Entenda a alocação de custos do GKE e veja como usar seus dados com os recursos de alocação do DoiT Cloud Intelligence™ para ter uma visão granular do seu gasto com GKE.

O desafio de obter visibilidade de custos sobre o seu gasto com Kubernetes é tão antigo quanto o próprio Kubernetes.
A alocação dinâmica de recursos e o ciclo de vida curto dos containers dificultam atribuir custos a aplicações ou serviços específicos. Some-se a isso o fato de que os recursos são compartilhados entre vários componentes.
Mesmo assim, ter visibilidade de custos no Kubernetes é fundamental para uma boa gestão de recursos e de custos.
Para ajudar nesse cenário, no fim do ano passado o Google Cloud lançou a alocação de custos do GKE, que permite aos clientes ver o detalhamento dos custos do cluster.
Neste post, vamos falar sobre a alocação de custos do GKE e como usar esses dados em conjunto com os recursos de alocação do DoiT Cloud Intelligence para ter uma visão granular do seu gasto com GKE.
Mais especificamente, vamos mostrar como uma empresa hipotética de games organizaria seus custos de GKE de forma a mapeá-los para cada jogo, dividir os custos compartilhados entre eles e, depois, entender como o custo de cada jogo se distribui por ambiente.
O que é a alocação de custos do GKE
A alocação de custos do GKE é o método recomendado pelo Google Cloud para obter informações de billing do cluster. Comparada à sua antecessora, a medição de uso do GKE, fica muito mais fácil alocar custos de cluster por usuário com a GKE Cost Allocation, que ainda permite visualizar custos de cluster e de namespace lado a lado com os custos de outros serviços do Google Cloud — algo que a medição de uso não oferece. O Google Cloud também pretende substituir a GKE Usage Metering por ela no futuro.
Também é muito mais simples ativar a alocação de custos do GKE do que a medição de uso: basta um comando gcloud ou marcar uma caixa no Google Cloud Console para cada cluster. Depois de ativada, é criado um dataset no BQ com métricas de CPU, consumo de memória e discos dos workloads em execução nos clusters.
