attribution Groups enthalten sind.
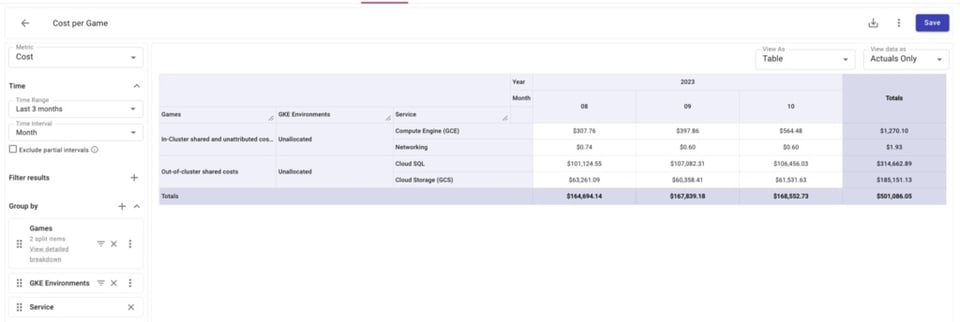
Beim genaueren Blick auf die nicht zugeordneten Compute-Engine-Ressourcen erkennen wir exakt, welche Ressourcen außen vor sind. Mit dieser Information können wir unsere Attribution(s) so überarbeiten, dass diese Ressourcen einbezogen werden.
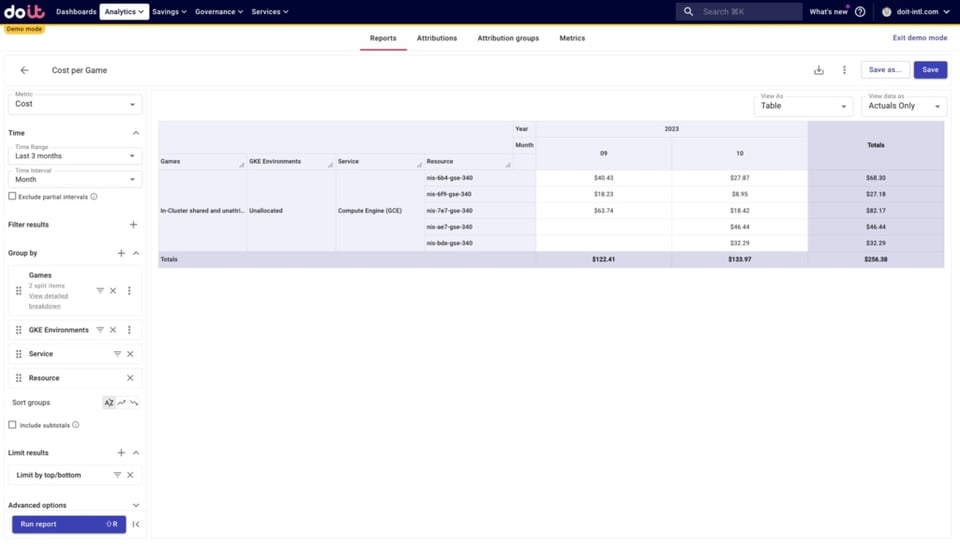
So senken Sie nicht zugeordnete Kosten und gewinnen mehr Transparenz über Ihre GKE-Ausgaben.
Fazit
Wer wissen wollte, wie sich Kubernetes-workloads auf die gesamte Cloud-Rechnung auswirken, musste bislang in der Regel auf Tools wie Cast AI oder Kubecost zurückgreifen.
Diese Produkte sind zwar leistungsfähiger als GKE Cost Allocation, doch Google Cloud nimmt unter den Hyperscalern eine Sonderstellung ein: Viele Funktionen für Kostentransparenz sind bereits eingebaut und lassen sich auf Ihren Clustern unkompliziert aktivieren.
Die von GKE Cost Allocation gelieferten Daten können Sie dann – wie oben gezeigt – nutzen, um mehr Transparenz über die Aufschlüsselung Ihrer Kosten zu gewinnen und konkretere Fragen zu Ihrer Cloud-Rechnung zu beantworten.
Sie sind bereits DoiT-Kunde und haben GKE Cost Allocation aktiviert? Dann erkunden Sie Ihre Daten gleich heute in DoiT Cloud Intelligence. Noch kein Kunde, aber neugierig auf unsere Produkte und Beratungsleistungen rund um K8s und darüber hinaus? Sprechen Sie uns an.