Isso facilita visualizar custos de cluster e de namespace — além de informações sobre recursos com GKE Labels associados a eles.
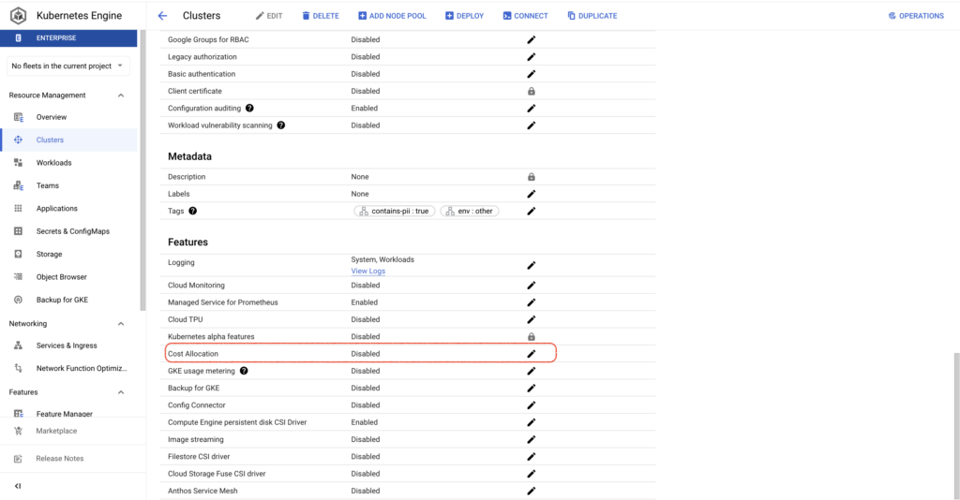
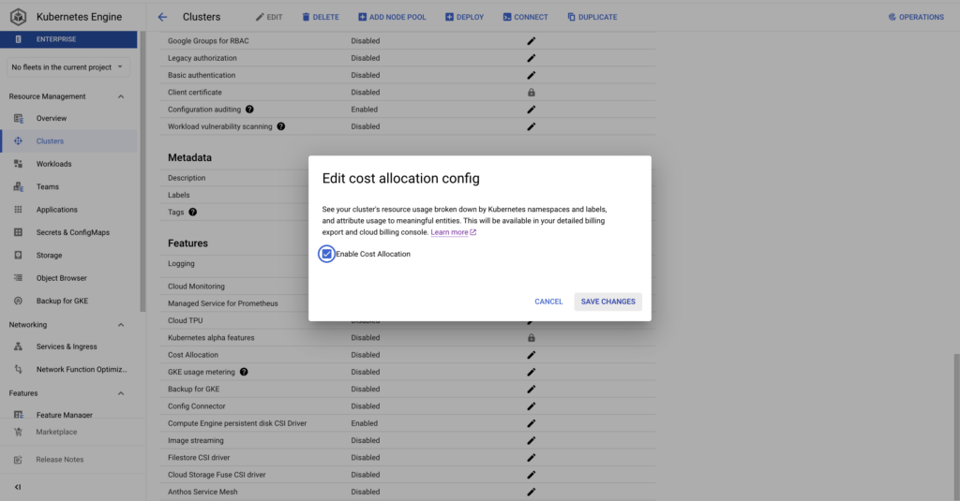
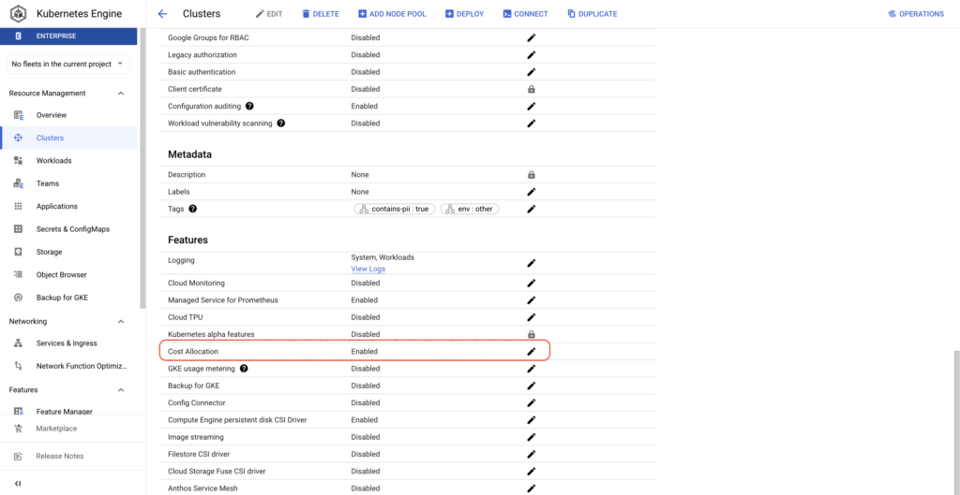
Com a alocação de custos do GKE ativada nos seus clusters, você consegue responder a perguntas como:
- Quanto dos custos do meu cluster vem de cada tenant?
- Como meus custos fora do cluster (CloudSQL, GCS etc.) se relacionam com os custos dentro do cluster?
- Quanto custa minha aplicação de backend?
Por fim, depois de ativadas, as informações granulares de billing dos custos de cluster e namespace também passam a fluir para o DoiT Cloud Intelligence, permitindo alocações de custos mais sofisticadas. Vamos ver um cenário de exemplo na próxima seção.

Mapeando os custos do GKE para os agrupamentos do seu negócio
O primeiro passo da alocação de custos é definir os agrupamentos de negócio para os quais você quer alocá-los. No DoiT Cloud Intelligence, isso é feito por meio das Attributions. Elas ajudam a agrupar recursos de nuvem e organizar os custos de uma forma que reflita como você quer alocá-los.
Imagine que somos uma empresa hipotética de games, com vários jogos disponíveis para os usuários.
Podemos querer alocar recursos para cada jogo e também para os diferentes ambientes em que esses jogos rodam.
Abaixo, definimos os custos de GKE relacionados a um dos nossos jogos — um jogo de ação — como qualquer namespace que contenha a palavra "action". Usar regex para isso permite capturar os custos de qualquer novo namespace ligado ao jogo de ação que venha a ser criado, sem precisar atualizar a Attribution na mão.
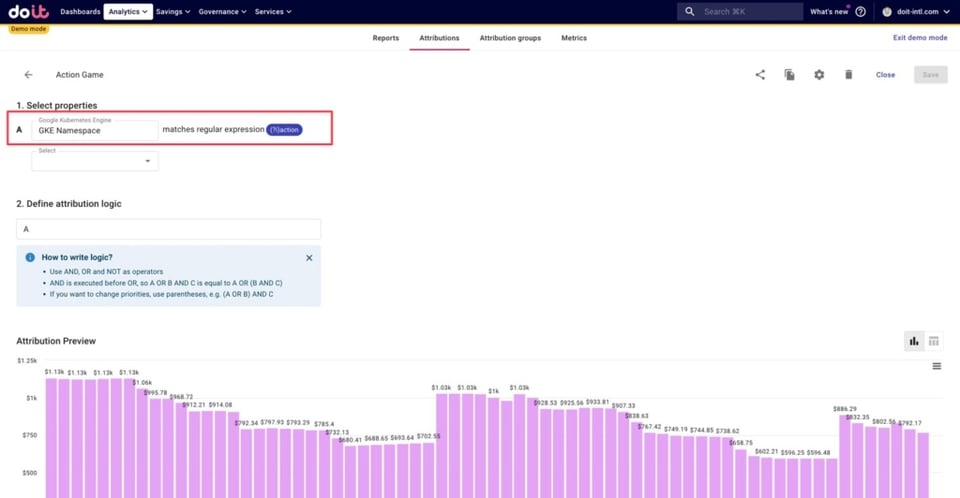
Além disso, definimos clusters de produção e também de dev, staging e beta. Veja abaixo um exemplo de como definir os clusters de produção, usando regex para capturar todos os clusters com a palavra "prod" no nome.
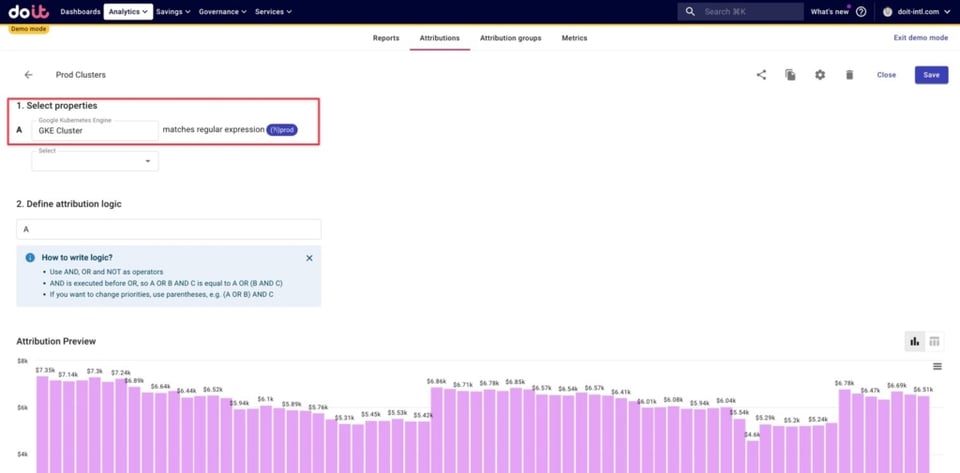
Organizando nossos agrupamentos de negócio
O próximo passo é organizar Attributions relacionadas em Attribution Groups. Esses grupos permitem dividir custos compartilhados entre um conjunto de Attributions e também detalhar um conjunto de Attributions a partir de outro. Faremos as duas coisas a seguir.
Abaixo, criamos um Attribution Group chamado "Games" com Attributions que representam:
- Quatro jogos operados pela nossa empresa hipotética
- Custos compartilhados dentro do cluster e custos não atribuídos, incluindo:
- kube:system e kube:system-overhead: componentes/namespaces de sistema do K8s. (kube-system é o namespace, e o Google gera essa métrica adicional para representar o overhead)
- kube:unallocated: recursos que não foram requisitados pelos workloads nem para overhead de sistema.
- goog-k8s-unknown: basicamente um erro da alocação de custos quando uma nova VM do Compute sobe ou o cluster faz scale up (não foi possível processar o SKU)
- goog-k8s-unsupported-sku — SKU existente, mas não suportado (ex.: instâncias E2)
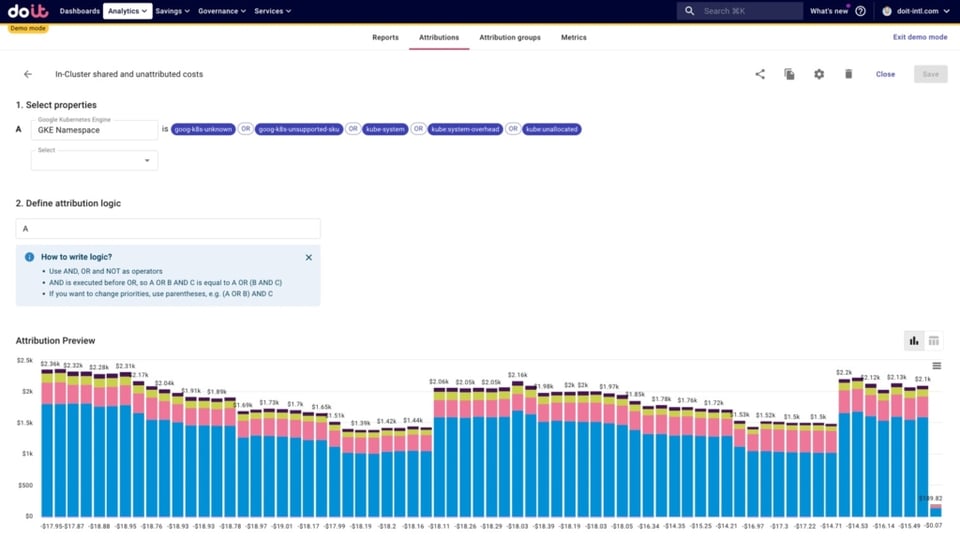
- Custos compartilhados fora do cluster: custos de recursos que não são Kubernetes, mas que rodam no Google Cloud fora do Kubernetes e são consumidos pelas apps implantadas no cluster
- bancos de dados como Cloud SQL ou BigQuery
- armazenamento de objetos como Google Cloud Storage
- filas de mensagens como Pub/Sub, Kafka etc.
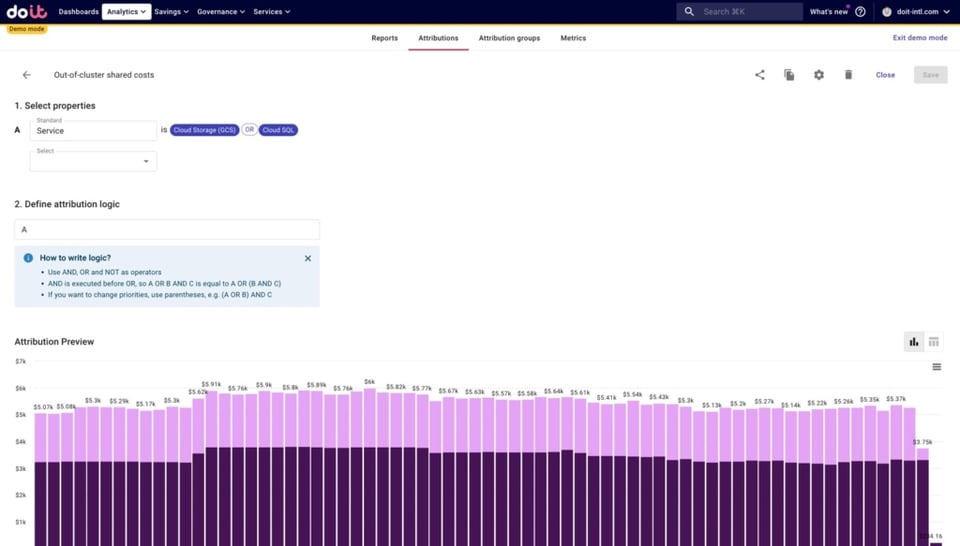
- Tudo o que não tiver sido capturado pelas Attributions acima
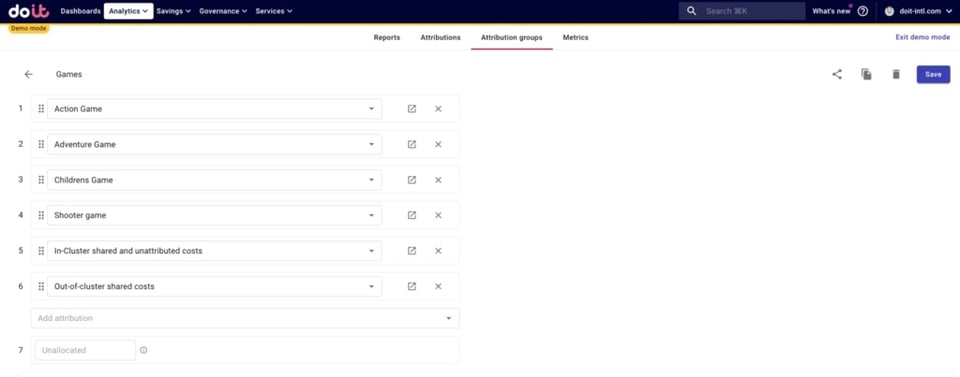
Incluímos as Attributions que não são de jogos porque são custos compartilhados que vamos querer dividir entre os jogos na próxima seção.
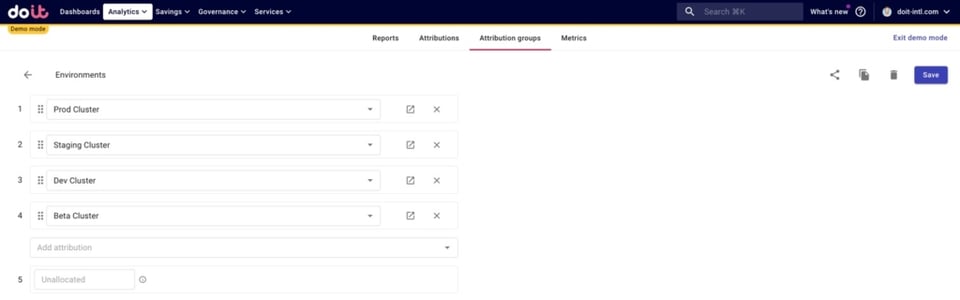
Da mesma forma, criamos um Attribution Group para todos os nossos ambientes.
Fazemos isso porque, depois de dividir os custos compartilhados entre os jogos, vamos querer saber quanto está sendo gasto em cada ambiente para cada jogo.
Dividindo custos compartilhados dentro e fora do cluster
Primeiro, vamos rodar um relatório para analisar nosso Attribution Group com os custos dos jogos e os custos compartilhados.
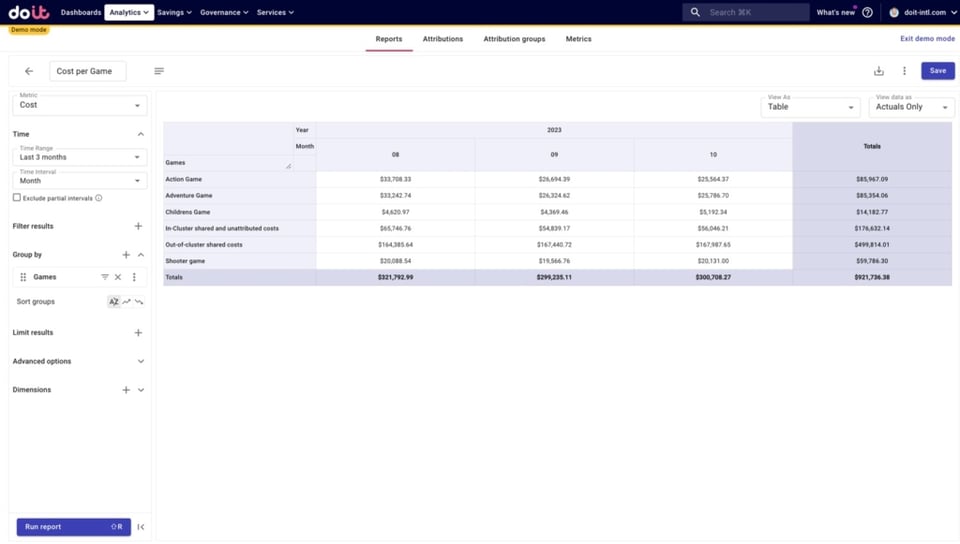
Para isso, seguimos os passos abaixo:
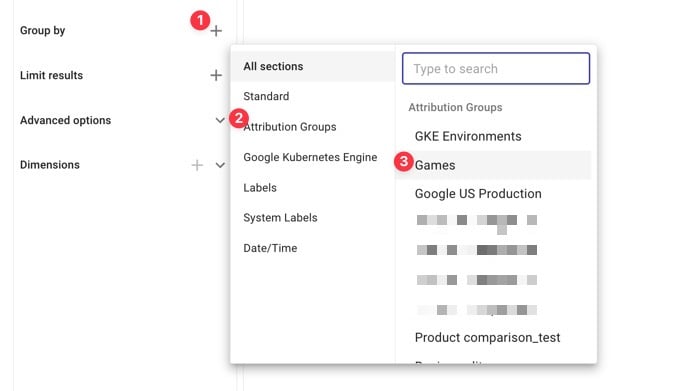
Em seguida, vamos dividir os dois custos compartilhados — custos compartilhados e não atribuídos dentro do cluster e custos compartilhados fora do cluster — entre os jogos.
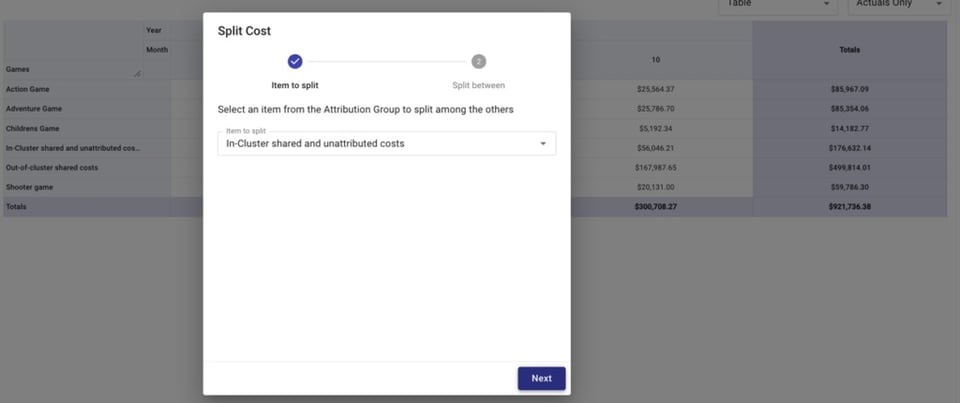
É possível dividir esses custos igualmente, de forma proporcional ao gasto de cada jogo em relação ao gasto total ou por um valor personalizado.
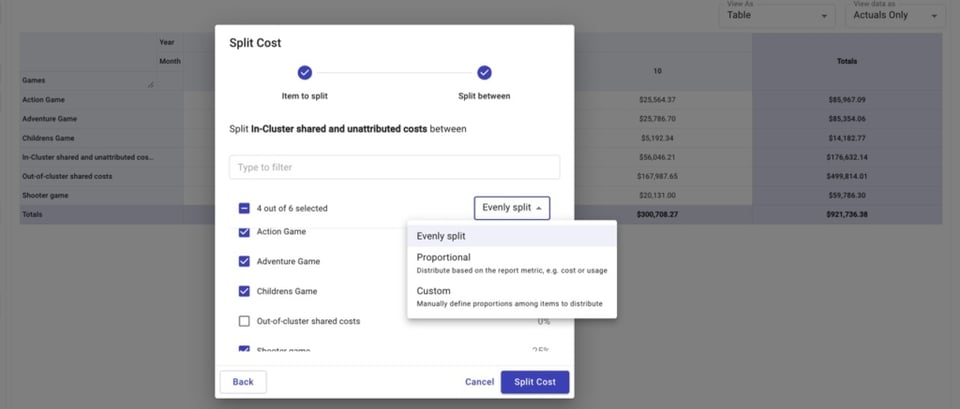
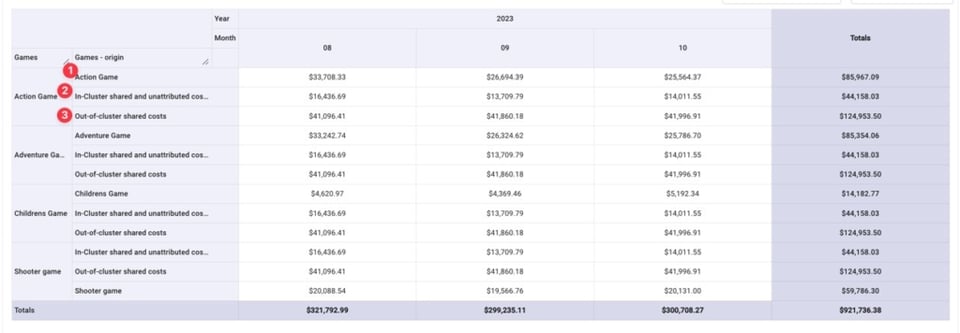
Depois disso, conseguimos ver, para cada jogo:
- O custo de operar aquele jogo
- A parcela que cabe a ele dos custos compartilhados/não atribuídos dentro do cluster
- A parcela que cabe a ele dos custos compartilhados fora do cluster
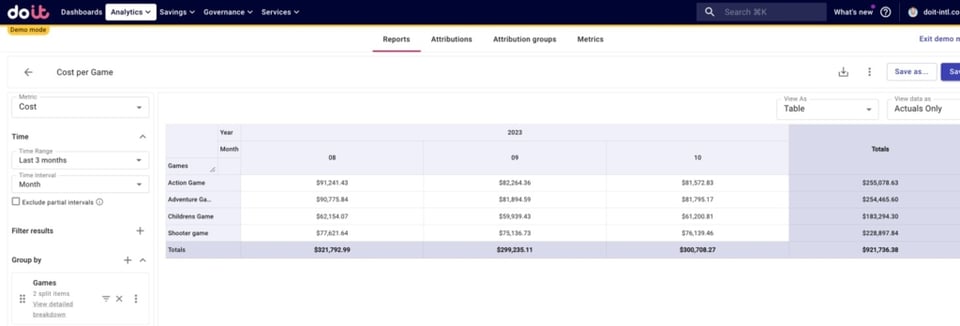
Para simplificar, vamos agregar essas três linhas no custo de cada jogo.
Detalhando o custo dos jogos por ambiente
Agora podemos descobrir como o custo total de cada jogo se distribui por ambiente, adicionando o Attribution Group "GKE Environments" ao detalhamento.
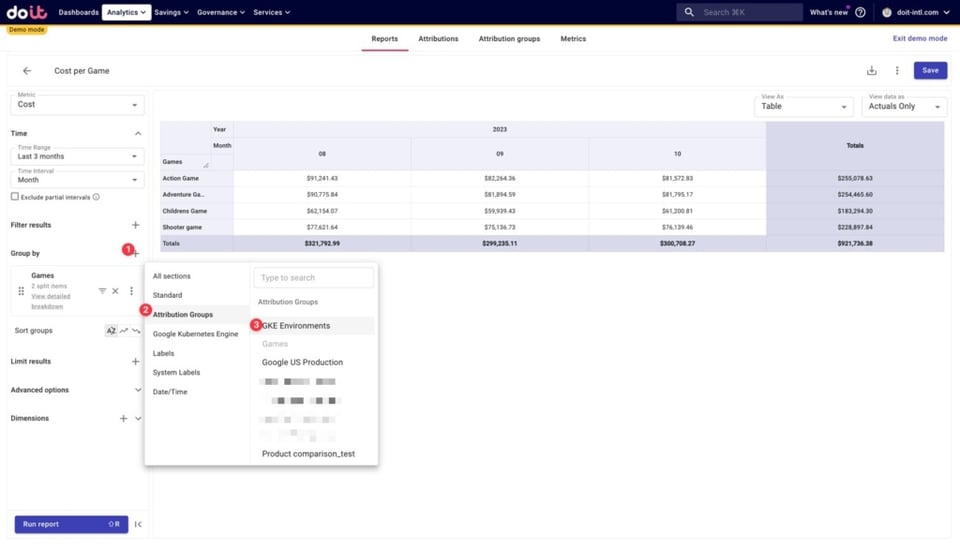
Abaixo, vemos como os custos de cada jogo se dividem entre as attributions de ambiente que criamos antes, somados aos eventuais custos não alocados. Esses custos não alocados são recursos que não foram capturados em nenhuma das Attributions dos Attribution Groups que estamos usando aqui.
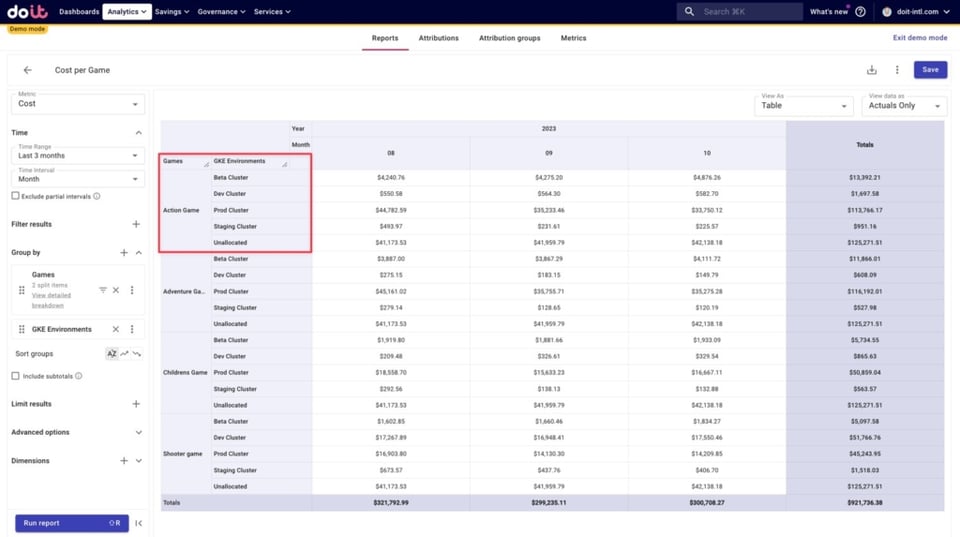
Podemos investigar os custos não alocados para descobrir o que está por trás deles e, se for o caso, ajustar Attributions existentes para incluir esses recursos.
Vamos filtrar apenas os custos não alocados no Attribution Group "GKE Environments" abaixo e adicionar "Service" ao detalhamento.
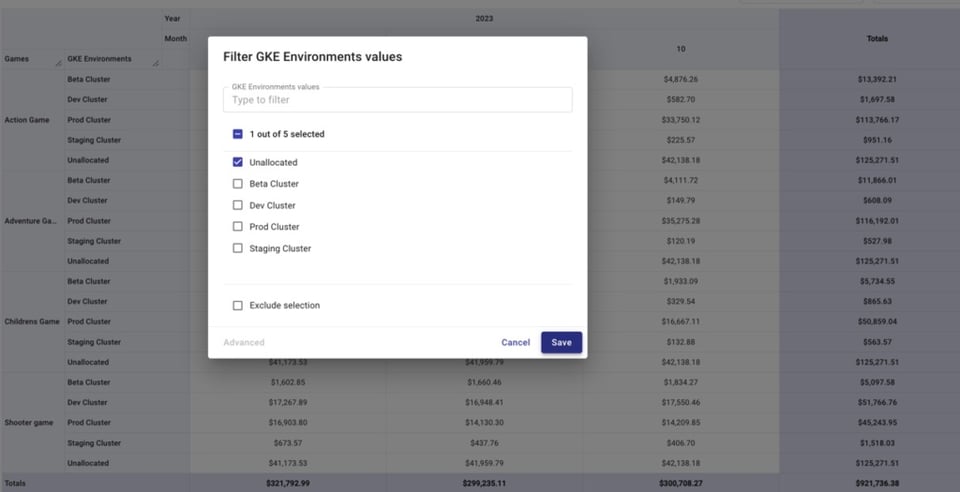
Isso ajuda a identificar recursos sem labels que pertençam a serviços que aceitam labels, ou projetos que deveriam estar incluídos em alguma Attribution e não estão.
Abaixo, dá para ver que existem alguns custos de GCE, GCS e Cloud SQL que não estão entrando nos nossos Attribution Groups.
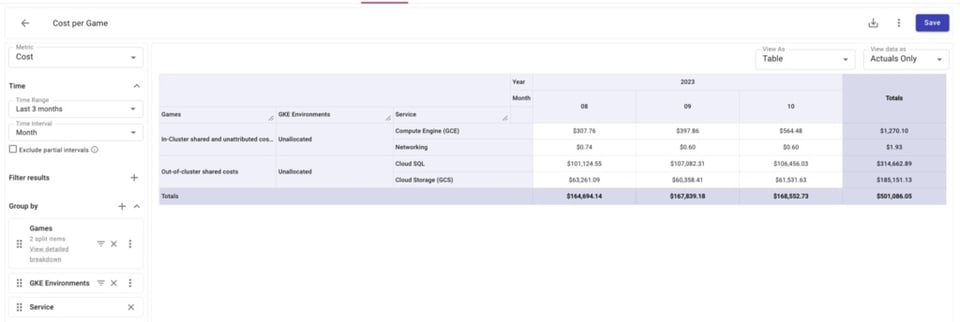
E, ao olhar de perto os recursos não alocados do Compute Engine, conseguimos identificar exatamente quais não estão sendo incluídos. Com essa informação, podemos revisar nossas Attributions para incluí-los.
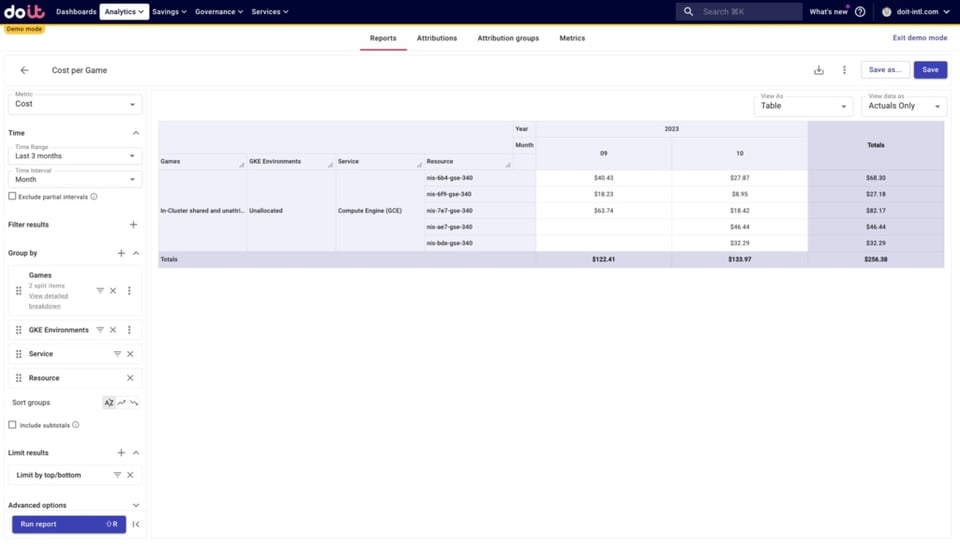
É assim que dá para reduzir os custos não alocados e aumentar a visibilidade sobre o seu gasto com GKE.
Conclusão
Normalmente, para entender como seus workloads em Kubernetes impactam a conta total da nuvem, você precisaria recorrer a ferramentas como o Cast AI ou o Kubecost.
Esses produtos são mais robustos do que a alocação de custos do GKE, mas o Google Cloud se destaca entre os hyperscalers por já trazer boa parte da visibilidade de custos embutida e fácil de ativar nos clusters.
Você pode usar os dados da alocação de custos do GKE, como fizemos aqui, para ganhar mais transparência sobre como seus custos se distribuem e responder a perguntas mais específicas sobre a conta da nuvem.
Se você já é cliente DoiT e tem a alocação de custos do GKE ativada, comece a explorar seus dados no DoiT Cloud Intelligence hoje mesmo. Se ainda não é cliente, mas quer saber mais sobre nossos produtos e serviços de consultoria em Kubernetes e além, fale com a gente.